Реализация алгоритмов кодирования сигнала на языке Python
Ниже представлена реализация различных алгоритмов кодирования сигнала на ЯП Python. Кодирование сигнала применяется для различных задач. Некоторые их них: синхронизация приемника и передатчика для предоствращения вставок и выпадений битов (NRZI, манчестерское кодирование), сжатие размера сигнала (алгоритм Хаффмана), исправление ошибок в принятом сигнале, которые возникли при передаче сигнала через зашумленный канал (Хэмминг, кодирование Рида-Соломона).
Важно отметить, что данная реализация плохо подходит для реальных систем (очень неэффективна из-за представления сигнала типом данных str), а нужна лишь для демонстрации и анализа работы алгоритомов и их способностей без учета накладных расходов памяти отдельного языка программирования.
Также целью было сфокусироваться на ошибках замещения (инверсиях битов) и проблемах синхронизации, решаемых линейными кодами. Более сложный тип ошибок — вставки и выпадения битов — в этой работе не рассматривается. Их обнаружение и коррекция требуют других подходов, часто реализуемых на более высоких уровнях протоколов (например, с помощью кадрирования и синхромаркеров) или с использованием специализированных кодов, что выходит за рамки данного демонстрационного ноутбука. Представленные здесь помехоустойчивые коды (Хэмминг, Рид-Соломон) в их базовой форме предназначены для борьбы именно с ошибками замещения в синхронизированном потоке данных.
Делаем необходимые импорты
# При первом запуске необходимо раскомментировать магический метод ниже для установки сторонней
# библиотеки, затем эту строку можно удалить
#!pip install galois
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
import heapq
from collections import Counter
import math
import galois
Модели идеального АЦП и ЦАП. Позволяют симулировать процесс преобразования аналогового сигнала, который представлен как числовое значение напряжения в цифровой код и обратно. Функции работают с сигналами в диапазоне от (-Vref до +Vref) и позволяют настраивать разрядность (bits) и опороное напряжение (Vref). АЦП включает защиту от перегрузок, ограничивая входной сигнал вышеуказанным диапазоном перед квантованием.
def adc_converter(analog_signal, bits=8, v_ref=1.0):
"""
Универсальный АЦП с обработкой сигналов любой амплитуды
:param analog_signal: входной сигнал в вольтах
:param bits: разрядность АЦП (8-16 бит)
:param v_ref: опорное напряжение (±V)
:return: (quantized, binary) - кортеж с результатами
"""
# 1. Нормализация сигнала с защитой от перегрузок
normalized = np.clip((analog_signal + v_ref) / (2 * v_ref), 0, 1)
# 2. Квантование
max_level = 2 ** bits - 1
quantized = np.round(normalized * max_level).astype(int)
# 4. Бинарное представление
binary = [format(x, f'0{bits}b') for x in quantized]
return quantized, binary
def dac_converter(quantized, bits=8, v_ref=1.0):
"""Цифро-аналоговый преобразователь"""
max_level = 2 ** bits - 1
analog_reconstructed = (quantized / max_level) * 2 * v_ref - v_ref
return analog_reconstructed
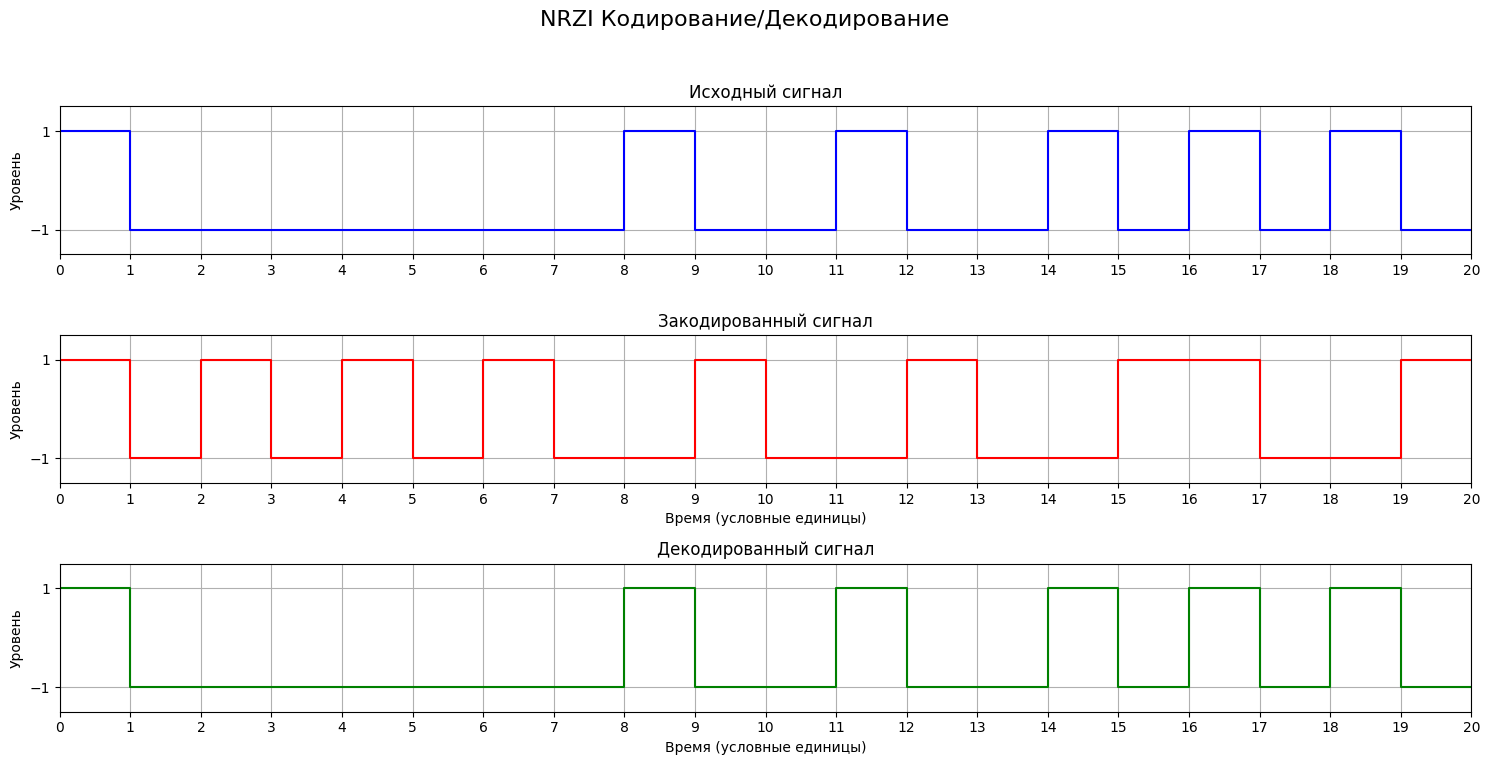
Для реализации линейного кодирования NRZI (Non-Return-to-Zero Inverted) были разработаны две функции: nrzi_encode и nrzi_decode. Эти функции обеспечивают преобразование бинарной последовательности в соответствующий NRZI-сигнал и обратное декодирование.
Функция nrzi_encode принимает на вход строку битов и начальный уровень сигнала ('0' или '1'). Она последовательно обрабатывает каждый бит входной строки. Если текущий бит равен '0', функция инвертирует текущий уровень сигнала (меняет '0' на '1' или '1' на '0'). Если же текущий бит равен '1', уровень сигнала остается неизменным. Результатом работы функции является строка, представляющая последовательность уровней NRZI-сигнала, имеющая ту же длину, что и исходная бинарная строка.
Функция nrzi_decode выполняет обратную операцию. Она получает строку NRZI-уровней и начальный уровень, который предшествовал первому уровню в переданной строке (этот начальный уровень должен совпадать с тем, который использовался при кодировании). Функция сравнивает каждый текущий уровень с предыдущим. Если уровень изменился, это соответствует декодированному биту '0'. Если уровень остался прежним, это соответствует декодированному биту '1'. Предыдущий уровень обновляется на каждой итерации. На выходе функция возвращает восстановленную исходную бинарную строку. Обе функции также включают обработку пустых входных строк.
def nrzi_encode(binary_signal, initial_level='1'):
"""
Кодирует одну непрерывную битовую строку в NRZI.
В NRZI (Non-Return-to-Zero Inverted):
- '0' в исходном сигнале вызывает переход/инверсию уровня.
- '1' в исходном сигнале означает сохранение текущего уровня.
Аргументы:
binary_signal (str): Входная строка из '0' и '1' (например, '10110010').
initial_level (str): Начальный уровень сигнала ('0' или '1'). По умолчанию '1'.
Возвращает:
str: Строка с NRZI-кодированными уровнями такой же длины, что и входная.
Например, для '1011001' и initial_level='1', результат будет '1000100'.
(1->1, 0->0, 1->0, 1->0, 0->1, 0->0, 1->0)
"""
if not binary_signal: # Обработка пустого ввода
return ""
# Убедимся, что начальный уровень - один из допустимых ('0' или '1')
# Можно добавить более строгую проверку, если нужно
current_level = str(initial_level) if initial_level in ('0', '1') else '1'
encoded_levels = []
for bit in binary_signal:
if bit == '0':
# Инвертируем уровень при встрече '0'
current_level = '0' if current_level == '1' else '1'
# Если bit == '1', уровень не меняется, просто используем текущий
encoded_levels.append(current_level)
return ''.join(encoded_levels)
def nrzi_decode(encoded_signal, initial_level='1'):
"""
Декодирует одну непрерывную NRZI-кодированную строку обратно в биты.
В NRZI:
- Переход уровня ('0' -> '1' или '1' -> '0') соответствует биту '0'.
- Сохранение уровня ('0' -> '0' или '1' -> '1') соответствует биту '1'.
Аргументы:
encoded_signal (str): Входная строка NRZI-уровней (например, '1000100').
initial_level (str): Начальный уровень, который был *перед* первым битом
закодированного сигнала ('0' или '1'). Должен
совпадать с использованным при кодировании.
По умолчанию '1'.
Возвращает:
str: Декодированная битовая строка (например, '1011001').
"""
if not encoded_signal: # Обработка пустого ввода
return ""
# Уровень *перед* началом обработки первого бита
previous_level = str(initial_level) if initial_level in ('0', '1') else '1'
decoded_bits = []
for current_level in encoded_signal:
# Проверяем, изменился ли уровень по сравнению с предыдущим
if current_level != previous_level:
decoded_bits.append('0') # Переход уровня = '0'
else:
decoded_bits.append('1') # Уровень не изменился = '1'
# Обновляем предыдущий уровень для следующей итерации
previous_level = current_level
return ''.join(decoded_bits)
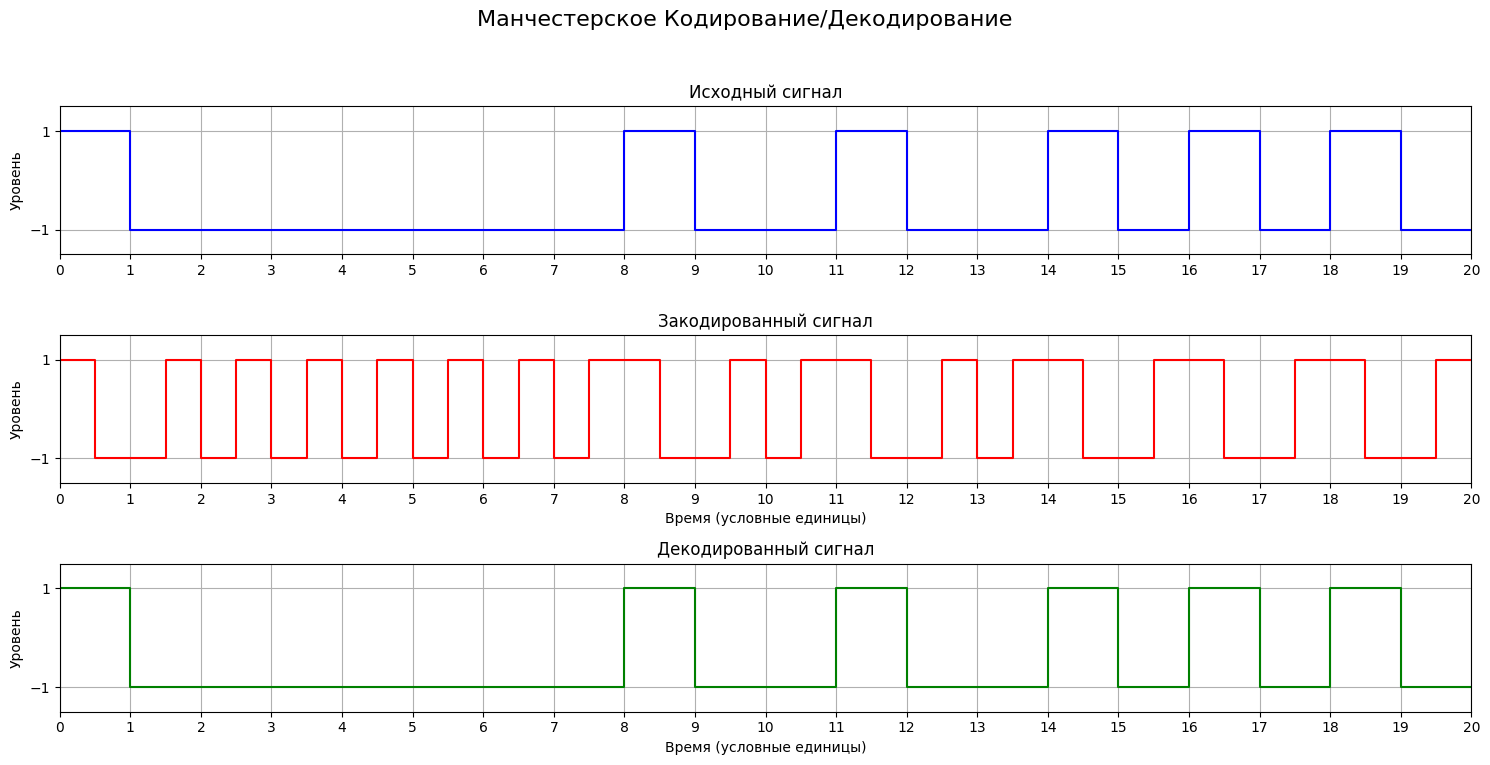
Для реализации манчестерского кодирования и декодирования используются функции manchester_encode и manchester_decode, оптимизированные для работы с предположительно корректными строковыми сигналами.
Функция manchester_encode принимает бинарную строку, содержащую только символы '0' и '1'. Она последовательно преобразует каждый входной бит: '0' заменяется на двухбитовую последовательность '01', а '1' - на '10'. Функция не выполняет проверок на наличие невалидных символов во входной строке, полагаясь на корректность передаваемых данных. Результатом является строка манчестерского кода, имеющая удвоенную длину по сравнению с исходной.
Функция manchester_decode выполняет обратное преобразование. Она принимает строку, представляющую манчестерский код, и предполагает, что эта строка имеет четную длину и состоит исключительно из корректных пар '01' и '10'. Функция обрабатывает входную строку парами битов: пара '01' декодируется в '0', а любая другая пара (подразумевается, что это '10') декодируется в '1'. Проверки на нечетную длину или наличие некорректных пар ('00', '11') не производятся для повышения производительности при работе с заведомо правильными данными. На выходе возвращается исходная бинарная последовательность.
def manchester_encode(binary_signal):
"""
Кодирует одну непрерывную битовую строку по алгоритму Манчестера.
Предполагается, что входная строка содержит только '0' и '1'.
Каждый бит преобразуется:
'0' -> '01'
'1' -> '10'
Аргументы:
binary_signal (str): Входная строка из '0' и '1'.
Возвращает:
str: Строка с Манчестер-кодированными уровнями.
"""
if not binary_signal:
return ""
encoded_bits = []
for bit in binary_signal:
if bit == '0':
encoded_bits.append('01')
else: # Предполагается, что если не '0', то это '1'
encoded_bits.append('10')
return ''.join(encoded_bits)
def manchester_decode(manchester_encoded_signal):
"""
Декодирует одну непрерывную строку из Манчестерского кода.
Предполагается, что входная строка имеет четную длину и
состоит только из корректных пар ('01' или '10').
Преобразование пар:
'01' -> '0'
'10' -> '1'
Аргументы:
manchester_encoded_signal (str): Входная строка с Манчестер-кодом
(например, '1001101001'),
предположительно корректная.
Возвращает:
str: Декодированная битовая строка (например, '10110').
"""
if not manchester_encoded_signal:
return ""
decoded_bits = []
# Итерируем по парам символов, предполагая четную длину
for i in range(0, len(manchester_encoded_signal), 2):
pair = manchester_encoded_signal[i:i+2]
if pair == '01':
decoded_bits.append('0')
else: # Предполагается, что если не '01', то это '10'
decoded_bits.append('1')
return ''.join(decoded_bits)
Реализация алгоритма Хаффмана для сжатия данных через переменнодлинное кодирование. Он представлен в виде класса Huffman с двумя статическими методами: encode для кодирования и decode для декодирования.
Метод encode принимает на вход сигнал вида ['10110101','10011101, ...]. Первым шагом он анализирует частоту появления каждого уникального символа в сигнале, используя collections.Counter. Затем на основе этих частот создается приоритетная очередь (мин-куча) с помощью heapq. Каждый элемент кучи изначально представляет собой листовой узел будущего дерева Хаффмана и содержит частоту символа, сам символ и пустую строку для будущего бинарного кода. Далее начинается процесс построения дерева: цикл продолжается, пока в куче остается больше одного элемента. В каждой итерации из кучи извлекаются два узла с наименьшими частотами. Символам, принадлежащим левому поддереву (извлеченному первым), к их текущим кодам дописывается префикс '0', а символам правого поддерева — префикс '1'. Затем создается новый узел, объединяющий эти два подузла: его частота равна сумме частот дочерних узлов, а список символов и их кодов является объединением списков дочерних узлов (с уже добавленными префиксами). Этот новый узел добавляется обратно в кучу. По завершении цикла в куче остается единственный элемент — корень построенного дерева Хаффмана, содержащий все символы и их окончательные бинарные коды. Из этого корневого узла извлекается словарь кодов (codebook), сопоставляющий каждому символу его уникальный бинарный код Хаффмана. На последнем этапе исходный сигнал преобразуется в закодированный вид: каждый символ заменяется соответствующим ему бинарным кодом из словаря. Метод возвращает список этих бинарных строк и сам словарь кодов.
Метод decode выполняет обратную операцию — восстановление исходного сигнала из закодированной последовательности и словаря кодов. Сначала он инвертирует словарь кодов, чтобы можно было легко находить символ по его бинарному коду. Затем список отдельных бинарных строк, полученных от encode, объединяется в единый непрерывный поток битов. Метод последовательно читает биты из этого потока, накапливая их во временную строку. После добавления каждого бита проверяется, соответствует ли накопленная строка какому-либо коду в инвертированном словаре. Если соответствие найдено, то символ, соответствующий этому коду, добавляется к результату декодирования, а временная строка для накопления сбрасывается. Этот процесс повторяется до тех пор, пока весь битовый поток не будет обработан. В результате метод возвращает список декодированных символов, который должен в точности совпадать с исходным сигналом.
class Huffman:
@staticmethod
def encode(signal):
"""Кодирование сигнала с использованием переменнодлинных кодов Хаффмана."""
# 1. Строим частотный словарь
freq = Counter(signal)
# 2. Создаем узлы для кучи (символ, частота, битовая строка)
heap = [[weight, [symbol, ""]] for symbol, weight in freq.items()]
heapq.heapify(heap)
# 3. Строим дерево Хаффмана
while len(heap) > 1:
lo = heapq.heappop(heap)
hi = heapq.heappop(heap)
# Добавляем '0' ко всем кодам левого поддерева
for pair in lo[1:]:
pair[1] = '0' + pair[1]
# Добавляем '1' ко всем кодам правого поддерева
for pair in hi[1:]:
pair[1] = '1' + pair[1]
heapq.heappush(heap, [lo[0] + hi[0]] + lo[1:] + hi[1:])
# 4. Извлекаем коды (без дополнения нулями!)
codes = {sym: bits for sym, bits in heap[0][1:]}
# 5. Кодируем сигнал
encoded = [codes[sym] for sym in signal]
return encoded, codes
@staticmethod
def decode(encoded, codes):
"""Декодирование переменнодлинных кодов Хаффмана."""
# Инвертируем таблицу кодов: битовая строка → символ
inv_codes = {v: k for k, v in codes.items()}
# Собираем битовую последовательность и декодируем
bit_stream = "".join(encoded)
decoded = []
current_code = ""
for bit in bit_stream:
current_code += bit
if current_code in inv_codes:
decoded.append(inv_codes[current_code])
current_code = ""
return decoded
Реализация классического алгоритма помехоустойчивого кодирования Хэмминга для схемы (7,4), способной обнаруживать до двух и исправлять одну ошибку в блоке. Код состоит из двух основных функций: hamming_encode для кодирования и hamming_decode для декодирования с коррекцией ошибок.
Функция hamming_encode принимает на вход строку двоичных данных. Прежде всего, она гарантирует, что длина входной строки кратна 4 (количество информационных битов в блоке Hamming(7,4)), добавляя при необходимости нулевые биты в конец строки. Исходная длина данных сохраняется для последующего использования при декодировании. Затем данные обрабатываются последовательными 4-битными фрагментами. Для каждого такого фрагмента вычисляются три проверочных бита четности (p1, p2, p3, где p3 соответствует стандартному p4) на основе определенных комбинаций информационных битов с использованием операции XOR. Эти проверочные биты вместе с исходными четырьмя информационными битами формируют 7-битный кодовый блок. Биты в блоке располагаются в стандартном для кода Хэмминга порядке, где проверочные биты занимают позиции, соответствующие степеням двойки (1, 2, 4), а информационные биты — остальные позиции (3, 5, 6, 7). Закодированные 7-битные блоки объединяются в одну выходную строку. Функция возвращает эту закодированную строку и исходную длину данных.
Функция hamming_decode выполняет обратную операцию, принимая закодированную строку и ее исходную длину до кодирования. Она также обрабатывает данные 7-битными блоками. Для каждого блока вычисляются три так синдромных бита (s1, s2, s3). Каждый синдромный бит получается путем проверки четности (XOR-суммирования) определенной группы битов внутри принятого блока, включая как информационные, так и проверочные биты, согласно правилам кода Хэмминга. Если все проверки четности проходят успешно, все синдромные биты равны нулю, что указывает на отсутствие обнаруженных ошибок в блоке. Если же хотя бы один синдромный бит не равен нулю, это сигнализирует об ошибке. Значение синдрома, рассматриваемое как двоичное число (s3s2s1), напрямую указывает на позицию (от 1 до 7) ошибочного бита в блоке. Обнаружив ненулевой синдром, функция определяет позицию ошибки и инвертирует бит в этой позиции, исправляя тем самым одиночную ошибку. Код также подсчитывает количество выполненных исправлений. После возможной коррекции из 7-битного блока извлекаются исходные 4 информационных бита, расположенные на предопределенных позициях. Эти извлеченные биты из всех блоков собираются вместе. Наконец, результирующая строка обрезается до сохраненной исходной длины, чтобы удалить возможное дополнение, добавленное на этапе кодирования. Функция возвращает декодированную (и потенциально исправленную) строку данных и общее число исправленных ошибок.
# --- Параметры Hamming(7,4) ---
DATA_BITS = 4
PARITY_BITS = 3
BLOCK_SIZE = 7 # DATA_BITS + PARITY_BITS
# --- Функция кодирования Hamming(7,4) ---
def hamming_encode(data_str):
"""
Кодирует строку двоичных данных с использованием кода Hamming(7,4).
Дополняет данные нулями до длины, кратной DATA_BITS.
Возвращает закодированную строку и исходную длину данных.
"""
original_length = len(data_str)
# Дополнение нулями до длины, кратной DATA_BITS
remainder = len(data_str) % DATA_BITS
if remainder != 0:
padding = '0' * (DATA_BITS - remainder)
data_str = data_str + padding
encoded_str = ""
for i in range(0, len(data_str), DATA_BITS):
chunk = data_str[i:i + DATA_BITS]
d = [int(bit) for bit in chunk] # d1, d2, d3, d4
# Расчет проверочных битов (для четности)
p1 = d[0] ^ d[1] ^ d[3] # Позиции 3, 5, 7 (d1, d2, d4)
p2 = d[0] ^ d[2] ^ d[3] # Позиции 3, 6, 7 (d1, d3, d4)
p3 = d[1] ^ d[2] ^ d[3] # Позиции 5, 6, 7 (d2, d3, d4)
# Формирование блока (p1, p2, d1, p3, d2, d3, d4)
block = [p1, p2, d[0], p3, d[1], d[2], d[3]]
encoded_str += "".join(map(str, block))
return encoded_str, original_length
# --- Функция декодирования Hamming(7,4) ---
def hamming_decode(encoded_str, original_length):
"""
Декодирует строку, закодированную Hamming(7,4), исправляя одиночные ошибки.
Обрезает результат до original_length.
Возвращает декодированную строку и количество исправленных ошибок.
"""
if len(encoded_str) % BLOCK_SIZE != 0:
# Обычно это не должно происходить, если строка получена от hamming_encode. Если произошло, то случилась либо вставка либо выпадение битов
raise ValueError(f"Длина закодированной строки ({len(encoded_str)}) не кратна размеру блока ({BLOCK_SIZE})")
decoded_str = ""
corrected_errors = 0
for i in range(0, len(encoded_str), BLOCK_SIZE):
chunk = encoded_str[i:i + BLOCK_SIZE]
r = [int(bit) for bit in chunk] # r1, r2, r3, r4, r5, r6, r7
# Расчет синдромов
s1 = r[0] ^ r[2] ^ r[4] ^ r[6] # Позиции 1, 3, 5, 7
s2 = r[1] ^ r[2] ^ r[5] ^ r[6] # Позиции 2, 3, 6, 7
s3 = r[3] ^ r[4] ^ r[5] ^ r[6] # Позиции 4, 5, 6, 7
syndrome = s3 * 4 + s2 * 2 + s1 * 1
corrected_block = list(r) # Копируем блок для возможного исправления
if syndrome != 0:
error_pos = syndrome - 1 # Позиция ошибки (индекс от 0 до 6)
if error_pos < len(corrected_block):
corrected_block[error_pos] = 1 - corrected_block[error_pos] # Инвертируем бит
corrected_errors += 1
else:
# Это может произойти при >1 ошибки, синдром указывает на несущ. позицию
print(
f"Предупреждение: Синдром {syndrome} указывает на неверную позицию > {BLOCK_SIZE} в блоке {chunk}. Возможно, >1 ошибки.")
# Извлечение данных из (возможно) исправленного блока
# Позиции 3, 5, 6, 7 -> индексы 2, 4, 5, 6
data_bits = [corrected_block[2], corrected_block[4], corrected_block[5], corrected_block[6]]
decoded_str += "".join(map(str, data_bits))
# Обрезаем до исходной длины
return decoded_str[:original_length], corrected_errors
Реализация помехоустойчивого кодирования и декодирования данных с использованием кодов Рида-Соломона (RS), опираясь на возможности библиотеки galois. В начале скрипта задаются ключевые параметры: размер символа m установлен в 8 бит, что соответствует работе с байтами, и определяется поле Галуа GF(2^8) с использованием стандартного неприводимого полинома. Затем указываются параметры конкретного кода RS(n, k): k=11 информационных символов (байт) и n=15 символов в полном кодовом слове, что обеспечивает избыточность для исправления ошибок. Исходя из этих параметров, вычисляется исправляющая способность t, равная двум символьным (байтовым) ошибкам на блок. Создается основной объект rs класса galois.ReedSolomon, который инкапсулирует логику кодирования и декодирования для выбранных параметров; процесс создания обернут в блок try-except для отлова возможных ошибок конфигурации.
Функция segment_and_encode предназначена для кодирования потенциально длинной бинарной строки. Она принимает эту строку и объект RS-кодера. Сначала функция определяет размер информационного блока в битах (k * 8) и сохраняет исходную длину входной строки. Затем она вычисляет необходимое количество нулевых битов для дополнения строки так, чтобы её общая длина стала кратной размеру информационного блока, и выполняет это дополнение. Подготовленная строка разбивается на последовательные информационные чанки размером k байт. Каждый такой чанк преобразуется из бинарного представления в список k целых чисел (байтов), затем этот список представляется как вектор над полем Галуа GF(2^8). Этот вектор сообщения подается на вход методу encode объекта rs_coder, который возвращает кодовое слово — вектор из n символов поля Галуа. Полученное кодовое слово преобразуется обратно в список n целых чисел (байтов) и добавляется к общему списку закодированных байтов. По завершении обработки всех чанков функция возвращает полный список закодированных байтов и исходную битовую длину оригинальных данных.
Функция decode_and_reassemble выполняет обратную операцию. Она принимает список байтов, предположительно содержащий последовательность RS-кодовых слов, объект RS-кодера и исходную битовую длину данных. В первую очередь, функция проверяет, кратна ли длина входных байтов размеру кодового слова n. Если нет, она выводит предупреждение и обрезает входные данные до ближайшей длины, кратной n, чтобы избежать ошибок при дальнейшей обработке. Затем данные обрабатываются последовательными блоками размером n байт. Каждый блок преобразуется в вектор над полем Галуа. Этот вектор передается методу decode объекта rs_coder внутри блока try-except. Если декодирование проходит успешно (количество ошибок в блоке не превышает исправляющую способность t=2), метод возвращает k исходных информационных символов (байтов), которые добавляются к списку восстановленных данных. Если же в блоке обнаруживается больше ошибок, чем код может исправить, библиотека galois генерирует исключение ReedSolomonError. В этом случае обработчик исключений записывает сообщение об ошибке, устанавливает флаг all_blocks_success в False и добавляет k нулевых байтов в список восстановленных данных в качестве плейсхолдера для поврежденного блока. После обработки всех блоков, собранные k-байтовые информационные фрагменты (включая нулевые плейсхолдеры) преобразуются обратно в единую бинарную строку. Наконец, эта строка обрезается до исходной длины, которая была сохранена на этапе кодирования, чтобы удалить возможно добавленное дополнение. Функция возвращает восстановленную бинарную строку и флаг, указывающий, были ли все блоки декодированы без неисправляемых ошибок.
# --- Параметры Кода Рида-Соломона ---
m = 8
GF = galois.GF(2**m, irreducible_poly='x^8+x^4+x^3+x^2+1')
# --- Параметры RS(n, k) ---
k = 11 # Фиксированный размер информационного блока
BITS_PER_K_BLOCK = k * m
n = 15 # k + избыточность
t = (n - k) // 2 # Исправляющая способность = 2 ошибки на блок
# --- Создание объекта RS кодера/декодера ---
try:
rs = galois.ReedSolomon(n, k, field=GF)
print("Объект кода Рида-Соломона успешно создан.")
except ValueError as e:
print(f"Ошибка создания кода RS: {e}")
exit()
# --- Вспомогательные функции ---
def segment_and_encode(long_bin_str, rs_coder):
"""Сегментирует, дополняет, кодирует."""
k_bytes = rs_coder.k
bits_per_chunk = k_bytes * 8
original_bit_length = len(long_bin_str)
padding_len = (bits_per_chunk - (original_bit_length % bits_per_chunk)) % bits_per_chunk
padded_bin_str = long_bin_str + '0' * padding_len
total_padded_bits = len(padded_bin_str)
num_chunks = total_padded_bits // bits_per_chunk
print(f"Кодирование: Исходная длина: {original_bit_length} бит.")
print(f"Кодирование: Дополнено до {total_padded_bits} бит.")
print(f"Кодирование: Количество {bits_per_chunk}-битных чанков: {num_chunks}.")
all_encoded_bytes = []
for i in range(num_chunks):
chunk_bin = padded_bin_str[i * bits_per_chunk : (i + 1) * bits_per_chunk]
chunk_k_bytes = [int(chunk_bin[j:j+8], 2) for j in range(0, bits_per_chunk, 8)]
message_gf = GF(chunk_k_bytes)
codeword_gf_n = rs_coder.encode(message_gf)
all_encoded_bytes.extend(list(codeword_gf_n))
print(f"Кодирование: Закодировано в {len(all_encoded_bytes)} байт.")
return all_encoded_bytes, original_bit_length
def decode_and_reassemble(received_n_bytes, rs_coder, original_total_bit_length):
"""Декодирует, собирает, обрезает."""
n_block = rs_coder.n
k_block = rs_coder.k
if len(received_n_bytes) % n_block != 0:
print(f"Предупреждение: Длина принятых ({len(received_n_bytes)}) не кратна n ({n_block}). Обрезаем.")
num_blocks = len(received_n_bytes) // n_block
if num_blocks == 0: return None, False
received_n_bytes = received_n_bytes[:num_blocks * n_block]
num_blocks_to_decode = len(received_n_bytes) // n_block
all_decoded_k_bytes = []
all_blocks_success = True
print(f"Декодирование: Принято {len(received_n_bytes)} байт. Декодируем {num_blocks_to_decode} блоков по {n_block} байт...")
for i in range(num_blocks_to_decode):
chunk_n = received_n_bytes[i * n_block : (i + 1) * n_block]
received_gf = GF(chunk_n)
try:
decoded_gf_k = rs_coder.decode(received_gf)
all_decoded_k_bytes.extend(list(decoded_gf_k))
except Exception as e:
print(f"ОШИБКА ДЕКОДИРОВАНИЯ RS в блоке {i}: {type(e).__name__}")
all_blocks_success = False
all_decoded_k_bytes.extend([0] * k_block) # Заполняем нулями
if not all_blocks_success:
print("Декодирование завершено с ошибками в некоторых блоках.")
print(f"Декодирование: Собрано {len(all_decoded_k_bytes)} байт k-блоков.")
if not all_decoded_k_bytes:
restored_bin_str_padded = ""
else:
restored_bin_str_padded = "".join(format(byte, '08b') for byte in all_decoded_k_bytes)
final_len = min(original_total_bit_length, len(restored_bin_str_padded))
restored_bin_signal = restored_bin_str_padded[:final_len]
if len(restored_bin_signal) < original_total_bit_length and all_blocks_success:
print(f"Предупреждение: Восстановлено бит {len(restored_bin_signal)}, ожидалось {original_total_bit_length}.")
print(f"Декодирование: Восстановлена битовая строка длиной {len(restored_bin_signal)}.")
return restored_bin_signal, all_blocks_success
Первая функция, scale_analog_to_digital, выполняет математическое масштабирование аналогового значения напряжения к соответствующему диапазону цифровых уровней. Она принимает аналоговое значение, количество бит квантования (bits) и опорное напряжение (v_ref), которое определяет симметричный диапазон входного сигнала от -v_ref до +v_ref. Функция сначала вычисляет максимальный возможный цифровой уровень (2^bits - 1). Затем она нормализует входное аналоговое значение: сдвигает его на v_ref и делит на полный размах 2 * v_ref, приводя его к диапазону от 0 до 1. Наконец, это нормализованное значение умножается на максимальный цифровой уровень, чтобы получить соответствующее значение в цифровом диапазоне. Важно отметить, что эта функция возвращает масштабированное значение (возможно, дробное) и сама по себе не выполняет окончательное округление или усечение до целого числа, которое является сутью процесса квантования.
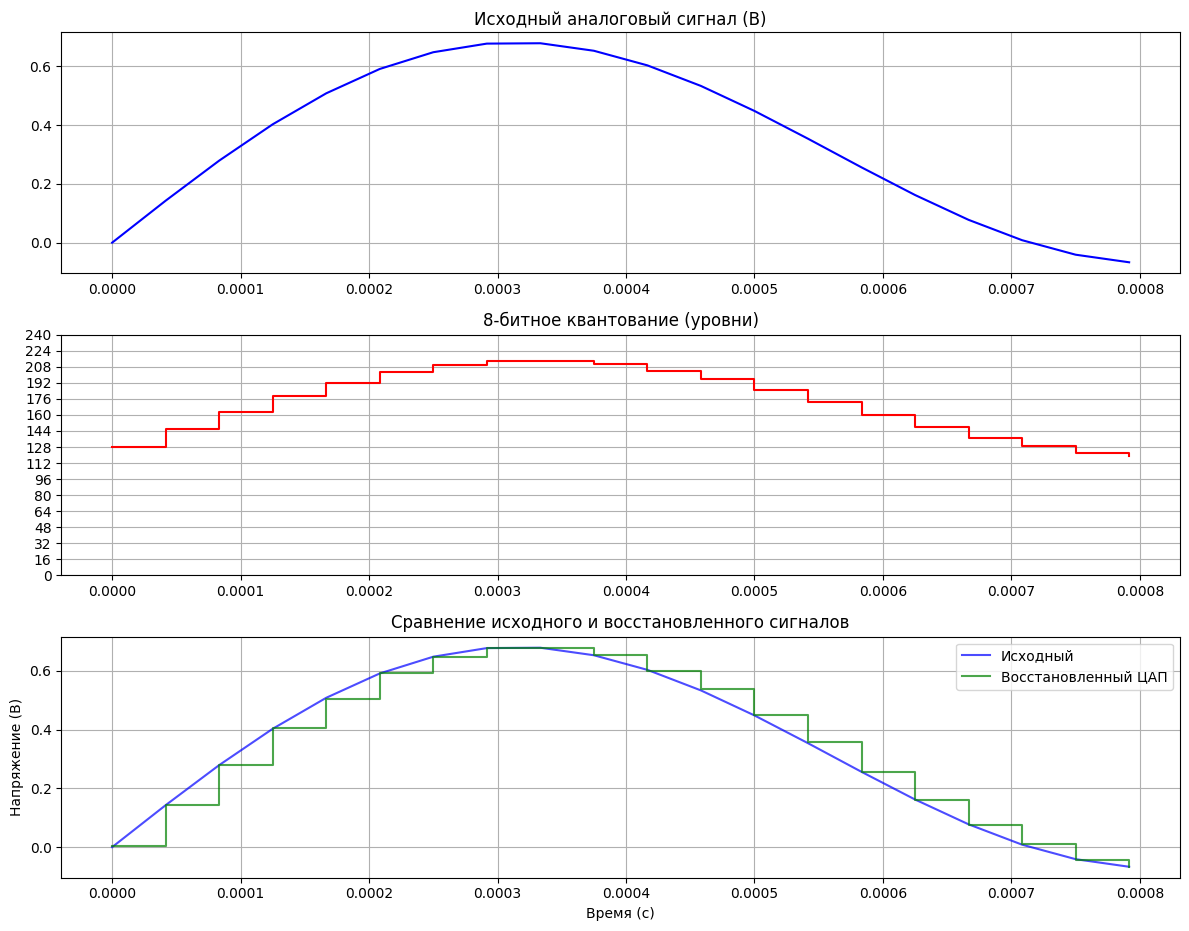
Вторая функция, plot_signals, предназначена для визуализации различных этапов моделирования аналого-цифрового преобразователя (АЦП) и последующего цифро-аналогового преобразователя (ЦАП). Она принимает временной вектор t, исходный аналоговый сигнал analog, сигнал после квантования quantized (представленный дискретными цифровыми уровнями), сигнал reconstructed, восстановленный из цифрового с помощью имитации ЦАП, а также параметры bits и v_ref. Функция создает окно с тремя графиками (субплотами), расположенными друг под другом. Первый субплот отображает исходный непрерывный аналоговый сигнал во времени. Второй субплот показывает квантованный цифровой сигнал в виде ступенчатой диаграммы (plt.step), где оси Y настроены для отображения дискретных уровней квантования. Третий субплот сравнивает исходный аналоговый сигнал с сигналом, восстановленным после ЦАП, также используя ступенчатую диаграмму для последнего, что позволяет наглядно оценить погрешность квантования. Все графики снабжены заголовками, метками осей и сеткой для удобства анализа.
Третья функция, plot_encoding, служит для визуализации цифровых сигналов до, во время и после применения какого-либо линейного кода (например, NRZ, Манчестерского и т.д.). Она принимает исходную бинарную строку original_str, бинарную строку, представляющую закодированный сигнал encoded_str, бинарную строку, полученную после декодирования decoded_str, заголовок для всего набора графиков и необязательный параметр time_scale_factor для масштабирования временной оси закодированного сигнала (полезно для кодов, изменяющих тактовую частоту). Функция создает окно с тремя субплотами. Перед построением она преобразует бинарные строки ('0', '1') в последовательности уровней (+1, -1) для наглядности отображения. Затем для каждого из трех сигналов (исходного, кодированного, декодированного) строится ступенчатая диаграмма уровней во времени. Оси X настраиваются так, чтобы обеспечивать хорошую читаемость, ограничивая количество меток. Эта функция позволяет визуально сравнить форму сигналов на разных этапах обработки линейным кодом и оценить корректность работы кодера и декодера.
def scale_analog_to_digital(analog, bits, v_ref):
"""Масштабирование аналогового сигнала к цифровому диапазону"""
max_level = 2 ** bits - 1
scaled_analog = ((analog + v_ref) / (2 * v_ref)) * max_level
return scaled_analog
def plot_signals(t, analog, quantized, reconstructed, bits, v_ref):
"""Визуализация с ЦАП и 4 субплотами"""
plt.figure(figsize=(12, 12))
# 1. Исходный аналоговый сигнал
plt.subplot(4, 1, 1)
plt.plot(t, analog, 'b', label='Аналоговый сигнал')
plt.title('Исходный аналоговый сигнал (В)')
plt.grid(True)
# 2. Цифровой сигнал
plt.subplot(4, 1, 2)
plt.step(t, quantized, 'r', where='post', label='Цифровой сигнал')
plt.title(f'{bits}-битное квантование (уровни)')
plt.yticks(range(0, 2 ** bits, 2 ** (bits - 4)))
plt.grid(True)
# 4. Сравнение с восстановленным сигналом
plt.subplot(4, 1, 3)
plt.plot(t, analog, 'b', label='Исходный', alpha=0.7)
plt.step(t, reconstructed, 'g', where='post', label='Восстановленный ЦАП', alpha=0.7)
plt.title('Сравнение исходного и восстановленного сигналов')
plt.xlabel('Время (с)')
plt.ylabel('Напряжение (В)')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
# --- Функция для визуализации ---
def plot_encoding(original_str, encoded_str, decoded_str, title, time_scale_factor=1):
"""
Строит графики для исходного, кодированного и декодированного сигналов.
"""
fig, axs = plt.subplots(3, 1, sharex=False, figsize=(15, 8)) # figsize для читаемости
fig.suptitle(title, fontsize=16)
# --- Подготовка данных для графиков ---
# Используем уровни +1 и -1 для наглядности, но DC считаем по 0/1
# 1. Исходный сигнал
y_original = [1 if bit == '1' else -1 for bit in original_str]
x_original = np.arange(len(y_original) + 1) # +1 для отрисовки последнего уровня
y_original_plot = np.append(y_original, y_original[-1]) # Дублируем последний для step
# 2. Кодированный сигнал
y_encoded = [1 if bit == '1' else -1 for bit in encoded_str]
# Масштабируем время для Манчестера
x_encoded = np.arange(len(y_encoded) + 1) / time_scale_factor
y_encoded_plot = np.append(y_encoded, y_encoded[-1])
# 3. Декодированный сигнал
y_decoded = [1 if bit == '1' else -1 for bit in decoded_str]
# Проверка на случай пустого декодированного сигнала
if not y_decoded:
x_decoded = np.array([0])
y_decoded_plot = np.array([-1]) # Показать пустой график
else:
x_decoded = np.arange(len(y_decoded) + 1)
y_decoded_plot = np.append(y_decoded, y_decoded[-1])
# --- Построение графиков ---
axs[0].step(x_original, y_original_plot, where='post', color='blue')
axs[0].set_title('Исходный сигнал')
axs[0].set_ylabel('Уровень')
axs[0].set_yticks([-1, 1])
axs[0].grid(True)
axs[0].set_xlim(0, len(x_original) - 1)
axs[0].set_ylim(-1.5, 1.5)
axs[1].step(x_encoded, y_encoded_plot, where='post', color='red')
axs[1].set_title('Закодированный сигнал')
axs[1].set_ylabel('Уровень')
axs[1].set_xlabel('Время (условные единицы)')
axs[1].set_yticks([-1, 1])
axs[1].grid(True)
axs[1].set_xlim(0, x_encoded[-1] if len(x_encoded) > 1 else 1) # Корректный xlim
axs[1].set_ylim(-1.5, 1.5)
axs[2].step(x_decoded, y_decoded_plot, where='post', color='green')
axs[2].set_title('Декодированный сигнал')
axs[2].set_ylabel('Уровень')
axs[2].set_xlabel('Время (условные единицы)')
axs[2].set_yticks([-1, 1])
axs[2].grid(True)
axs[2].set_xlim(0, len(x_decoded) - 1 if len(x_decoded) > 1 else 1)
axs[2].set_ylim(-1.5, 1.5)
# Улучшаем читаемость осей X
max_time_orig = len(original_str)
axs[0].set_xticks(np.linspace(0, max_time_orig, min(max_time_orig + 1, 21))) # До 20 тиков
axs[1].set_xticks(np.linspace(0, max_time_orig, min(max_time_orig + 1, 21)))
axs[2].set_xticks(np.linspace(0, max_time_orig, min(max_time_orig + 1, 21)))
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
Функции для анализа сигналов
def calculate_signal_memory(signal):
"""
Возвращает размер сигнала в байтах, не учитывает особенности ЯП.
"""
return sum(len(code) for code in signal)
def calculate_dc_imbalance(encoded_signal_list):
"""
Вычисляет DC имбаланс для списка закодированных сигналов ('0' и '1').
Возвращает среднее значение (count('1') - count('0')) / total_length.
0 - идеальный баланс. +1 - только '1'. -1 - только '0'.
"""
total_ones = 0
total_zeros = 0
total_length = 0
for encoded_signal_str in encoded_signal_list:
length = len(encoded_signal_str)
if length == 0:
continue # Пропускаем пустые строки
ones_in_str = encoded_signal_str.count('1')
zeros_in_str = length - ones_in_str # Считаем нули как разницу
total_ones += ones_in_str
total_zeros += zeros_in_str
total_length += length
if total_length == 0:
print("Предупреждение: Общая длина закодированного сигнала для расчета DC равна 0.")
return 0.0 # Возвращаем 0 для пустого входа
# Считаем финальный имбаланс: (Всего единиц - Всего нулей) / Общая длина
imbalance = (total_ones - total_zeros) / total_length
return imbalance
Начальная настройка параметров и генерация аналогового сигнала, который в дальнейшем может быть подвергнут процессам дискретизации, квантования и кодирования.
Сначала определяются основные параметры сигнала и системы обработки. Задается duration - длительность сигнала, установленная в 1 секунду. fs - частота дискретизации, выбранная равной 24000 Гц (или 24 кГц), что определяет, сколько раз в секунду будет измеряться аналоговый сигнал при его преобразовании в цифровую форму. Параметр bits, равный 8, задает разрядность квантования, то есть количество бит, используемых для представления каждого цифрового отсчета, что определяет 2^8 = 256 возможных уровней. Наконец, v_ref устанавливается в 1 Вольт, задавая диапазон аналогового сигнала от -1В до +1В, который будет корректно оцифрован.
Далее генерируется временная ось x с помощью функции np.linspace. Она создает массив временных точек от 0 до duration (не включая конечную точку) с шагом, определяемым частотой дискретизации fs. Общее количество точек в массиве равно fs * duration. На основе этой временной оси создается сам аналоговый сигнал analog. Он формируется как сумма трех синусоидальных колебаний с различными частотами и амплитудами: первое с частотой 900 Гц и амплитудой 0.5, второе с частотой 200 Гц и амплитудой 0.3, и третье также с частотой 200 Гц и амплитудой 0.2. Суммирование этих синусоид создает более сложный по форме сигнал, имитирующий реальный аналоговый сигнал, содержащий несколько частотных компонент.
# Параметры сигнала
duration = 1 # 100 мс для лучшей детализации
fs = 24000 # Частота дискретизации 4 кГц
bits = 8 # 8-битное квантование
v_ref = 1 # Опорное напряжение ±1В
# Генерация сигнала
x = np.linspace(0, duration, int(fs * duration), endpoint=False)
analog = (
0.5 * np.sin(2 * np.pi * 900 * x) +
0.3 * np.sin(2 * np.pi * 200 * x) +
0.2 * np.sin(2 * np.pi * 200 * x)
)
Применим АЦП и визуализируем
# АЦП преобразование
quantized, binary = adc_converter(analog, bits=bits, v_ref=v_ref)
# Также представим сигнал в сплошном виде
binary_concat = ''.join(binary)
# Визуализируем с обрезкой
reconstructed = dac_converter(quantized, bits=bits, v_ref=v_ref)
plot_signals(x[:20], analog[:20], quantized[:20], reconstructed[:20], bits, v_ref)
NRZI анализ и графика
initial_nrzi_level = '1' # Установите начальный уровень
# Считаем исходную память
binary_bits = calculate_signal_memory(binary)
# Кодирование, декодирование методом NRZI и анализ.
nrzi_encoded = nrzi_encode(binary_concat, initial_level=initial_nrzi_level)
nrzi_decoded = nrzi_decode(nrzi_encoded, initial_level=initial_nrzi_level)
print(f'Сигналы идентичны до и после кодека (NRZI): {nrzi_decoded == binary_concat}')
# Анализ памяти (должна быть такой же)
nrzi_bits = calculate_signal_memory(nrzi_encoded)
print(f'Память, занимаемая NRZI кодом: {nrzi_bits} бит (ожидалось: {binary_bits})')
# Анализ DC составляющей
nrzi_dc = calculate_dc_imbalance(nrzi_encoded)
print(f'NRZI DC Имбаланс: {nrzi_dc:.4f} (0 = идеально, +/-1 = плохо)')
# Визуализация NRZI
plot_encoding(binary_concat[:20], nrzi_encoded[:20], nrzi_decoded[:20], "NRZI Кодирование/Декодирование")
Манчестер анализ и графика
# Кодирование, декодирование Манчестерским кодом и анализ
manchester_encoded = manchester_encode(binary_concat)
manchester_decoded = manchester_decode(manchester_encoded)
print(f'Сигналы идентичны до и после кодека (Манчестерское кодирование): {manchester_decoded == binary_concat}')
# Анализ памяти, ожидаем увеличение размера в два раза
manchester_bits = calculate_signal_memory(manchester_encoded)
print(f'Память, занимаемая Манчестерским кодом: {manchester_bits} бит (ожидалось: {binary_bits * 2})')
# Проверка отношения памяти
if binary_bits > 0:
print(f'Отношение памяти (Манчестер/Исходный): {manchester_bits / binary_bits:.2f} (ожидалось: 2.0)')
# Анализ DC составляющей
manchester_dc = calculate_dc_imbalance(manchester_encoded)
print(f'Manchester DC Имбаланс: {manchester_dc:.4f} (0 = идеально, +/-1 = плохо)')
# Визуализация Манчестера
manchester_encoded_concat = "".join(manchester_encoded)
manchester_decoded_concat = "".join(manchester_decoded)
plot_encoding(binary_concat[:20], manchester_encoded_concat[:40], manchester_decoded_concat[:20],
"Манчестерское Кодирование/Декодирование", time_scale_factor=2)
Хаффман анализ
# Кодирование, декодирование алгоритмом Хаффмана и анализ
huffman_code, codes = Huffman.encode(binary)
huffman_decode = Huffman.decode(huffman_code, codes)
# Реальный размер данных (без накладных расходов ЯП):
huffman_bits = calculate_signal_memory(huffman_code)
binary_bits = calculate_signal_memory(binary)
print('--Анализ алгоритма Хаффмана:')
print(f'Сигналы идентичны до и после кодека (Хаффман): {huffman_decode == binary}')
print(f"Huffman: {huffman_bits} бит")
print(f"Binary: {binary_bits} бит")
print(f"Уменьшение размера на {(binary_bits-huffman_bits)/binary_bits * 100}%")
Хэмминг анализ
# для тестирования Хэмминга
def introduce_errors(encoded_block, num_errors):
"""Вносит ровно num_errors случайных битовых ошибок в один блок."""
if not (0 <= num_errors <= len(encoded_block)):
raise ValueError(f"Количество ошибок ({num_errors}) д.б. между 0 и {len(encoded_block)}")
if num_errors == 0:
return encoded_block, []
block_list = list(encoded_block)
block_length = len(block_list)
# Убедимся, что не пытаемся выбрать больше позиций, чем есть в блоке
if num_errors > block_length:
num_errors = block_length # Вносим ошибки во все биты, если запрошено больше
error_indices = random.sample(range(block_length), num_errors)
for index in error_indices:
block_list[index] = '1' if block_list[index] == '0' else '0'
return "".join(block_list), sorted(error_indices)
print(f"Исходный сигнал ({len(binary_concat)} бит): (Первые 30 бит):: {binary_concat[:30]}")
# 2. Кодируем весь сигнал
encoded_signal, original_len_saved = hamming_encode(binary_concat)
num_blocks = len(encoded_signal) // BLOCK_SIZE
print(f"Закодированный сигнал ({len(encoded_signal)} бит, {num_blocks} блоков): (Первые 30 бит):: {encoded_signal[:30]}")
print("-" * 60)
# 3. Цикл по количеству ОШИБОК В КАЖДОМ БЛОКЕ
for errors_per_block in range(3): # Проверяем 0, 1, 2 ошибки В КАЖДОМ блоке
print(f"\n===== Тест с {errors_per_block} ошибками В КАЖДОМ блоке =====")
noisy_blocks = []
total_errors_introduced = 0
error_details = {} # Словарь для отслеживания ошибок по блокам
# 4. Итерация по блокам закодированного сигнала
for i in range(num_blocks):
start_index = i * BLOCK_SIZE
end_index = start_index + BLOCK_SIZE
original_block = encoded_signal[start_index:end_index]
# Вносим ошибки ИМЕННО в этот блок
noisy_block, error_indices = introduce_errors(original_block, errors_per_block)
noisy_blocks.append(noisy_block)
if error_indices:
total_errors_introduced += len(error_indices)
error_details[i] = {"original": original_block, "noisy": noisy_block, "indices": error_indices}
# 5. Собираем полный "шумный" сигнал
noisy_encoded_signal = "".join(noisy_blocks)
# Показать детализацию ошибок для первых нескольких блоков (если были ошибки)
if error_details:
print(" Примеры блоков с внесенными ошибками:")
for block_idx in range(min(3, num_blocks)): # Показать до 3 примеров
if block_idx in error_details:
details = error_details[block_idx]
diff_markers = "".join(['^' if details["original"][j] != details["noisy"][j] else ' ' for j in range(BLOCK_SIZE)])
print(f" Блок {block_idx}: {details['original']} (ориг.)")
print(f" {diff_markers} (ошибки в поз: {details['indices']})")
print(f" {details['noisy']} (с шумом)")
# 6. Декодирование всего шумного сигнала
print("\n --- Декодирование ---")
# Используем original_len_saved, которую вернул кодер!
decoded_signal, corrected_count = hamming_decode(noisy_encoded_signal, original_len_saved)
print(f" Декодер сообщил об исправлении {corrected_count} ошибок (по блокам).")
# 7. Проверка результата
print("\n --- Проверка результата ---")
if decoded_signal == binary_concat:
if errors_per_block <= 1:
print(" РЕЗУЛЬТАТ: УСПЕХ! Сигнал полностью восстановлен (ожидаемо).")
else:
# Это очень маловероятно при >1 ошибке на блок
print(" РЕЗУЛЬТАТ: УСПЕХ?! Сигнал совпал (НЕОЖИДАННО! Вероятно, ошибки случайно скомпенсировались).")
else:
if errors_per_block <= 1:
# Этого не должно быть при 0 или 1 ошибке в каждом блоке
print(" РЕЗУЛЬТАТ: ОШИБКА! Сигнал НЕ восстановлен (НЕОЖИДАННО!).")
# Покажем различия
max_len = max(len(binary_concat), len(decoded_signal))
original_padded = binary_concat.ljust(max_len)
decoded_padded = decoded_signal.ljust(max_len)
diff_markers_final = "".join(['^' if original_padded[i] != decoded_padded[i] else ' ' for i in range(max_len)])
print(f" Ожидалось: {original_padded}")
print(f" Получено: {decoded_padded}")
print(f" Различия: {diff_markers_final}")
else:
# Ожидаемое поведение для >1 ошибки на блок
print(" РЕЗУЛЬТАТ: ОШИБКА ДЕКОДИРОВАНИЯ! Сигнал НЕ восстановлен (ожидаемо).")
Анализ кодирования Рида-Соломона
# --- Функция внесения ошибок для RS ---
def introduce_rs_byte_errors(encoded_bytes, n_block_size, errors_per_block, gf_field):
"""
Вносит ровно errors_per_block случайных БАЙТОВЫХ ошибок в КАЖДЫЙ n-байтовый блок.
Заменяет байт на другой случайный байт из поля GF.
"""
if not (0 <= errors_per_block <= n_block_size):
raise ValueError(f"Количество ошибок ({errors_per_block}) д.б. между 0 и {n_block_size}")
noisy_bytes = list(encoded_bytes) # Копируем, чтобы не изменять оригинал
num_blocks = len(encoded_bytes) // n_block_size
total_errors_introduced = 0
error_details = {} # Словарь для отслеживания ошибок: {block_idx: {pos: (old_val, new_val)}}
if errors_per_block == 0:
return noisy_bytes, 0, error_details # Нет ошибок, возвращаем копию
# Проходим по каждому n-байтовому блоку
for i in range(num_blocks):
block_start_idx = i * n_block_size
block_end_idx = block_start_idx + n_block_size
error_details[i] = {} # Инициализируем детали для блока
# Выбираем уникальные позиции для ошибок внутри этого блока
error_indices_in_block = random.sample(range(n_block_size), errors_per_block)
# Вносим ошибки в выбранные позиции
for err_pos_in_block in error_indices_in_block:
global_pos = block_start_idx + err_pos_in_block # Глобальный индекс в списке noisy_bytes
original_byte = noisy_bytes[global_pos]
# Генерируем НОВЫЙ случайный байт (элемент поля GF)
# Убедимся, что новый байт отличается от старого
new_byte = original_byte
while new_byte == original_byte:
# Генерируем случайное целое число в диапазоне [0, порядок поля - 1]
new_byte = random.randint(0, gf_field.order - 1)
# Заменяем байт в "шумном" списке
noisy_bytes[global_pos] = new_byte
error_details[i][err_pos_in_block] = (original_byte, new_byte)
total_errors_introduced += 1
return noisy_bytes, total_errors_introduced, error_details
# --- ТЕСТИРОВАНИЕ ---
# 1. Генерируем исходный битовый сигнал (например, 5 k-блоков информации)
num_k_blocks_for_test = 5
original_data_len_bits = num_k_blocks_for_test * BITS_PER_K_BLOCK
long_bin_str = "".join(random.choices(['0', '1'], k=original_data_len_bits))
print("=" * 60)
print("НАЧАЛО ТЕСТИРОВАНИЯ КОДА РИДА-СОЛОМОНА")
print("=" * 60)
print(f"Параметры RS: n={n}, k={k}, m={m}, t={t} (байт/символов)")
print(f"Генерируем тестовый сигнал: {original_data_len_bits} бит ({num_k_blocks_for_test} инф. блоков по {k} байт)")
print(f"Исходный сигнал (первые 60 бит): {long_bin_str[:60]}...")
# 2. Кодируем весь сигнал ОДИН РАЗ
encoded_bytes, original_len_saved = segment_and_encode(long_bin_str, rs)
num_encoded_blocks = len(encoded_bytes) // n
print(f"Закодированный сигнал: {len(encoded_bytes)} байт ({num_encoded_blocks} блоков по {n} байт).")
print("-" * 60)
# 3. Цикл по количеству ОШИБОК В КАЖДОМ N-БАЙТОВОМ БЛОКЕ
# Тестируем от 0 до t+1 ошибок, чтобы увидеть предел
for errors_per_block in range(t + 2):
print(f"\n===== Тест с {errors_per_block} ошибками (байт) В КАЖДОМ n-блоке =====")
# 4. Вносим ошибки в закодированные байты
noisy_encoded_bytes, total_errors_introduced, error_details = introduce_rs_byte_errors(
encoded_bytes,
rs.n,
errors_per_block,
GF
)
print(f" Внесение ошибок: Всего введено {total_errors_introduced} байтовых ошибок.")
# Показать детализацию ошибок для первых нескольких блоков (если были ошибки)
if error_details:
print(" Примеры блоков с внесенными ошибками (до 3х блоков):")
for block_idx in range(min(3, num_encoded_blocks)):
if block_idx in error_details and error_details[block_idx]:
print(f" Блок {block_idx}:")
details = error_details[block_idx] # {pos: (old, new)}
# --- ИСПРАВЛЕНИЕ ЗДЕСЬ ---
# Убедитесь, что нет посторонних символов в индексах среза
start_idx = block_idx * n
end_idx = (block_idx + 1) * n
original_block_bytes = encoded_bytes[start_idx : end_idx]
noisy_block_bytes = noisy_encoded_bytes[start_idx : end_idx]
# --- КОНЕЦ ИСПРАВЛЕНИЯ ---
# Формируем строки для сравнения
orig_str = " ".join(f"{b:02x}" for b in original_block_bytes)
noisy_str= " ".join(f"{b:02x}" for b in noisy_block_bytes)
diff_markers = ""
pos_details = []
for i in range(n):
if i in details:
diff_markers += "^^ "
pos_details.append(f"{i}({details[i][0]:02x}->{details[i][1]:02x})")
else:
diff_markers += " "
print(f" Ориг: {orig_str}")
print(f" Шум: {noisy_str}")
print(f" {diff_markers.strip()}")
print(f" Ошибки в позициях (байт): {', '.join(pos_details)}")
# 5. Декодирование всего "шумного" набора байт
print("\n --- Декодирование ---")
# Используем original_len_saved, которую вернул кодер!
restored_bin_signal, all_blocks_decoded_successfully = decode_and_reassemble(
noisy_encoded_bytes,
rs,
original_len_saved
)
# 6. Проверка результата
print("\n --- Проверка результата ---")
if restored_bin_signal is None:
print(" РЕЗУЛЬТАТ: ОШИБКА! Декодер вернул None.")
success = False
elif restored_bin_signal == long_bin_str:
if errors_per_block <= t:
if all_blocks_decoded_successfully:
print(f" РЕЗУЛЬТАТ: УСПЕХ! Сигнал полностью восстановлен ({errors_per_block} <= t={t} ошибок на блок, ожидаемо).")
success = True
else:
# Это странно: сигнал совпал, но декодер сообщил об ошибках?
print(f" РЕЗУЛЬТАТ: УСПЕХ?! Сигнал совпал, но декодер сообщил о неисправимых ошибках (НЕОЖИДАННО!).")
success = True # Формально данные верны
else:
# Это очень маловероятно при >t ошибках на блок
print(f" РЕЗУЛЬТАТ: УСПЕХ?! Сигнал совпал ({errors_per_block} > t={t} ошибок на блок, НЕОЖИДАННО! Возможно, ошибки случайно скомпенсировались или не затронули данные).")
success = True
else: # restored_bin_signal != long_bin_str
if errors_per_block <= t:
# Этого не должно быть при <= t ошибках в каждом блоке, если декодер работает
print(f" РЕЗУЛЬТАТ: ОШИБКА! Сигнал НЕ восстановлен ({errors_per_block} <= t={t} ошибок на блок, НЕОЖИДАННО!).")
if not all_blocks_decoded_successfully:
print(" (Декодер также сообщил о неисправимых ошибках, что объясняет расхождение).")
# Покажем различия
max_len = max(len(long_bin_str), len(restored_bin_signal))
original_padded = long_bin_str.ljust(max_len, '-')
decoded_padded = restored_bin_signal.ljust(max_len, '-')
diff_count = sum(1 for i in range(max_len) if original_padded[i] != decoded_padded[i])
print(f" Найдено {diff_count} различий в битах.")
# Выведем только начало различий для краткости
limit = 100
diff_markers_final = "".join(['^' if original_padded[i] != decoded_padded[i] else ' ' for i in range(min(max_len, limit))])
print(f" Ожидалось (до {limit} бит): {original_padded[:limit]}")
print(f" Получено (до {limit} бит): {decoded_padded[:limit]}")
print(f" Различия (до {limit} бит): {diff_markers_final}")
success = False
else:
# Ожидаемое поведение для >t ошибок на блок
print(f" РЕЗУЛЬТАТ: ОШИБКА ДЕКОДИРОВАНИЯ! Сигнал НЕ восстановлен ({errors_per_block} > t={t} ошибок на блок, ожидаемо).")
if not all_blocks_decoded_successfully:
print(" (Декодер корректно сообщил о невозможности исправить ошибки).")
else:
print(" (Декодер НЕ сообщил об ошибках, но данные неверны - возможно, ложное декодирование).")
diff_count = sum(1 for i in range(len(long_bin_str)) if i >= len(restored_bin_signal) or long_bin_str[i] != restored_bin_signal[i])
print(f" Найдено {diff_count} различий в битах.")
success = False
print("-" * 60)
print("\nТестирование завершено.")
По результатам анализа возможно сделать выводы: NRZI и манчестерское кодирование могут быть применены в передаче данных в системах, где помехи маловероятны, но важна синхронизация приемника и передатчика (например, шины USB или UART); процент сжатия сигнала алгоритмом Хаффмана в реальности может быть выше, так как в анализе используется сигнал, который складывается из нескольких синусоид, что не дает значительного количественного преобладания какой-либо частоты над другими, гораздо большее сжатие можно было бы наблюдать при кодировании голоса, ведь в таком случае действительно есть преобладающая частота. Алгоритм Хэмминга может быть применен в слабозашумленных каналах передачи, где ошибки либо единичны, либо "размазаны" по всему сигналу, поскольку его исправляющая способность относительно низкая. Кодирование Рида-Соломона очень эффективно при мощных локальных искажениях сигнала, когда повреждаются сразу несколько соседних бит, однако его работа требует значительных вычислительных мощностей, в отличие от кодирования Хэмминга.