GUI для обучения нейросети
Настройка процесса обучения нейросети
В этом примере мы создадим окружение для обучения нейросети, управляемый при помощи удобной графической формы.
Описание задачи
Разработка нейросетей давно перестала быть уделом только лишь исследователей с многолетним опытом в написании кода. Сегодня это инструмент инженера, аналитика и продуктолога. Однако часто порог входа всё ещё высок: даже для простой полносвязной сети с тремя слоями нужно помнить синтаксис библиотек вроде Flux.jl и правильно загрузить датасет из CSV и вывести правильные графики... Именно здесь на помощь приходят графические интерфейсы (GUI). Они позволяют сосредоточиться на сути задачи — работе над качеством данных и интерпретацией результата, а не на банальных ошибках, которые все делают на первом этапе.
Создадим интерфейс для обучения нейросети, под которым всё равно будет скрываться всё та же математика и операции с данными, осуществляющие загрузку, распределение, обучение и проверку качества нейросети.
Подготовительные операции включают установку библиотеки для обучения нейросетей:
# Компиляция библиотеки Flux может занять минуту
Pkg.add(["Flux", "Interpolations"])
using Flux, CSV, DataFrames, Random
using Flux: mse
using Statistics, Interpolations
gr()
Теперь мы разработаем GUI, который позволяет передвинуть ползунок и обучить нейросеть с нужным количеством нейронов, который будет загружать данные и обучать нейросеть.
Предположения: в папке со скриптом лежат файлы train.csv и test.csv. Первый столбец каждого файла содержит прогнозируемую переменную, остальные столбцы содержат признаки. Мы решаем задачу регрессии.
# Переместимся в директорию с этим скриптом
cd(@__DIR__)
train_filename = "train.csv" # @param {type:"string"}
test_filename = "test.csv" # @param {type:"string"}
train_df = CSV.read(train_filename, DataFrame, types=Float32)
test_df = CSV.read(test_filename, DataFrame, types=Float32)
# Предполагаем, что первый столбец содержит прогнозируемые значения, а остальные -- признаки
X_train = Matrix(train_df[:, 2:end])' # (n_features, n_samples)
X_test = Matrix(test_df[:, 2:end])' # (n_features, n_samples)
y_train_raw = reshape(train_df[:, 1], 1, :) # (1, n_samples)
y_test_raw = reshape(test_df[:, 1], 1, :) # (1, n_samples)
# Нормализация признаков
X_train_mean = mean(X_train, dims=2)
X_train_std = std(X_train, dims=2)
# Нормализуем train и test с параметрами train-выборки
X_train_norm = (X_train .- X_train_mean) ./ X_train_std
X_test_norm = (X_test .- X_train_mean) ./ X_train_std
# Нормализуем целевые значения
y_train_mean = mean(y_train_raw)
y_train_std = std(y_train_raw)
y_train_norm = (y_train_raw .- y_train_mean) ./ y_train_std
y_test_norm = (y_test_raw .- y_train_mean) ./ y_train_std
features_count = size(X_train_norm, 1)
l1_neurons = 30 # @param {type:"slider",min:1,max:30,step:1}
l2_neurons = 28 # @param {type:"slider",min:1,max:30,step:1}
l3_neurons = 25 # @param {type:"slider",min:1,max:30,step:1}
l4_neurons = 13 # @param {type:"slider",min:1,max:30,step:1}
l5_neurons = 1 # @param {type:"slider",min:1,max:30,step:1}
n_epochs = 499 # @param {type:"slider",min:1,max:500,step:1}
# Архитектура для регрессии
model = Chain(
Dense(features_count => l1_neurons, relu),
Dense(l1_neurons => l2_neurons, relu),
Dense(l2_neurons => l3_neurons, relu),
Dense(l3_neurons => l4_neurons, relu),
Dense(l4_neurons => l5_neurons, relu),
Dense(l5_neurons => 1)
)
# Обучение
loss(m, x, y) = mse(m(x), y)
opt_state = Flux.setup(Adam(0.001), model)
data = [(X_train_norm, y_train_norm)]
train_losses = []
test_losses = []
# Начинаем обучение
for epoch in 1:n_epochs
Flux.train!(loss, model, data, opt_state)
push!(train_losses, loss(model, X_train_norm, y_train_norm))
push!(test_losses, loss(model, X_test_norm, y_test_norm))
end
# Функции для преобразования между масштабами
denormalize_y(y_norm) = y_norm .* y_train_std .+ y_train_mean
denormalize_X(X_norm, dim) = X_norm .* X_train_std[dim] .+ X_train_mean[dim]
test_loss = loss(model, X_test_norm, y_test_norm)
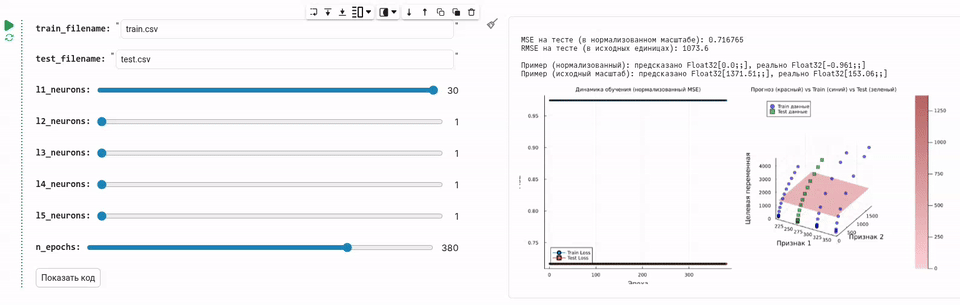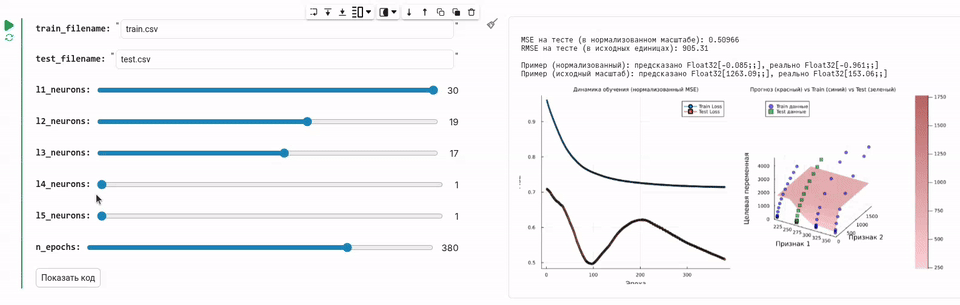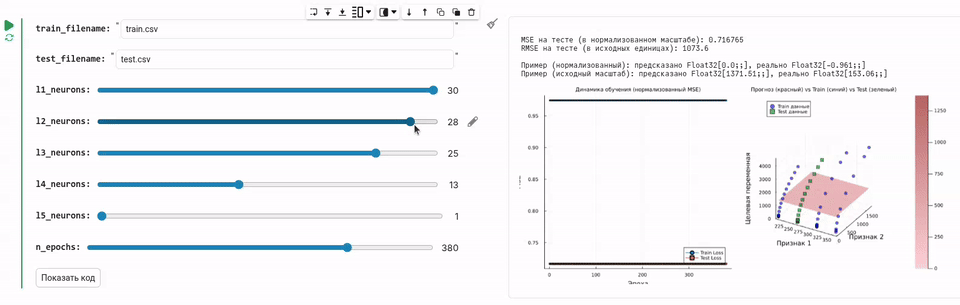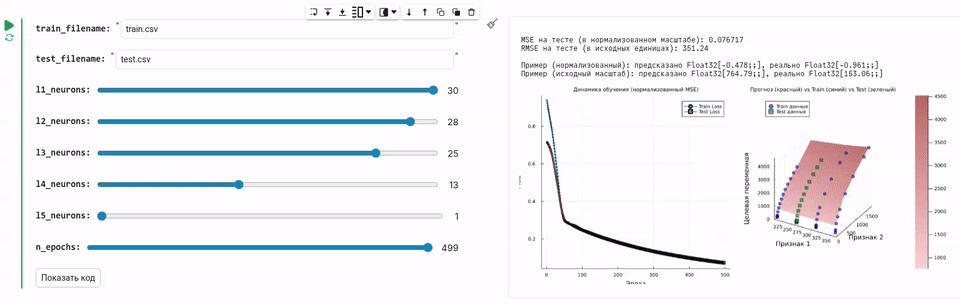
println("\nMSE на тесте (в нормализованном масштабе): $(round(test_loss, digits=6))")
println("RMSE на тесте (в исходных единицах): $(round(sqrt(test_loss) * y_train_std, digits=2))")
# Пример предсказания для первого объекта из теста
prediction_norm = model(X_test_norm[:, 1:1])
actual_norm = y_test_norm[:, 1:1]
prediction = denormalize_y(prediction_norm)
actual = denormalize_y(actual_norm)
println("\nПример (нормализованный): предсказано $(round.(prediction_norm, digits=3)), реально $(round.(actual_norm, digits=3))")
println("Пример (исходный масштаб): предсказано $(round.(prediction, digits=2)), реально $(round.(actual, digits=2))")
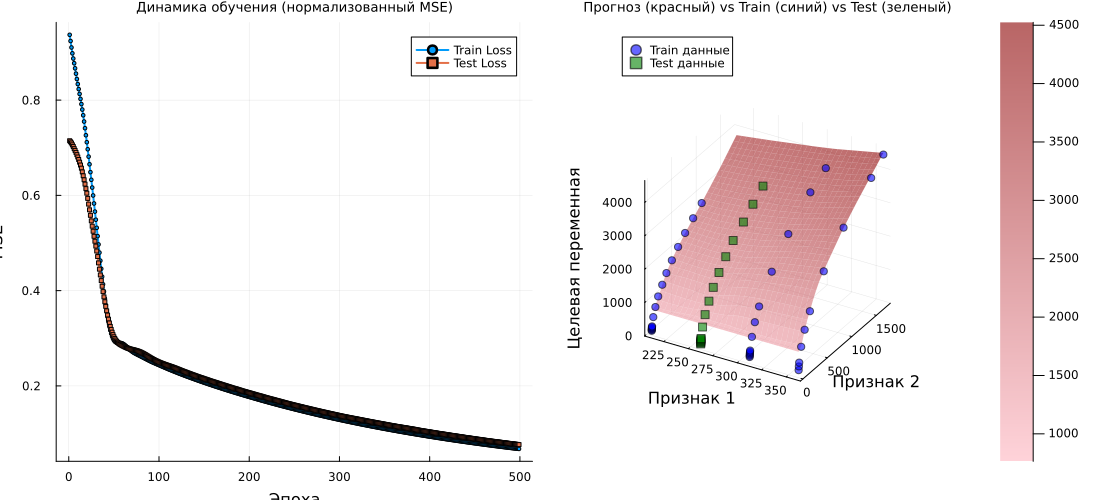
# График 1: Кривые обучения
p1 = plot(1:n_epochs, train_losses, label="Train Loss", lw=2, marker=:circle, markersize=2)
plot!(p1, 1:n_epochs, test_losses, label="Test Loss", lw=2, marker=:square, markersize=2)
title!(p1, "Динамика обучения (нормализованный MSE)")
xlabel!(p1, "Эпоха")
ylabel!(p1, "MSE")
# График 2: 3D поверхность
if features_count >= 2
n_points = 30
# Диапазоны в нормализованном пространстве
x1_range_norm = range(extrema(X_train_norm[1, :])..., length=n_points)
x2_range_norm = range(extrema(X_train_norm[2, :])..., length=n_points)
# Создаем сетку в нормализованном пространстве
grid_x1_norm = repeat(x1_range_norm', n_points, 1)
grid_x2_norm = repeat(x2_range_norm, 1, n_points)
# Для остальных признаков берем средние значения (в нормализованном пространстве)
grid_other_norm = zeros(features_count-2, n_points, n_points)
for i in 3:features_count
grid_other_norm[i-2, :, :] .= mean(X_train_norm[i, :])
end
# Формируем полный набор признаков для сетки (в нормализованном пространстве)
grid_points_norm = vcat(
reshape(grid_x1_norm, 1, n_points, n_points),
reshape(grid_x2_norm, 1, n_points, n_points),
grid_other_norm
)
grid_points_flat_norm = reshape(grid_points_norm, features_count, n_points * n_points)
# Предсказания модели на сетке (в нормализованном масштабе)
predictions_norm = model(grid_points_flat_norm)
predictions_2d_norm = reshape(predictions_norm, n_points, n_points)
# Преобразуем предсказания в исходный масштаб для визуализации
predictions_2d_original = denormalize_y(predictions_2d_norm)
# Преобразуем координаты сетки в исходный масштаб для визуализации
x1_range_original = denormalize_X(x1_range_norm, 1)
x2_range_original = denormalize_X(x2_range_norm, 2)
# Исходные точки данных (train) в исходном масштабе
X1_train_original = denormalize_X(X_train_norm[1, :], 1)
X2_train_original = denormalize_X(X_train_norm[2, :], 2)
y_train_original = vec(denormalize_y(y_train_norm))
# Тестовые точки данных в исходном масштабе
X1_test_original = denormalize_X(X_test_norm[1, :], 1)
X2_test_original = denormalize_X(X_test_norm[2, :], 2)
y_test_original = vec(denormalize_y(y_test_norm))
# Поверхность предсказаний в исходном масштабе
p2 = surface(x1_range_original, x2_range_original, predictions_2d_original,
alpha=0.6, label="Прогноз нейросети",
camera=(30, 30), color=:reds)
# Добавляем тренировочные точки (синие)
scatter!(p2, X1_train_original, X2_train_original, y_train_original,
label="Train данные",
color=:blue,
markersize=4,
alpha=0.7,
markeralpha=0.6)
# Добавляем тестовые точки (зеленые)
scatter!(p2, X1_test_original, X2_test_original, y_test_original,
label="Test данные",
color=:green,
markersize=4,
alpha=0.7,
markeralpha=0.6,
marker=:square)
title!(p2, "Прогноз (красный) vs Train (синий) vs Test (зеленый)")
xlabel!(p2, "Признак 1")
ylabel!(p2, "Признак 2")
zlabel!(p2, "Целевая переменная")
# # Выводим статистику для проверки
# println("\nДиапазоны для визуализации:")
# println("x1: [$(round(minimum(x1_range_original), digits=2)), $(round(maximum(x1_range_original), digits=2))]")
# println("x2: [$(round(minimum(x2_range_original), digits=2)), $(round(maximum(x2_range_original), digits=2))]")
# println("y (предсказания): [$(round(minimum(predictions_2d_original), digits=2)), $(round(maximum(predictions_2d_original), digits=2))]")
# println("y (train): [$(round(minimum(y_train_original), digits=2)), $(round(maximum(y_train_original), digits=2))]")
# println("y (test): [$(round(minimum(y_test_original), digits=2)), $(round(maximum(y_test_original), digits=2))]")
plot(p1, p2, layout=(1, 2), titlefont=font(9), guidesfont=font(7), size=(1100,500))
else
plot(p1, titlefont=font(9), guidesfont=font(7), size=(800,300))
end
Скройте код, щёлкнув дважды на форме для ввода параметров.
Проверьте что автовыполнение ячейки включено (кнопка должна быть зеленой).
И разместите вывод справа от ячейки, если он находится снизу. Ваш инструментарий готов!
Заключение
Код для этой задачи лаконичен и решает конкретную задачу. Но поскольку мы упаковали этот функционал в графический интерфейс, вам просто нужно было выбрать количество нейронов в каждом слое и посмотреть, как меняется качество прогноза.
Это самый быстрый способ, дающий возможность обучить первые 5-10 нейросетей для неизвестных данных и посмотреть, подходит ли этот тип моделей для ваших задач.