Основы анализа текстов: Разреженные модели
Кластеризация документов методом "мешок слов"
В этом примере мы изучим способ представления документов, называемый "мешок слов" (bag of words, BoW). Этот способ перевода документов в числа позволит нам перевести каждый текст в векторное представление. Несмотря на примитивность такого метода векторизации, на его основе можно реализовывать прикладные задачи при условии наличия подходящего набора данных.
В этом проекте мы решим задачу кластеризации, которая не требует учебного и тестового наборов данных, а просто разделяет набор данных на группы на основании их координат в некотором пространстве. Сперва мы изучим, как нам вынести тексты в однородное векторное пространство, затем - как насытить его информацией, и в конце - как посмотреть результат кластеризации множества текстов.
# EngeePkg.purge()
Pkg.add(["XLSX", "Clustering", "MultivariateStats", "TextAnalysis", "SnowballStemmer", "StatsBase"])
using DataFrames, CSV, XLSX
using Statistics, StatsBase, LinearAlgebra, Clustering, Distances, MultivariateStats
using TextAnalysis, SnowballStemmer
stopwords_ru = CSV.read("$(@__DIR__)/stopwords.csv", DataFrame, header=0).Column1;
stemmer_ru = SnowballStemmer.Stemmer("russian");
Мы подготовили окружение и загрузили необходимые объекты - перечень пропускаемых при анализе "стоп-слов" и простейший алгоритм выявления корня слова (чтобы избавляться от словоформ). Приступим к загрузке текстов.
Загрузим тексты
Набором данных, с которым мы поработаем в этом примере, будет таблица с названиями и описаниями примеров из сообщества Engee. Это набор небольших статей на различные технические темы, от радио до экономических расчетов. Названия и краткие описания написаны авторами статей.
Посмотрим, сможем ли мы примитивным BoW выполнить кластеризацию этих текстов.
df = DataFrame(XLSX.readtable("$(@__DIR__)/Сообщество.xlsx", "Сообщество")) # Загружаем таблицу
titles = df.post_title
texts = df.post_title .* ". " .* df.post_description # Берём название и краткое описание
include("$(@__DIR__)/_scripts/doc_statistics.jl")
doc_statistics(texts)
Сразу отметим себе, что тексты довольно короткие. При достаточно вариативном словаре информативность каждого текста будет довольно низкой.
Создание корпуса
Набор анализируемых текстов называется корпусом. Они являются одновременно и объектами, фиксирующими языковую норму, и отдельными экземплярами, которые могут выбиваться из неё. Для начала нам нужно снизить вариативность встречающихся слов. Мы переведем каждый текст в строчный (нижний) регистр и соберем объект Corpus из объектов StringDocument.
using TextAnalysis
corpus = Corpus( StringDocument.(lowercase.(texts)) )
update_lexicon!(corpus)
print("Слов в словаре: $(length(corpus.lexicon))")
Если бы мы сейчас начали работать с этим корпусом, каждый документ мог бы быть представлен вектором из 5220 маркеров, каждый из которых соответствует количеству раз, которое то или иное слово встречается в документе. Сейчас слов гораздо больше, чем документов. Нужно немного упростить это пространство. Для этого мы удалим все числа, пробелы и пунктуацию из текстов и соберем корпус заново:
prepare!(corpus, strip_punctuation | strip_numbers | strip_whitespace )
update_lexicon!(corpus)
print("Слов в словаре: $(length(corpus.lexicon))")
Удалим из него стоп-слова и слова, которые короче двух символов:
corpus.lexicon = Dict( (String(word), Int(freq)) for (word, freq) in corpus.lexicon if (length(word) > 2 && word ∉ stopwords_ru))
print("Слов в словаре: $(length(corpus.lexicon))")
И оставшиеся слова проведем через "стеммер" - алгоритм, обрезающий типичные окончания слов. В словаре останутся только обрезанные конструкции, которые иногда будут совпадать с корнем слова. Но зато мы избавимся от словоформ и сможем работать с более уникальными конструкциями.
using StatsBase
corpus.lexicon = countmap([SnowballStemmer.stem(stemmer_ru, w) for (w,f) in corpus.lexicon for _ in 1:f])
print("Слов в словаре: $(length(corpus.lexicon))")
Каждый документ характеризуется некоторым набором слов. Но для нашего анализа нам не нужны будут уникальные слова, которые не встречаются больше ни в одном другом документе. Отбросим их, отфильтровав из словаря те слова, которые ни к одном документе не встречаются больше одного раза.
corpus.lexicon = Dict( (String(word), Int(freq)) for (word, freq) in corpus.lexicon if freq >= 2)
print("Слов в словаре: $(length(corpus.lexicon))")
Функция dtm() собирает матрицу, в которой каждому документу сопоставляется набор слов из словаря.
dtm = DocumentTermMatrix(corpus) # Признаки × Документы
Мы имеем 850 документов, многие из которых характеризуются одними и теми же словами (вертикальные линии в матрице), поэтому в финальном анализе мы увидим кластеры вокруг неинформативных слов вроде "работа" или "пример".
# BoW (частота слов)
bow_dense = Matrix(dtm[:, :])' # Признаки × Документы
# PCA
pca = fit(PCA, bow_dense; maxoutdim=3)
X_pca = MultivariateStats.predict(pca, bow_dense) # (3, n_docs)
# Визуализация (цвет = количество слов в документе)
scatter(X_pca[1, :], X_pca[2, :], X_pca[3, :], legend=false,
title="BoW проекция", markersize=2, markerstrokewidth=0, alpha=0.7)
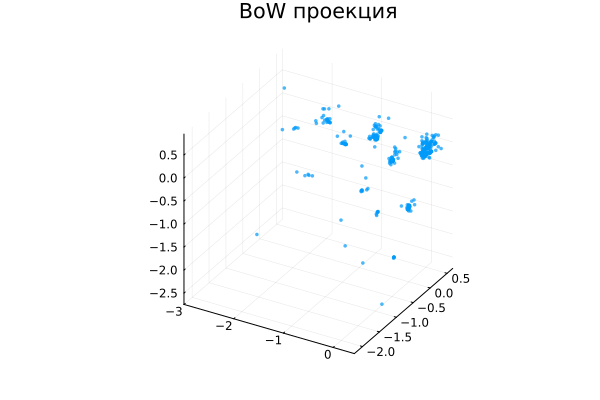
Это не типичный результат для кластеризации документов, хотя его тоже было бы интересно проанализировать. Возможно, это кластеры по длине документов, а дисперсия возникает из-за того, что мы спроецировали данные в пространство сниженной размерности, потеряв часть информации об их вариативности, хотя в исходном многомерном пространстве документы были сильно разбросаны.
Мы расположили все документы в 1458-мерном пространстве. Естественно, чтобы увидеть их на графике нам нужно снизить размерность, и в этом нам поможет PCA - анализ основных компонент векторного пространства. Он находит проекцию, в которой данные наиболее вариативны.
Чтобы подсветить выдающиеся слова, мы продолжим работать с разреженным представлением текста, но попробуем высветить тематику каждого текста. Мы не будем устанавливать связи между словами (плотный анализ текста), а поднимем вес некоторых слов относительно остальных.
Подавление шума при помощи TFIDF
Следующий метод, который нам нужно попробовать применить – это метод "взвешивания" слов в нашем мешке, который называется TFIDF (term frequency, inverse document frequency). Мы добавим веса к словам, чтобы не все они имели одинаковое значение для анализа.
В нашем вектором пространстве документы теперь будут расположены не том же месте, где и остальные документы где есть слово "работа". По осям неинформативных слов документы скатятся ближе в нулю, и эти оси станут неинформативными.
Наиболее выразительными координатами станут числа, характеризующие наличие в документе таких слов, которые редко встречаются во всем корпусе. Чем чаще слово встречается в документе и чем реже оно встречается в корпусе, тем дальше от нуля наш документ будет по координате, соответствующей этому словарному слову.
dtm = DocumentTermMatrix(corpus)
tfidf_mat = tf_idf(dtm)
Простая TFIDF матрица документов выглядит так же как частотная матрица после BoW, но мы видим только наличие или отсутствие числа, а не его значение. Наиболее уникальные или специфичные слова получат больший вес.
# Максимальный вес в одном документе (уникальные/специфичные слова)
vocab = collect(keys(corpus.lexicon))
max_tfidf = maximum(tfidf_mat, dims=2)[:]
top_idx = sortperm(max_tfidf, rev=true)[1:10]
top_words = join(vocab[top_idx], ", ")
Проблема в том, что мы работаем с короткими текстами. Если в тексте от 2 до 23 слов (средняя длина 13), то почти любые слова встречаются редко и будут выглядеть как шум. И все же посмотрим, как теперь располагаются в пространстве наши тексты.
tfidf_dense = Matrix(tfidf_mat)'; # Dimensions: Features × Documents
mean_vec = mean(tfidf_dense, dims=2) # Center the data first
centered_data = tfidf_dense .- mean_vec
pca = fit(PCA, centered_data; maxoutdim=3)
X_pca = MultivariateStats.predict(pca, (tfidf_dense)) # (n_docs, n_components)
scatter(X_pca[1, :], X_pca[2, :], X_pca[3, :], title="Проекция пространства токенов", leg=false,
markersize=2, markerstrokewidth=0, alpha=0.7)
plot!(size=(1000,400), titlefont=font(8))
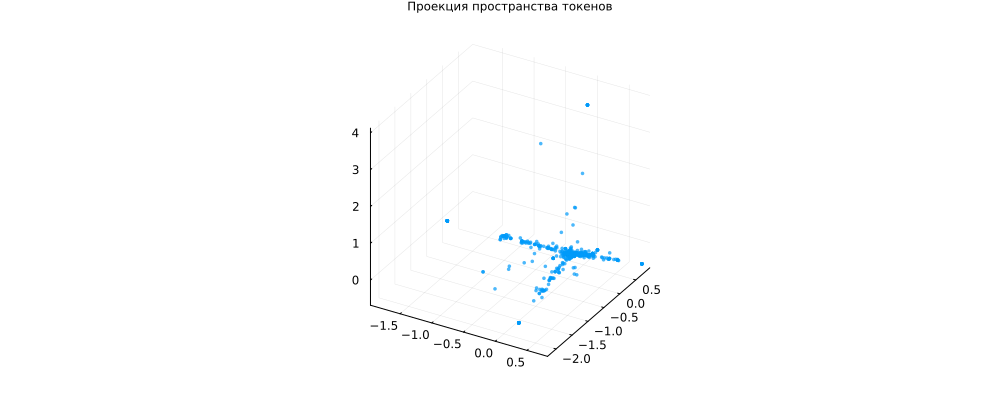
Интересно, что многие тесты находятся в середине системы координат (не репрезентативные), но есть несколько "лучей" - группы слов, которые встречаются вместе и характеризуют свои группы документов. Это характерная картинка для задачи тематического моделирования.
Ничто не гарантирует, что эти группы слов связаны друг с другом, у нас довольно маленький набор данных и короткие тексты, группировка может быть результатом случайного распределения.
К тому же, это группировка после проекции, в исходном пространстве могло не быть никаких "лучей". Но тексты однозначно находились на разном расстоянии от начала координат.
Выполним кластеризацию на заданное нами количество кластеров.
# Кластеризация
k = 5
clusters = kmeans(X_pca, k; distance=CosineDist(), maxiter=500)
# Для каждого кластера находим топ-3 самых удалённых документа
top_ids_list = Dict{Int, Vector{Int}}()
for cluster_id in 1:k
idx_in_cluster = findall(clusters.assignments .== cluster_id)
if isempty(idx_in_cluster); continue; end
center = clusters.centers[:, cluster_id]
distances = [norm(X_pca[:, i] - center) for i in idx_in_cluster]
top_idx = idx_in_cluster[sortperm(distances, rev=true)[1:min(3, end)]]
top_ids_list[cluster_id] = top_idx
end
# Рисуем отдельно каждый кластер с его легендой
p = plot()
for cluster_id in 1:k
idx_in_cluster = findall(clusters.assignments .== cluster_id)
if isempty(idx_in_cluster); continue; end
# Название кластера в легенде
label = string("Класс ", cluster_id, " (", join(top_ids_list[cluster_id], ", "), ")")
scatter!(p, X_pca[1, idx_in_cluster], X_pca[2, idx_in_cluster], X_pca[3, idx_in_cluster],
label=label, markersize=3, alpha=0.6)
end
plot!(p, title="Кластеризация лучей (k=$k)", legend=:outertopright, size=(1000,600))
display(p)
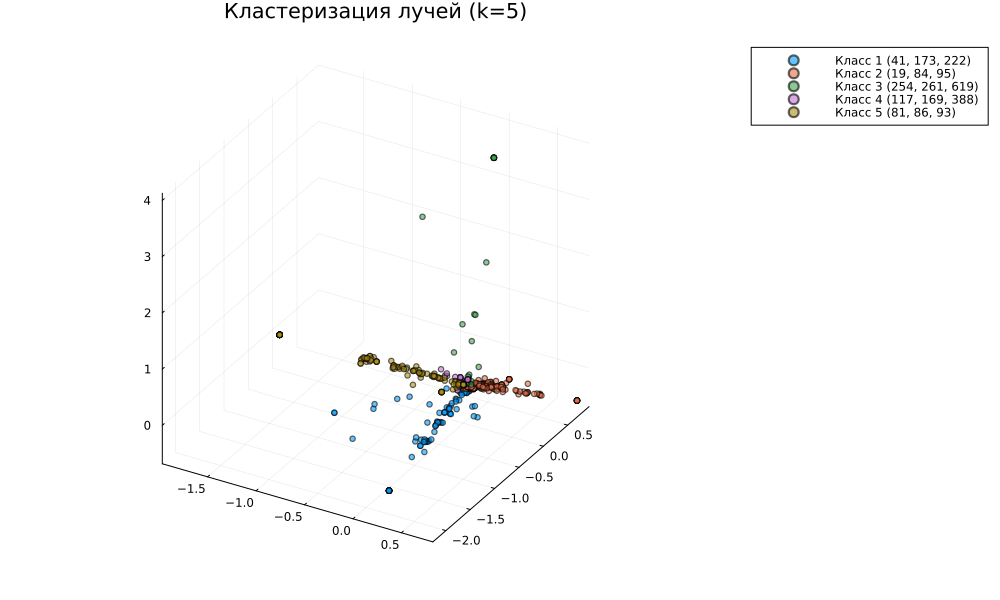
Кластеризация по косинусной метрике, для центрированных данных, позволяет нам кластеризовать документы по их "пространственному углу". Мы попытались сделать так, чтобы отдельные лучи попадали в отдельные кластеры.
Выведем несколько наиболее репрезентативных документов для каждого кластера:
max_docs = 6
for cluster_id in 1:k
idx_in_cluster = findall(clusters.assignments .== cluster_id)
if isempty(idx_in_cluster); continue; end
# Ключевые слова для кластера (периферийные документы)
center = clusters.centers[:, cluster_id]
distances = [norm(X_pca[:, i] - center) for i in idx_in_cluster]
threshold = quantile(distances, 0.7)
peripheral_idx = idx_in_cluster[distances .>= threshold]
# Топ-5 слов из периферии
if !isempty(peripheral_idx)
avg_tfidf = mean(tfidf_mat[peripheral_idx, :], dims=1)[:]
top_idx = sortperm(avg_tfidf, rev=true)[1:min(5, end)]
top_words = vocab[top_idx]
keywords = join(top_words, ", ")
else
keywords = "—"
end
# Топ-3 самых удалённых документа
top_docs = idx_in_cluster[sortperm(distances, rev=true)[1:min(max_docs, end)]]
println("\nКластер $cluster_id ($(length(idx_in_cluster)) док., ключевые: $keywords)")
for (rank, idx) in enumerate(top_docs)
println(" $rank. [$idx] $(titles[idx])")
end
end
Нельзя сказать, чтобы различия бросались в глаза. Посмотрим на статистику:
# Проверим разреженность матрицы
println("Разреженность TF-IDF матрицы: $(1 - SparseArrays.nnz(tfidf_mat)/prod(size(tfidf_mat)))%")
println("Среднее количество ненулевых элементов на документ: $(SparseArrays.nnz(tfidf_mat)/size(tfidf_mat, 1))")
# Посмотрим на дисперсию
row_variances = [var(collect(row)) for row in eachrow(tfidf_mat)]
println("Дисперсия по документам: cредняя $(mean(row_variances))")
println(" медиана $(median(row_variances))")
println(" мин/макс $(minimum(row_variances)) / $(maximum(row_variances))")
Наши документы не очень хорошо поддаются такому виду кластеризации. Высокая разреженность матрицы означает что очень мало документов можно группировать по такому векторному признаку.
Мы также видим, что каждый документ охарактеризован в среднем 1.8 уникальными словами (столько ненулевых элементов в среднем имеет наша матрица). Это очень мало, лучше довести этот показатель до 5-10% от словаря, но поскольку наши тексты очень короткие, мы не сможем это сделать.
Имея 1-2 значимых слова на документ (после стемминга) мы получаем почти нулевую дисперсию - все документы очень бедны на информацию.
Заключение
Разреженные методы анализа текста обычно показывают неплохие результаты во вспомогательных задачах: в фильтрации спама, в идентификации уникальных текстов или символов, в сравнении документов со специфической терминологией, в базовой кластеризации.
Мы с вами также изучили методы предобработки текстов, которые используются на каждом шаге, в каждом прикладном проекте по анализу текстов. Как вы могли убедиться, при помощи десятка функций можем организовывать сравнительно сложную цепочку обработки текстов.