Ансамбль деревьев
Определение влиятельных признаков для модели случайного леса
Введение
В современном анализе данных задача прогнозирования непрерывных величин занимает центральное место во множестве прикладных областей — от экономики и биоинформатики до автостроения и энергетики. Одним из наиболее широко применяемых методов решения подобных задач является случайный лес (Random Forest) — ансамблевый алгоритм машинного обучения, предложенный Лео Брейманом в 2001 году.
Случайный лес представляет собой ансамбль регрессионных деревьев, каждое из которых строится на основе независимой выборки из исходных данных. Базовым элементом здесь выступает регрессионное дерево — иерархическая структура типа «дерево решений», в узлах которой происходит последовательное разбиение пространства признаков на более однородные области. Ансамблирование основано на идее, что объединение множества простых моделей в единую композицию позволяет достичь более высокой точности и устойчивости прогнозов, чем использование любой из них по отдельности.
Отдельной проблемой при построении деревьев решений является наличие пропущенных значений в данных. Для её решения применяется механизм суррогатных расщеплений. Когда оптимальное разбиение по основному признаку невозможно из-за пропуска, алгоритм автоматически подбирает альтернативный признак, разбиение по которому максимально имитирует исходное.
В данном примере представлена стратегия выбора критерия разбиения при построении регрессионного случайного леса. В рамках анализа решается задача идентификации ключевых предсказателей, вносящих наибольший вклад в прогностическую способность модели, что обосновывает их обязательное включение в финальный обучающий набор данных.
Исходные данные
Присоединим необходимые файлы и библиотеки.
#EngeePkg.purge()
#import Pkg
#Pkg.add(["DataFrames", "XLSX", "CategoricalArrays", "MLJ", "MLJDecisionTreeInterface", "StableRNGs", "EvoTrees", "DecisionTree", "Statistics", "Random", "PyPlot"])
using DataFrames, XLSX, CategoricalArrays, MLJ, MLJDecisionTreeInterface, StableRNGs, EvoTrees, DecisionTree, Statistics, Random, PyPlot
foreach(include, filter(contains(r"\.jl$"), readdir()))
Для анализа используется набор данных, содержащий характеристики легковых автомобилей. В рамках исследования строится регрессионная модель, прогнозирующая расход топлива на основе следующих параметров:
- количество цилиндров;
- рабочий объём двигателя;
- мощность;
- масса автомобиля;
- время разгона;
- год выпуска;
- страна происхождения.
X = XLSX.readdata("автомобили.xlsx", "Sheet1", "A:G")
X = DataFrame(X[2:end, :], Symbol.(X[1, :]))
Загрузим данные расхода топлива.
расход_ = XLSX.readdata("расход.xlsx", "Sheet1", "A:A")
Расход = parse.(Float64, расход_[2:end])
Имеется отсутствие данных расхода топлива для некоторых автомобилей. Это будет учитываться в дальнейших вычислениях.
Определение количества уникальных значений признаков
Определим количество уникальных значений каждого признака из набора данных.
for колонка in names(X)
try
X[!, колонка] = [getdata(val) for val in X[!, колонка]]
catch e
X[!, колонка] = categorical(X[!, колонка])
end
end
уникальных = [length(unique(skipmissing(X[!, колонка]))) for колонка in names(X)]
Сравним уникальные значения с помощью столбчатой диаграммы.
график1 = Plots.bar(1:length(уникальных), уникальных,
title = "Количество уникальных значений",
ylabel = "Уникальных значений",
xticks = (1:length(уникальных), names(X)[1:end]),
ylims = (0, maximum(уникальных) * 1.1),
xrotation = 45,
legend = false,
bar_width = 0.7,
color = :steelblue)
display(график1)
На диаграмме видно, что имеются значительные различия количестве уникальных значений признаков. Подобная диспропорция создаёт риск смещения оценок при использовании стандартного алгоритма для выбора переменных расщепления в узлах деревьев случайного леса, поэтому для формирования ансамбля регрессионных деревьев необходимо учитывать взаимосвязь между признаками.
Формирование ансамбля регрессионных деревьев
Для оценки показателей важности признаков, необходимо выполнить обучение ансамбля, состоящего из регрессионных деревьев, с учётом взаимосвязи между признаками. Создадим обучающую выборку.
X_matrix = zeros(Float64, nrow(X), ncol(X))
col_names = names(X)
for (j, col) in enumerate(eachcol(X))
if eltype(col) <: String || eltype(col) <: CategoricalValue
unique_vals = unique(col)
val_to_num = Dict(val => i for (i, val) in enumerate(unique_vals))
X_matrix[:, j] = [Float64(val_to_num[x]) for x in col]
else
X_matrix[:, j] = Float64.(col)
end
end
train_idx = .!isnan.(Расход)
X_train = X_matrix[train_idx, :]
y_train = Расход[train_idx]
println("Размер обучающей выборки: $(size(X_train, 1)) строк")
println("Количество признаков: $(size(X_train, 2))")
Выполним обучение ансамбля.
Random.seed!(1)
деревьев = 200
деревья, yHat_train = build_forest(y_train, X_train, 0, деревьев, 0.632, -1, 5, 2)
valid_pred_idx = .!isnan.(yHat_train)
if sum(valid_pred_idx) > 0
R2 = cor(y_train[valid_pred_idx], yHat_train[valid_pred_idx])^2
println("R² = ", R2)
end
Значение коэффициента детерминации свидетельствует о том, что модель объясняет 87% разброса целевой переменной относительно среднего значения.
Оценка влияния признака
Оценка влияния признаков выполняется путём перестановки вневыборочных наблюдений между деревьями ансамбля.
важность = permutation_importance(деревья, X_train, y_train, 5);
Значение важность представляет собой вектор размера 1×7, содержащий оценки влияния исходных признаков. Особенностью полученных оценок является отсутствие смещения в сторону признаков с большим количеством уникальных значений. Сравним полученные показателей влияния признаков.
график2 = Plots.bar(важность,
title = "Показатели влияния признаков",
xlabel = "Признаки",
ylabel = "Влияние",
xticks = (1:length(уникальных), names(X)[1:end]),
ylims = (0, maximum(важность) * 1.1),
xrotation = 45,
legend = false,
bar_width = 0.7,
color = :steelblue)
display(график2)
Бóльшие значения оценок соответствуют более влиятельным предсказателям. Согласно столбчатой диаграмме, наибольшей прогностической значимостью обладает год выпуска автомобиля, за которой следует масса автомобиля.
Отобразим оценки взаимосвязи признаков, в виде цветовой матрицы.
график3 = imshow(predAssociation, cmap="viridis", aspect="auto", interpolation="nearest")
title("Оценки взаимосвязи признаков")
colorbar(label="Взаимосвязь")
PyPlot.xticks(0:length(col_names)-1, col_names, rotation=45, ha="right")
PyPlot.yticks(0:length(col_names)-1, col_names)
display(график3)
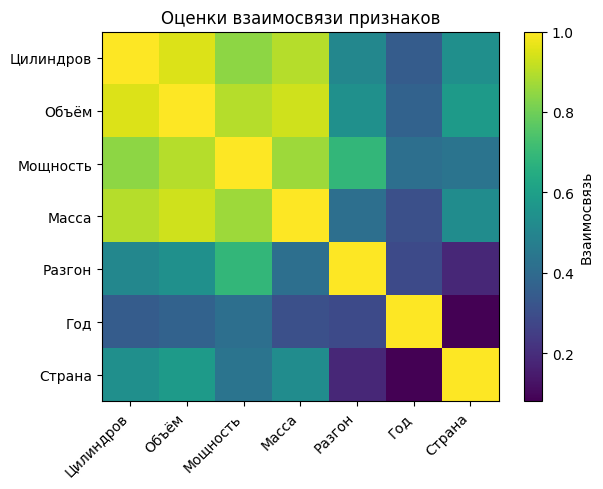
Прогностическая мера взаимосвязи представляет собой показатель, характеризующий степень сходства между решающими правилами, используемыми для разбиения наблюдений. Максимальное значение данной меры достигается для наилучшего суррогатного расщепления.
Элементы матрицы позволяют делать вывод о силе взаимосвязи между признаками: более высокие значения указывают на более сильную корреляцию между соответствующими признаками.
Заключение
В данном примере продемонстрирован подход к построению регрессионного случайного леса с акцентом на корректный отбор влиятельных признаков. На примере набора характеристик автомобилей решена задача прогнозирования расхода топлива — типичная для автомобилестроения задача, где точность модели влияет на инженерные решения.
Механизм суррогатных расщеплений позволил корректно обработать пропуски данных и построить матрицу взаимосвязей признаков, дающую содержательную интерпретацию структуры зависимостей в данных.
Представленная методология универсальна и применима в широком спектре областей: от машиностроения до биоинформатики. Главный практический вывод: корректный учёт природы переменных при выборе критерия разбиения позволяет повысить точность прогнозов и получать содержательные выводы о значимости факторов, свободные от статистических смещений.