Дисперсионный анализ смешанных эффектов
Дисперсионный анализ смешанных эффектов на примере данных об удельном запасе хода автомобилей
Введение
Представьте, что вы — инженер-испытатель, и вам необходимо выяснить, действительно ли разные модели автомобилей различаются по удельному запасу хода, или наблюдаемые отличия — лишь случайность, связанная, например, с особенностями конкретного завода. Ответить на этот вопрос помогает дисперсионный анализ — статистический метод, который раскладывает общую изменчивость данных на части, обусловленные разными источниками. Ключевая идея заключается в следующем: если различия между группами заметно превышают уровень случайного "шума", влияние фактора признаётся значимым.
В данном примере используется смешанная линейная модель. Каждая модель автомобиля выступает как фиксированный эффект, а завод-изготовитель и взаимодействие завода с моделью — как случайные эффекты.
Результатом обучения модели являются компоненты дисперсии, которые количественно описывают вклад каждого источника в общий разброс:
-
(Производитель) — насколько в среднем различаются автомобили разных заводов;
-
(Производитель × Модель) — степень несогласованности эффекта модели от завода к заводу (взаимодействие факторов);
-
(Остаток) — необъяснённый разброс, связанный с индивидуальными особенностями автомобилей и погрешностями измерений.
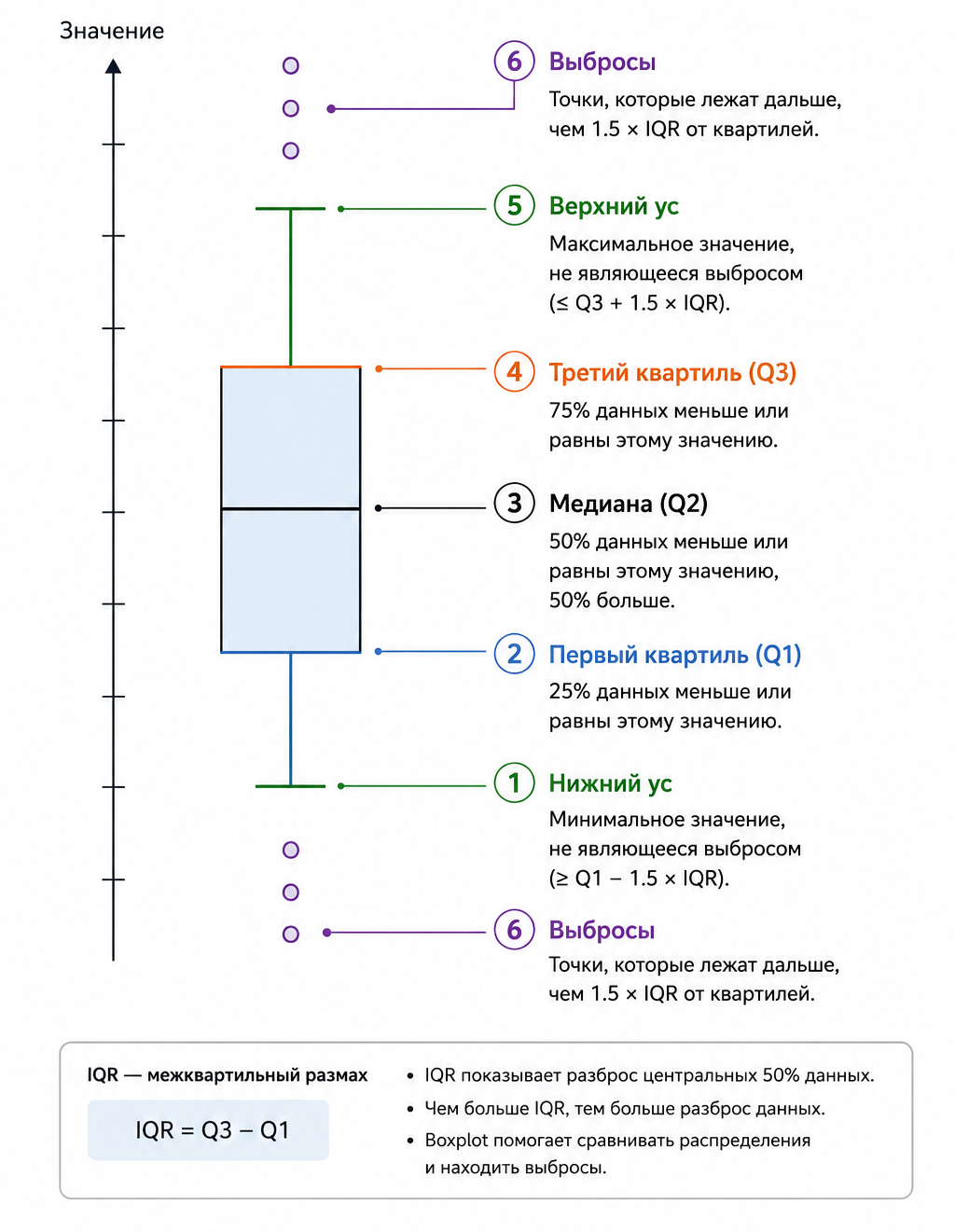
Для наглядного представления данных мы используем ящичковые диаграммы (boxplot, или "ящик с усами"). Этот график компактно отображает медиану, квартили, размах и потенциальные выбросы, позволяя мгновенно оценить центр распределения, его разброс и симметричность в каждой группе.
Формальная проверка гипотез опирается на тест отношения правдоподобия: он сравнивает полную модель с редуцированной (без фиксированного эффекта модели) и определяет, приводит ли исключение модели автомобиля к статистически значимому ухудшению описания данных.
Объединяя возможности дисперсионного анализа смешанных эффектов с выразительной статистической графикой, мы реконструируем объективную картину, скрытую за колонками цифр в протоколах испытаний.
Импорт библиотек
Присоединим библиотеки, необходимые для работы с дисперсионным анализом.
#import Pkg
#Pkg.add(["AnovaGLM", "CSV", "DataFrames", "CategoricalArrays", "MixedModels", "Statistics", "Distributions", "GLM", "StatsPlots"])
using AnovaGLM, CSV, DataFrames, CategoricalArrays, MixedModels, Statistics, Distributions, GLM, StatsPlots
Исходные данные
Определим исходные данные об удельном запасе хода каждой модели автомобиля (пробег). Преобразуем данные в таблицу, в которой данные приведены в соответствие.
# Исходные данные
исходные = [
33.3 34.5 37.4
33.4 34.8 36.8
32.9 33.8 37.6
32.6 33.4 36.6
32.5 33.7 37.0
33.0 33.9 36.7
]
# Параметры плана эксперимента
заводов = 3
строк = 6
моделей = 2
повторов = div(строк, моделей)
пробег = Float64[]
завод = Int[]
модель = Int[]
for з in 1:заводов
for стр in 1:строк
push!(пробег, исходные[стр, з])
push!(завод, з)
push!(модель, стр <= 3 ? 1 : 2)
end
end
# Таблица данных
таблица = DataFrame(
Пробег = пробег,
Завод = string.(завод),
Модель = string.(модель)
)
таблица.Завод = categorical(таблица.Завод)
таблица.Модель = categorical(таблица.Модель)
println("Удельный запас хода автомобилей")
println(first(таблица, 18))
Построение моделей
Построим смешанную линейную модель, в которой пробег объясняется фиксированным эффектом модели автомобиля и случайными эффектами завода и взаимодействия завода с моделью. Выполним подбор параметров модели методом максимального правдоподобия и проанализируем полученные оценки компонент дисперсии и фиксированных эффектов.
формула1 = @formula(Пробег ~ 1 + Модель + (1 | Завод) + (1 | Завод & Модель))
подбор1 = fit(MixedModel, формула1, таблица)
println(подбор1)
Построим редуцированную смешанную модель без фиксированного эффекта модели автомобиля, оставив только случайные эффекты завода и взаимодействия. Выполним тест отношения правдоподобия между полной и редуцированной моделями, чтобы статистически проверить значимость влияния модели автомобиля на пробег.
формула0 = @formula(Пробег ~ 1 + (1 | Завод) + (1 | Завод & Модель))
подбор0 = fit(MixedModel, формула0, таблица)
тест_правд = MixedModels.likelihoodratiotest(подбор0, подбор1)
println("Результаты теста отношения правдоподобия:")
println(тест_правд)
Оценки компонентов дисперсии
Выполним извлечение компонент дисперсии из обученной модели с помощью функции VarCorr, сохраним числовые значения дисперсий для каждого случайного эффекта в удобную структуру данных.
компоненты = VarCorr(подбор1)
println(компоненты)
# Функция для извлечения дисперсий
function извлечь_дисперсии(vc)
строка_vc = string(vc)
дисперсии = Dict{String, Float64}()
for line in split(строка_vc, "\n")
очищенная = strip(line)
if isempty(очищенная)
continue
end
if occursin("Variance components:", очищенная) ||
occursin("Column", очищенная) ||
(occursin("Variance", очищенная) && occursin("Std.Dev.", очищенная)) ||
startswith(очищенная, "──")
continue
end
части = split(очищенная, r"\s+")
if length(части) >= 3
предпоследнее = части[end-1]
if occursin(r"^\d+\.?\d*$", предпоследнее) || occursin(r"^\d*\.?\d+$", предпоследнее)
зн = tryparse(Float64, предпоследнее)
if зн !== nothing
имя = join(части[1:end-2], " ")
дисперсии[имя] = зн
end
end
end
end
return дисперсии
end
дисп = извлечь_дисперсии(компоненты)
σ²_завод = 0.0
σ²_взаимодействие = 0.0
σ²_остаток = 0.0
for (k, v) in дисп
if occursin("Производитель & Модель", k)
σ²_взаимодействие = v
elseif occursin("Производитель", k) && !occursin("Модель", k)
σ²_завод = v
elseif occursin("Residual", k)
σ²_остаток = v
end
end
println("Оценки дисперсий случайных эффектов:")
println(" σ²(Производитель) = ", round(σ²_завод, digits=4))
println(" σ²(Производитель:Модель) = ", round(σ²_взаимодействие, digits=4))
println(" σ²(Ошибка) = ", round(σ²_остаток, digits=4))
Визуализация результатов
Настроим визуальное оформление графиков.
theme(:default)
default(fontfamily="sans-serif", titlefontsize=11, guidefontsize=9, tickfontsize=7)
цвета_заводов = [:steelblue, :darkorange, :forestgreen]
цвета_комп = [:steelblue, :darkorange, :forestgreen]
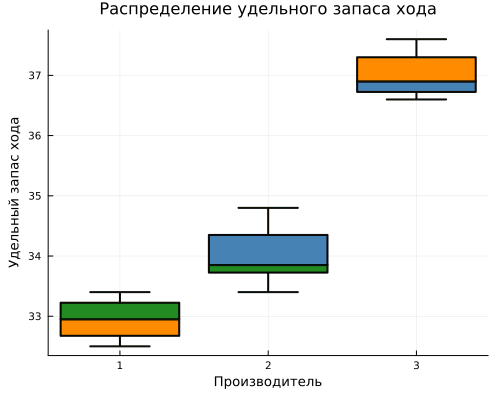
С помощью boxplot построим распределение удельного запаса хода автомобилей по каждому производителю.
gr()
гр1 = @df таблица boxplot(:Завод, :Пробег,
legend=false,
title="Распределение удельного запаса хода",
xlabel="Производитель",
ylabel="Удельный запас хода",
color=цвета_заводов,
linewidth=2,
size=(500, 400))
display(гр1)
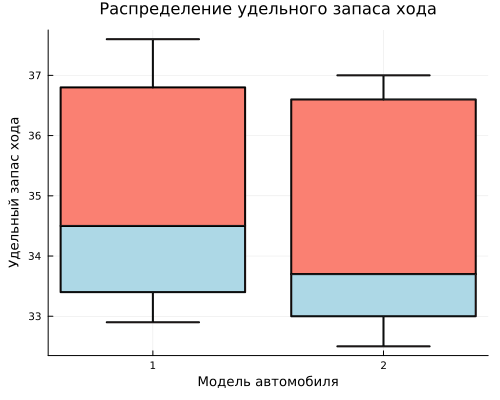
Построим распределение удельного запаса хода автомобилей по каждой модели.
гр2 = @df таблица boxplot(:Модель, :Пробег,
legend=false,
title="Распределение удельного запаса хода",
xlabel="Модель автомобиля",
ylabel="Удельный запас хода",
color=[:salmon, :lightblue],
linewidth=2,
size=(500, 400))
display(гр2)
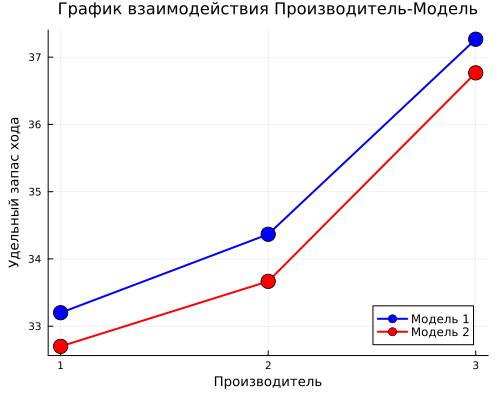
Построим график взаимодействия Производитель-Модель
средние_зм = combine(groupby(таблица, [:Завод, :Модель]), :Пробег => mean => :Средний)
средние_зм.Завод = string.(средние_зм.Завод)
средние_зм.Модель = string.(средние_зм.Модель)
гр3 = plot(legend=:bottomright, size=(500, 400),
title="График взаимодействия Производитель-Модель",
xlabel="Производитель",
ylabel="Удельный запас хода")
цвета_моделей = [:blue, :red]
for (i, мод) in enumerate(["1", "2"])
данные = средние_зм[средние_зм.Модель .== мод, :]
plot!(гр3, данные.Завод, данные.Средний,
marker=:circle, markersize=8, linewidth=2,
color=цвета_моделей[i],
label="Модель $мод")
end
display(гр3)
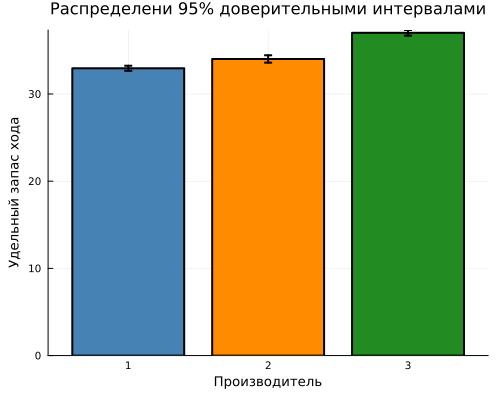
Сгруппируем данные по производителям и для каждого вычислим удельный запас хода, стандартное отклонение и количество наблюдений. Вычислим стандартную ошибку среднего и 95% доверительные интервалы. Построим столбчатую диаграмму со средними значениями и диапазонами ошибок, чтобы наглядно сравнить производителей по удельному запасу хода и оценить точность полученных оценок.
стат_завод = combine(groupby(таблица, :Завод),
:Пробег => mean => :Среднее,
:Пробег => std => :СтОткл,
:Пробег => length => :N)
стат_завод.Завод = string.(стат_завод.Завод)
стат_завод.СтОшибка = стат_завод.СтОткл ./ sqrt.(стат_завод.N)
стат_завод.ДИ = 1.96 .* стат_завод.СтОшибка
гр4 = bar(стат_завод.Завод, стат_завод.Среднее,
yerror=стат_завод.ДИ,
legend=false,
title="Распределени 95% доверительными интервалами",
xlabel="Производитель",
ylabel="Удельный запас хода",
color=цвета_заводов,
linewidth=2,
size=(500, 400))
display(гр4)
println()
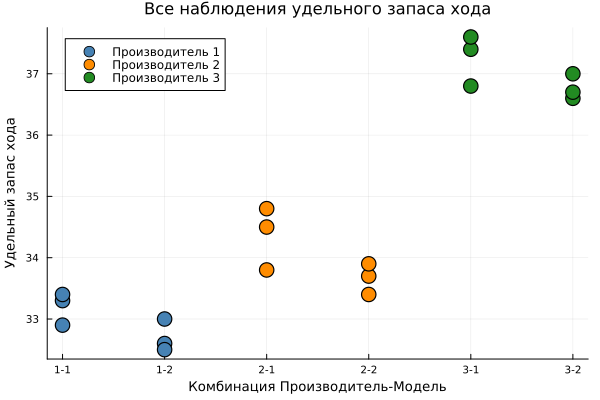
Построим диаграмму рассеяния всех наблюдений
таблица.Группа = string.(таблица.Завод) .* "-" .* string.(таблица.Модель)
таблица.Группа = categorical(таблица.Группа)
гр5 = plot(legend=:topleft, size=(600, 400),
title="Все наблюдения удельного запаса хода",
xlabel="Комбинация Производитель-Модель",
ylabel="Удельный запас хода")
for (i, з) in enumerate(["1", "2", "3"])
данные = таблица[таблица.Завод .== з, :]
scatter!(гр5, данные.Группа, данные.Пробег,
label="Производитель $з",
color=цвета_заводов[i],
markersize=8,
markerstrokewidth=1.5)
end
display(гр5)
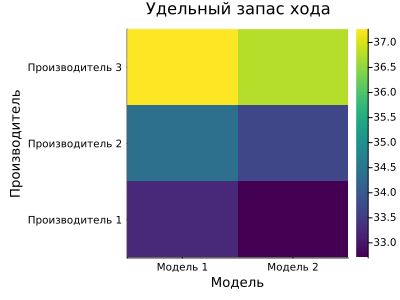
Построим тепловую карту распределения удельного запаса хода по моделям и производителям.
матрица_средних = zeros(заводов, моделей)
for з in 1:заводов
for м in 1:моделей
маска = (таблица.Завод .== string(з)) .& (таблица.Модель .== string(м))
матрица_средних[з, м] = mean(таблица.Пробег[маска])
end
end
гр6 = heatmap(["Модель 1", "Модель 2"],
["Производитель 1", "Производитель 2", "Производитель 3"],
матрица_средних,
title="Удельный запас хода",
xlabel="Модель",
ylabel="Производитель",
color=:viridis,
size=(400, 300))
display(гр6)
Заключение
Проведённый анализ позволил количественно разделить изменчивость удельного запаса хода на составляющие, связанные с моделью автомобиля, заводом-изготовителем и их взаимодействием. Тест отношения правдоподобия дал формальный ответ на вопрос о значимости фиксированного эффекта модели, а графическое сопровождение — от ящичковых диаграмм до тепловой карты — сделало эти выводы наглядными и доступными для интерпретации. Теперь инженер-испытатель может опираться не на интуицию, а на статистически обоснованные оценки: стоит ли модернизировать конструкцию модели или направить усилия на унификацию производственных процессов между заводами.
Рассмотренный метод универсален и выходит далеко за пределы автомобильной промышленности. В фармацевтике он применяется для оценки воспроизводимости действия препарата между разными производственными площадками: в сельском хозяйстве — чтобы разделить влияние сорта растения, типа почвы и их взаимодействия на урожайность; в психологии и образовании — когда нужно учесть одновременно индивидуальные различия испытуемых и эффект экспериментального воздействия. Всюду, где данные имеют иерархическую структуру (образцы внутри партий, пациенты внутри клиник, ученики внутри классов), смешанные модели становятся незаменимым инструментом, позволяющим корректно оценить интересующие эффекты и избежать ложных выводов из-за игнорирования групповой структуры изменчивости.
Таким образом, освоение техники, продемонстрированной в данном примере, предоставляет универсальную возможность для анализа сложно организованных данных в самых разных предметных областях.