Генерируем код из свёрточной нейросети
Встраиваемый код из свёрточной нейросети
Обучим нейросеть игрушечной задаче - предсказывать геометрические фигуры, и проверим, можно ли скомпилировать ее в код на Си, а затем и в бинарную библиотеку чтобы использовать в блоках или как часть другого проекта.
Введение
В этом практическом руководстве мы обучим нейросеть распознавать геометрические фигуры на игрушечном датасете, а затем экспортируем обученную модель в код на C, скомпилируем его в разделяемую библиотеку и проверим возможность интеграции в сторонние проекты или блоки кода на Си в вашем проекте.
В ходе конвертации вы заметите небольшую потерю точности. Это может быть вызвано разницей в реализации некоторых операций в Julia и в C (например, батч-нормализация) или простым округлением коэффициентов при переводе в код, но зато открывает путь к развёртыванию на встраиваемых системах.
Подготовка
На этом этапе мы загружаем необходимые библиотеки, фиксируем генератор случайных чисел, создаём синтетический датасет из квадратов, кругов и треугольников, а затем визуализируем примеры изображений каждого класса.
Генерация контролируемого, сбалансированного датасета с известными свойствами (размер 64×64, нормализация в диапазон [-1,1]) позволяет изолированно проверить каждый этап конвейера без влияния внешних факторов.
Установим нужные библиотеки и инициализируем генератор случайных чисел, чтобы наш эксперимент был легко возпроизводимым:
# Установка необходимых пакетов
# Pkg.add(["Flux", "BSON", "ImageTransformations"])
using Random
Random.seed!(5);
Синтезируем набор данных
Создадим игрушечный датасет, состоящий из трех классов. Часть объектов помещается в папку "неизвестно", то есть их класс, хоть он и прописан в названии файлов, системе будет неизвестен. Можно назвать это валидационным датасетом. Остальные - тренировочный и тестовый - разложены по соответствующим папкам.
include("$(@__DIR__)/_scripts/generate_shape_dataset.jl")
generate_shape_dataset(samples_per_class=200, test_samples=30, img_size=64)
На этом этапе мы стараемся сгенерировать достаточно разнообразный датасет (с поворотами треугольников), но при этом не переусложнять код, например мы не стали делать аугментацию в процессе обучения. В целом, этот этап оказался наименее проблемным.
Взгляд на учебный набор данных
Вот образцы объектов из нашего учебного набора данных:
include("$(@__DIR__)/_scripts/show_dataset_samples.jl")
DATA_DIR = "$(@__DIR__)/учебные данные";
gr()
show_dataset_samples(DATA_DIR, samples_per_class=10)

Обучение и анализ модели
Здесь мы запускаем процесс обучения свёрточной нейросети, сохраняем историю метрик, анализируем динамику точности и потерь, а также отображаем мозаику предсказаний на тестовых изображениях.
Мониторинг метрик precision/recall по классам и ранняя остановка по валидационной точности помогают вовремя обнаружить переобучение и выбрать лучшую модель для последующего экспорта.
include("$(@__DIR__)/_scripts/train_model.jl");
DATA_DIR = "$(@__DIR__)/учебные данные";
model, classes = train_model(DATA_DIR; epochs=100, imsize=64, batch_size=32, lr=0.0005, test_split=0.25, patience_limit=8);
Посмотрим на качество проведенного обучения:
include("$(@__DIR__)/_scripts/analyze_training_log.jl")
gr()
df, classes, p = analyze_training_log("training_log.txt")
display(p)

Каждый график интересно интерпретировать по-отдельности. Например, precision рос для всех классов практически одинаково, но показатель recall сразу стал лучше для квадратов, и всегда был позади для треугольников, оставаясь не самым высоким и к концу процесса обучения.
Мы не стали продолжать обучение после достижения качества 100% на тесте, потому что исчез смысл сравнивать реализации между собой. Но нам определенно стоило бы породить больше объектов для датасета, поскольку, в среднем, к концу обучения модель достаточно точно определяла квадраты и круги, но из пяти предложенных треугольников в среднем "не замечала" один из них. Хотя те, которе она отмечала как треугольники действительно ими были (больше ошибок "ложного срабатывания" сеть демонстрировала для класса "круг").
Прогнозы от нейросети на Julia (Flux)
include("$(@__DIR__)/_scripts/simple_mosaic.jl")
UNKNOWN_DIR = "$(@__DIR__)/неизвестно";
gr()
plot(create_simple_mosaic(UNKNOWN_DIR, imsize=64))
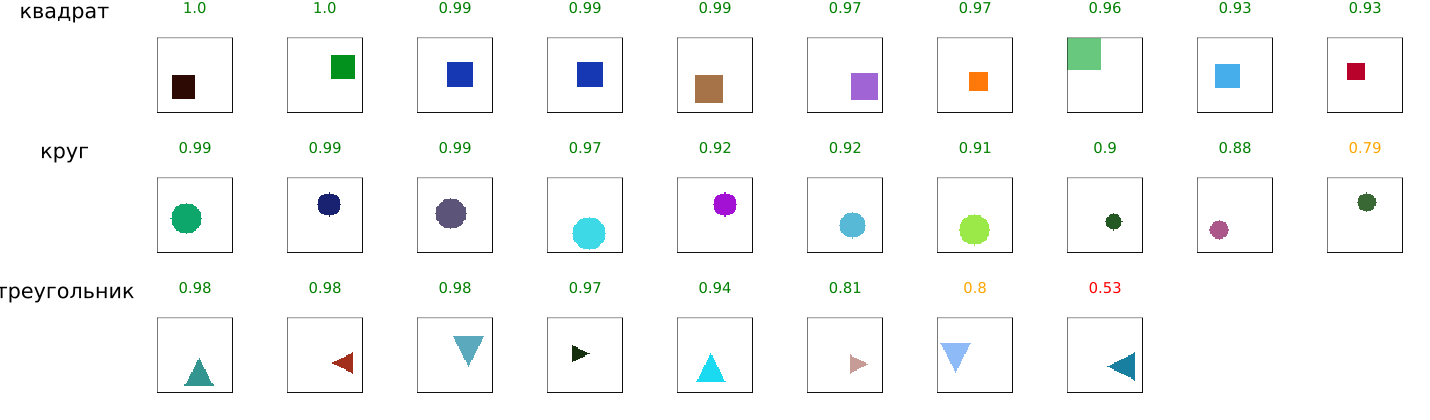
Мы видим довольно хорошие предсказания, но это не столько результат успешного обучения, сколько результат долгой работы проектировщика. Самым трудоёмким оказался подбор архитектуры сети (количество слоёв, каналов, использование BatchNorm и Dropout) и гиперпараметров (скорость обучения, размер батча, аугментация), чтобы достичь стабильной сходимости и избежать переобучения на ограниченном наборе данных. В итоге, например, аугментация была перенесена в функцию порождающую датасет, чтобы упростить пример, а также в силу того, что эта процедура нужна только треугольникам.
Экспорт в C и тестирование
Теперь мы конвертируем предварительно обработанные изображения в бинарный формат, генерируем C-код нейросети, компилируем его в исполняемый файл и визуализируем предсказания, полученные от C-реализации. Мы заведомо предполагаем, что код будет работать на платформах, где нет библиотеки PNG. Поэтому переводим изображения в бинарный формат при помощи отдельного скрипта. В этих бинарных файлах лежат матрицы, в качестве элементов которых фигурирует каждый цветовой канал каждого пикселя, представленный одним числом UInt8.
include("$(@__DIR__)/_scripts/convert_png_to_rgb8.jl")
convert_png_to_rgb8("$(@__DIR__)/неизвестно", "$(@__DIR__)/неизвестно_rgb8", 64)
Теперь, когда у нас готов датасет с бинарными изображениями, можно загрузить уже обученную модель и перевести ее в код на Си. Ключевое требование к успешному экспорту — полное согласование форматов данных (RGB8 для изображений, HWC порядок коэффициентов) и порядка обхода весов между Julia и C, что достигается явным контролем индексации и нормализации на всех этапах.
include("$(@__DIR__)/_scripts/generate_cnn_code.jl")
using Flux, BSON
BSON.@load "$(@__DIR__)/model.bson" model classes
model = Flux.testmode!(model)
# Генерируем библиотеку и main программу
generate_shared_lib(model, 64, length(classes))
generate_main_program(64, length(classes))
Саму нейросеть мы скомпилируем в библиотеку. Мы также сгенерировали программу main, которая подаёт в нейросеть изображения из папки "неизвестно_rgb8" и обрабатывает результаты классификации.
;gcc -shared -fPIC neural_net.c -o libneuralnet.so -lm
;gcc main.c -o classify_unknown -ldl -lm
Что любопытно, чтобы запустить эту нейросеть, нам не потребуются никакие библиотеки - ни Julia, ни C. Она выполняется на любой системе, где есть компилятор кода на Си.
;./classify_unknown
При переносе модели в C пришлось решить несколько нетривиальных задач: ручная реализация свёрток и BatchNorm без сторонних библиотек, приведение всех операций к единому формату HWC, точное воспроизведение порядка обхода весов (особенно критичного для многоканальных слоёв), а также работа с бинарными файлами изображений из-за отсутствия библиотеки PNG в целевой среде — все эти трудности были успешно преодолены.
Прогнозы от нейросети на Си
include("$(@__DIR__)/_scripts/create_mosaic_from_c_predictions.jl")
run(pipeline(`./classify_unknown`, stdout="pred.txt"))
UNKNOWN_DIR = "$(@__DIR__)/неизвестно";
gr()
mosaic_grouped = create_mosaic_from_c_predictions("неизвестно", "pred.txt", max_images=8)
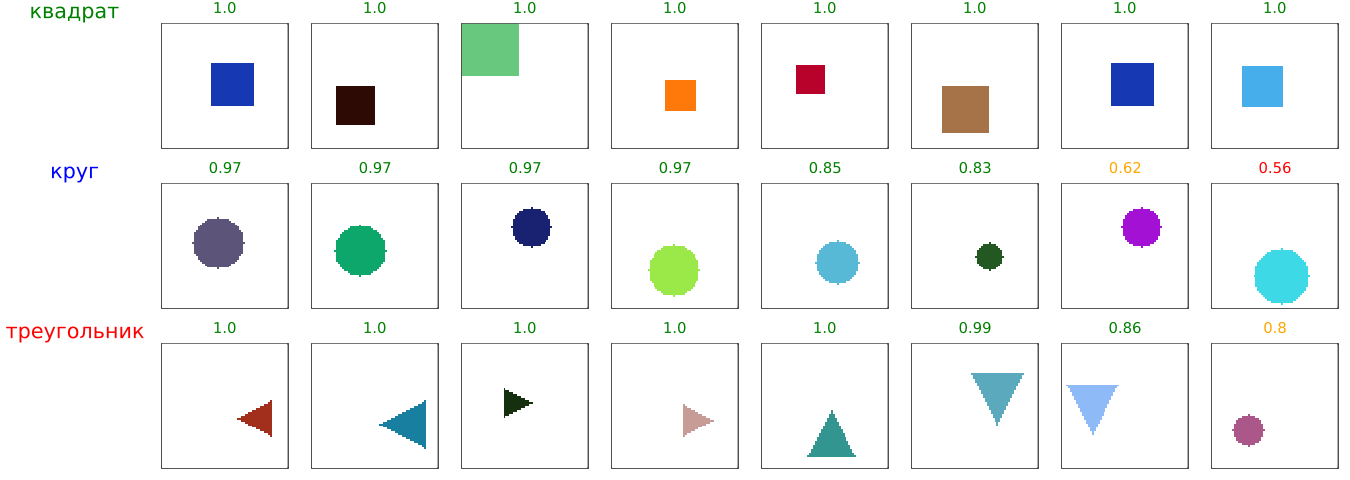
Несмотря на перечисленные сложности, мы продемонстрировали полный рабочий конвейер, доказывающий, что экспорт нейросетей из Julia в C возможен даже при ограниченных ресурсах целевой платформы.
include("$(@__DIR__)/_scripts/predict_to_csv.jl")
UNKNOWN_DIR = "$(@__DIR__)/неизвестно";
predict_to_csv(UNKNOWN_DIR, confidence_threshold=0.4, output_csv="$(@__DIR__)/predictions.csv")
run(pipeline(`./classify_unknown`, stdout="pred.txt"))
include("$(@__DIR__)/_scripts/compare_c_and_julia.jl")
df = compare_c_and_julia()
sort(df)
Заключение
Мы показали, как пройти полный цикл создания программы с нейросетью внутри: от создания датасета и обучения модели на Julia до экспорта в C и проверки работоспособности, что подтверждает принципиальную возможность использования сгенерированного кода далеко за пределами инженерной платформы Engee.