Обнаружение и сопоставление ключевых точек
Обнаружение и сопоставление ключевых точек
В современной компьютерном зрении ключевой задачей является поиск геометрических соответствий между изображениями. Будь то создание панорам, отслеживание движения объекта или реконструкция 3D-сцены по фотографиям, основа всего этого процесса — детектирование уникальных точек и их сопоставление (matching).
Представленный код представляет собой учебную, но функциональную реализацию классического конвейера (pipeline) обнаружения и сопоставления признаков. В отличие от использования «черного ящика» готовых библиотек (например, OpenCV), данный пример на языке Julia демонстрирует ручное программирование. Он не только показывает, как применять алгоритмы, но и раскрывает математическую суть и алгоритмические детали каждого этапа.
Далее подключим библиотеки:
- Images: Базовый пакет для работы с изображениями, предоставляющий типы данных и основные функции ввода-вывода.
- TestImages: Библиотека стандартных тестовых изображений.
- ImageFeatures: Содержит готовые алгоритмы детекции ключевых точек, хотя в данном примере реализована своя версия детектора Харриса.
- ImageDraw: Предназначен для отрисовки графических примитивов, функции которых в коде заменены ручной реализацией для обучающих целей.
- ImageFiltering: Предоставляет инструменты фильтрации и свёртки, необходимые для вычисления градиентов оператором Собеля.
- CoordinateTransformations: Фреймворк для описания и композиции геометрических преобразований координатного пространства.
- Rotations: Специализированный пакет для работы с матрицами поворота и вращения в задачах компьютерного зрения.
- StaticArrays: Обеспечивает высокопроизводительные массивы фиксированного размера для эффективной векторной математики.
- LinearAlgebra: Стандартная библиотека линейной алгебры, применяемая для решения систем уравнений при оценке гомографии.
- Statistics: Стандартный модуль для вычисления статистических метрик, таких как среднее и стандартное отклонение дескрипторов.
# Pkg.add(["Images", "TestImages", "ImageFeatures", "ImageDraw", "ImageFiltering", "CoordinateTransformations", "Rotations", "StaticArrays"])
using Images, TestImages, CoordinateTransformations, Rotations, StaticArrays, LinearAlgebra, Statistics
Далее выполним детальный разбор вспомогательных функций отрисовки, обе функции реализуют классические алгоритмы Брезенхема — эффективные методы растеризации геометрических примитивов с использованием только целочисленной арифметики.
Функция draw_line!: Алгоритм Брезенхема для отрисовки линии. Алгоритм строит линию между точками и , выбирая на каждом шаге пиксель, наиболее близкий к идеальной прямой.
Уравнение прямой:
Вместо вычисления (что требует деления и плавающей арифметики), Брезенхем использует функцию невязки (error term), которая показывает отклонение текущего пикселя от идеальной линии.
Также на каждом шаге алгоритм оценивает, насколько текущая точка отклоняется от идеальной прямой. Функция невязки обновляется по правилам:
Умножение на 2 (e2 = 2 * err) позволяет избежать работы с дробными числами, сохраняя точность сравнения.
Функция draw_circle!: Алгоритм средней точки (Midpoint Circle Algorithm). Алгоритм строит окружность радиуса с центром , используя восьмипутевую симметрию: если точка лежит на окружности, то симметричные ей точки также принадлежат ей:
Уравнение окружности:
Функция принятия решения (decision parameter) оценивает положение средней точки между двумя кандидатами:
Формулы обновления параметра решения
Параметр обновляется рекуррентно, без вычисления квадратов на каждом шаге:
Эти формулы получаются разложением и исключением повторяющихся вычислений.
function draw_line!(img, p1, p2, color)
x1, y1 = round(Int, p1[1]), round(Int, p1[2])
x2, y2 = round(Int, p2[1]), round(Int, p2[2])
dx = abs(x2 - x1)
dy = abs(y2 - y1)
sx = x1 < x2 ? 1 : -1
sy = y1 < y2 ? 1 : -1
err = dx - dy
x, y = x1, y1
while true
if 1 <= x <= size(img,2) && 1 <= y <= size(img,1)
img[y, x] = color
end
if x == x2 && y == y2
break
end
e2 = 2 * err
if e2 > -dy
err -= dy
x += sx
end
if e2 < dx
err += dx
y += sy
end
end
end
function draw_circle!(img, center, radius, color)
cx, cy = round(Int, center[1]), round(Int, center[2])
r = radius
x = 0
y = r
d = 3 - 2r
while x <= y
for (dx, dy) in [(x, y), (y, x), (-x, y), (-y, x), (x, -y), (y, -x), (-x, -y), (-y, -x)]
px = cx + dx
py = cy + dy
if 1 <= px <= size(img,2) && 1 <= py <= size(img,1)
img[py, px] = color
end
end
if d < 0
d += 4x + 6
else
d += 4(x - y) + 10
y -= 1
end
x += 1
end
end
Детектор углов Харриса: harris_corners
Эта функция реализует классический алгоритм Харриса-Стивенса (1988) для обнаружения углов — характерных точек изображения, которые устойчивы к поворотам, изменению освещения и небольшим геометрическим искажениям.
Угол — это точка, где интенсивность изображения значительно меняется в двух направлениях одновременно. Алгоритм анализирует локальное окно вокруг каждого пикселя и оценивает, насколько оно «угловое».
Матрица второго момента (Structure Tensor), для каждого пикселя строится матрица :
Где:
- — градиенты изображения по осям X и Y
- Суммирование ведётся по окну вокруг пикселя (в коде — окно 3×3)
Анализ собственных значений матрицы :
| Тип области | Визуально | ||
|---|---|---|---|
| Плоская | Малое | Малое | Однородная область |
| Граница | Большое | Малое | Край объекта |
| Угол | Большое | Большое | Пересечение границ |
Вместо вычисления собственных значений (дорогая операция), используется аппроксимация:
Где:
- — эмпирический коэффициент (обычно 0.04–0.06)
Интерпретация отклика:
- → Угол (оба собственных значения большие)
- → Граница (одно большое, одно малое)
- → Плоская область (оба малые)
📊 Визуализация работы детектора
Исходное изображение → Градиенты → Матрица M → Отклик R → Порог → Локальные максимумы
[512×512] [Ix, Iy] [Sxx,Sxy,Syy] [R] [>1% max] [5×5 окно]
Пример откликов в разных областях:
| Область | Тип | ||||
|---|---|---|---|---|---|
| Плоская | 0.1 | 0.1 | 0.0 | ~0.01 | ❌ |
| Граница | 10.0 | 0.1 | 0.5 | ~−0.4 | ❌ |
| Угол | 10.0 | 10.0 | 2.0 | ~+96 | ✅ |
⚙️ Параметры и их влияние
| Параметр | Значение по умолчанию | Эффект увеличения | Эффект уменьшения |
|---|---|---|---|
k |
0.04 | Меньше углов, только самые выраженные | Больше углов, выше чувствительность к шуму |
threshold |
0.01 | Только сильные углы (10% от максимума) | Больше углов, включая слабые |
| Окно сглаживания | 3×3 | Более устойчиво к шуму | Лучшая локализация, но шумнее |
| Окно NMS | 5×5 | Более разреженные точки | Плотнее точки, возможны дубликаты |
function harris_corners(img; k=0.04, threshold=0.01)
img_f = Float64.(img)
img_f = replace(img_f, NaN => 0.0, Inf => 0.0, -Inf => 0.0)
Ix = imfilter(img_f, Kernel.sobel()[1])
Iy = imfilter(img_f, Kernel.sobel()[2])
Ixx = Ix.^2
Iyy = Iy.^2
Ixy = Ix .* Iy
window = ones(3,3) ./ 9
Sxx = imfilter(Ixx, window)
Syy = imfilter(Iyy, window)
Sxy = imfilter(Ixy, window)
det = Sxx .* Syy - Sxy.^2
trace = Sxx + Syy
response = det - k * trace.^2
max_resp = maximum(response)
corners = findall(response .> threshold * max_resp)
local_max = []
for c in corners
i, j = c.I
val = response[i,j]
r_min = max(1, i-2)
r_max = min(size(img,1), i+2)
c_min = max(1, j-2)
c_max = min(size(img,2), j+2)
window_vals = response[r_min:r_max, c_min:c_max]
if all(val .>= window_vals)
push!(local_max, (j, i))
end
end
return local_max
end
Пошаговый разбор кода
Шаг 1: Подготовка изображения
img_f = Float64.(img)
img_f = replace(img_f, NaN => 0.0, Inf => 0.0, -Inf => 0.0)
Зачем: Конвертация в Float64 необходима для точных вычислений градиентов. Замена NaN/Inf защищает от артефактов после геометрических трансформаций (warp).
Шаг 2: Вычисление градиентов (Оператор Собеля)
Ix = imfilter(img_f, Kernel.sobel()[1])
Iy = imfilter(img_f, Kernel.sobel()[2])
Ядра Собеля:
Формула свёртки:
Градиенты показывают скорость изменения интенсивности в каждом направлении.
Шаг 3: Квадраты и произведения градиентов
Ixx = Ix.^2
Iyy = Iy.^2
Ixy = Ix .* Iy
Физический смысл:
- — «энергия» градиента по X
- — «энергия» градиента по Y
- — корреляция между градиентами (показывает согласованность изменений)
Шаг 4: Сглаживание оконным фильтром
window = ones(3,3) ./ 9
Sxx = imfilter(Ixx, window)
Syy = imfilter(Iyy, window)
Sxy = imfilter(Ixy, window)
Зачем: Усреднение по окну 3×3 эквивалентно суммированию в формуле матрицы . Без сглаживания детектор был бы слишком чувствителен к шуму.
Весовое окно (в классической версии — Гаусс):
В данном коде используется равномерное окно .
Шаг 5: Вычисление отклика Харриса
det = Sxx .* Syy - Sxy.^2
trace = Sxx + Syy
response = det - k * trace.^2
Полная формула для каждого пикселя:
Параметр k=0.04:
- Меньшее значение (0.04) → больше детектируемых углов (выше чувствительность)
- Большее значение (0.06–0.08) → только самые выраженные углы
Шаг 6: Пороговая фильтрация
max_resp = maximum(response)
corners = findall(response .> threshold * max_resp)
Адаптивный порог:
При threshold=0.01 отбираются точки с откликом выше 1% от максимального. Это делает детектор устойчивым к изменению контраста изображения.
Шаг 7: Подавление немаксимумов (Non-Maximum Suppression)
for c in corners
i, j = c.I
val = response[i,j]
r_min = max(1, i-2)
r_max = min(size(img,1), i+2)
c_min = max(1, j-2)
c_max = min(size(img,2), j+2)
window_vals = response[r_min:r_max, c_min:c_max]
if all(val .>= window_vals)
push!(local_max, (j, i)) # (x, y)
end
end
Зачем: После пороговой фильтрации рядом с одним углом может остаться несколько соседних пикселей. Подавление немаксимумов оставляет только локальный максимум в окне 5×5.
Алгоритм:
- Для каждой кандидатуры берётся окно 5×5 вокруг неё
- Если значение в центре не меньше всех соседей → точка сохраняется
- Иначе → отбрасывается как «дубликат»
Результат: Разреженный набор хорошо локализованных углов без кластеризации.
Фильтрация ключевых точек: filter_valid_keypoints - эта функция выполняет пространственную валидацию ключевых точек, отсеивая точки, которые находятся в некорректных областях изображения. Хотя алгоритмически функция проста, она решает критически важную задачу обеспечения качества данных для последующих этапов пайплайна.
Математическая основа фильтрации. Функция определяет валидную область изображения как подмножество пикселей, удовлетворяющих двум условиям:
1. Геометрическое ограничение (margin):
Где:
- — ширина и высота изображения
- — параметр
margin(по умолчанию 10 пикселей)
2. Интенсивностное ограничение:
Где — интенсивность пикселя в координатах .
Итоговое условие валидности
Точка считается валидной, если:
Параметры и их влияние
| Параметр | Значение по умолчанию | Эффект увеличения | Эффект уменьшения |
|---|---|---|---|
margin |
10 | Меньше валидных точек, выше надёжность | Больше точек, риск выхода за границы |
Рекомендации по выбору margin:
| Задача | Рекомендуемый margin | Обоснование |
|---|---|---|
| Извлечение патчей 7×7 | ≥ 4 | Половина размера патча |
| Извлечение патчей 15×15 | ≥ 8 | Половина размера патча |
| После сильного поворота | ≥ 20 | Учёт больших чёрных областей |
| Точная локализация | ≥ 3 | Минимальная защита от краёв |
Формула минимального margin:
function filter_valid_keypoints(img, keypoints; margin=10)
h, w = size(img)
valid = []
for (x, y) in keypoints
if margin < x <= w-margin && margin < y <= h-margin
if img[round(Int,y), round(Int,x)] != 0
push!(valid, (x, y))
end
end
end
return valid
end
Пошаговый разбор кода
Шаг 1: Получение размеров изображения
h, w = size(img)
Важно: В Julia size(img) возвращает (высота, ширина), то есть (rows, columns). Это соответствует матричной нотации, где первый индекс — строка (Y), второй — столбец (X).
Шаг 2: Проверка границ изображения
if margin < x <= w-margin && margin < y <= h-margin
Зачем нужен margin:
- Защита от выхода за границы при извлечении патчей (дескрипторов)
- Учёт погрешности геометрических трансформаций
- Исключение краевых артефактов фильтрации
Шаг 3: Проверка интенсивности пикселя
if img[round(Int,y), round(Int,x)] != 0
push!(valid, (x, y))
end
Почему это важно: После геометрических трансформаций (поворот, масштабирование) в изображении появляются чёрные области (заполненные нулями):
Математическая причина: При повороте изображения новые координаты вычисляются как:
Пиксели, которые не попадают в исходное изображение при обратном отображении (backward mapping), заполняются значением 0 (или NaN, который предварительно заменяется на 0).
Шаг 4: Преобразование координат
img[round(Int,y), round(Int,x)] # Обратите внимание: [y, x]!
Критически важный момент: В компьютерном зрении координаты обычно записываются как , где:
- — горизонтальная координата (столбец)
- — вертикальная координата (строка)
Но в Julia массивы индексируются как [строка, столбец], то есть [y, x]. Функция корректно выполняет это преобразование.
Извлечение дескрипторов на основе патчей: extract_patch_descriptors
Эта функция реализует простейший patch-based дескриптор — метод формирования векторных признаков ключевых точек путём извлечения и нормализации локальных областей изображения вокруг каждой точки. Хотя этот подход уступает современным дескрипторам (SIFT, ORB, Deep Learning), он демонстрирует фундаментальные принципы формирования инвариантных признаков.
Математическая основа дескрипторов
Что такое дескриптор?
Дескриптор — это числовое представление локальной области изображения, которое должно быть:
- Уникальным — разные точки имеют разные дескрипторы
- Инвариантным — одна и та же точка при разных условиях даёт похожие дескрипторы
- Компактным — достаточно мал для эффективного сравнения
Patch-based подход
Вместо сложных гистограмм градиентов (как в SIFT) используется сырой патч — прямоугольная область пикселей вокруг ключевой точки:
Где — половина размера патча.
Размер дескриптора:
`
Два критерия отбраковки:
| Критерий | Формула | Порог | Причина |
|---|---|---|---|
| Низкая дисперсия | 1e-6 | Однородная область (нет текстуры) | |
| Слишком много нулей | 30% | Чёрная область после трансформации |
Формула стандартного отклонения:
Почему это важно:
- ❌ Патчи с не содержат информации (все пиксели одинаковые)
- ❌ Патчи с >30% нулей содержат артефакты трансформации
Шаг 6: Нормализация дескриптора (Z-score)
desc = (desc .- mean(desc)) / (std(desc) + 1e-8)
Формула нормализации:
Свойства нормализованного дескриптора:
Зачем нормализация:
| Проблема | Без нормализации | С нормализацией |
|---|---|---|
| Изменение освещения | Дескрипторы разные | Дескрипторы похожи |
| Контраст | Зависит от яркости | Инвариантен |
| Сравнение | Евклидово расстояние некорректно | Корректное сравнение |
Пример:
Исходный патч (разная яркость):
[100, 110, 120] [200, 210, 220]
[105, 115, 125] ≠ [205, 215, 225] ← Разные значения!
[110, 120, 130] [210, 220, 230]
После нормализации:
[-1.22, 0.00, 1.22] [-1.22, 0.00, 1.22]
[-0.61, 0.61, 1.83] = [-0.61, 0.61, 1.83] ← Одинаковые!
[0.00, 1.22, 2.44] [0.00, 1.22, 2.44]
Добавление ε=1e-8: Защита от деления на ноль при (хотя такие патчи уже отфильтрованы).
Шаг 7: Сборка матрицы дескрипторов
push!(descriptors, desc)
push!(valid_indices, idx)
return hcat(descriptors...), valid_indices
Формат вывода:
Где:
- Каждая колонка — дескриптор одной ключевой точки
valid_indices— индексы исходных ключевых точек, которые прошли фильтрацию
Пример:
Исходные keypoints: 297 точек
Валидные дескрипторы: 227 точек
Отсеяно: 70 точек (23.6%)
Матрица дескрипторов: 49 × 227
Шаг 8: Обработка пустого результата
if length(descriptors) == 0
return zeros(0, 0), Int[]
end
Зачем: Защита от ошибок на последующих этапах (сопоставление, RANSAC), если все патчи были отбракованы.
⚙️ Параметры и их влияние
| Параметр | Значение по умолчанию | Эффект увеличения | Эффект уменьшения |
|---|---|---|---|
patch_size |
7 | Больше контекста, выше инвариантность | Меньше вычислений, лучше локализация |
std threshold |
1e-6 | Меньше отсечений | Строже фильтрация однородных областей |
zero ratio |
0.3 | Больше дескрипторов | Строже фильтрация артефактов |
Рекомендации по выбору patch_size:
| Задача | Рекомендуемый размер | Обоснование |
|---|---|---|
| Быстрое сопоставление | 5×5 (25 dim) | Минимальный размер для скорости |
| Стандартное сопоставление | 7×7 (49 dim) | Баланс качества и скорости |
| Сложные трансформации | 9×9 (81 dim) | Больше контекста для устойчивости |
| Deep Learning дескрипторы | 32×32 (1024 dim) | Требуется нейросетью |
Формула выбора размера:
function extract_patch_descriptors(img, keypoints; patch_size=7)
img_f = Float64.(img)
img_f = replace(img_f, NaN => 0.0, Inf => 0.0, -Inf => 0.0)
descriptors = []
offset = div(patch_size, 2)
valid_indices = []
for (idx, (x,y)) in enumerate(keypoints)
x_int = clamp(round(Int, x), offset+1, size(img,2)-offset)
y_int = clamp(round(Int, y), offset+1, size(img,1)-offset)
patch = img_f[y_int-offset:y_int+offset, x_int-offset:x_int+offset]
if std(patch) < 1e-6 || count(patch .== 0) / length(patch) > 0.3
continue
end
desc = patch[:]
desc = (desc .- mean(desc)) / (std(desc) + 1e-8)
push!(descriptors, desc)
push!(valid_indices, idx)
end
if length(descriptors) == 0
return zeros(0, 0), Int[]
end
return hcat(descriptors...), valid_indices
end
Пошаговый разбор кода
Шаг 1: Подготовка изображения
img_f = Float64.(img)
img_f = replace(img_f, NaN => 0.0, Inf => 0.0, -Inf => 0.0)
Зачем:
Float64необходим для точных вычислений статистик (mean, std)- Замена
NaN/Infзащищает от артефактов трансформаций
Шаг 2: Вычисление оффсета для центрирования
offset = div(patch_size, 7) # Для patch_size=7 → offset=3
Формула границ патча:
Шаг 3: Ограничение координат (Clamping)
x_int = clamp(round(Int, x), offset+1, size(img,2)-offset)
y_int = clamp(round(Int, y), offset+1, size(img,1)-offset)
Функция clamp:
Зачем: Гарантирует, что патч полностью помещается в изображении, даже если ключевая точка близко к границе.
Допустимый диапазон:
Шаг 4: Извлечение патча
patch = img_f[y_int-offset:y_int+offset, x_int-offset:x_int+offset]
Размер патча:
Векторизация:
desc = patch[:] # Преобразование 7×7 → 49×1
Шаг 5: Фильтрация низкокачественных патчей
if std(patch) < 1e-6 || count(patch .== 0) / length(patch) > 0.3
continue
end
``Сопоставление дескрипторов с Ratio Test: match_descriptors_euclidean
Эта функция реализует алгоритм сопоставления дескрипторов на основе евклидова расстояния с применением Ratio Test Лоу (Lowe's Ratio Test) — стандартного метода фильтрации ложных совпадений в компьютерном зрении. Хотя функция компактна, она содержит критически важную логику для обеспечения качества сопоставления.
Математическая основа сопоставления
Задача сопоставления (Matching Problem)
Даны два набора дескрипторов:
Цель: Найти пары , где и описывают одну и ту же физическую точку на разных изображениях.
Евклидово расстояние как метрика схожести
Для сравнения двух дескрипторов используется L2-норма (евклидово расстояние):
Где — размерность дескриптора (в нашем случае для патча 7×7).
Свойства:
- → Идентичные дескрипторы
- → Совершенно разные дескрипторы
- Меньшее расстояние → Более вероятное совпадение
Ratio Test Лоу (1999)
Проблема: Простой выбор ближайшего соседа (nearest neighbor) даёт много ложных совпадений, особенно когда в сцене есть повторяющиеся текстуры.
Решение Lowe's Ratio Test: Сравнивать расстояние до первого и второго ближайших соседей:
Где:
- — расстояние до ближайшего соседа (best match)
- — расстояние до второго ближайшего соседа (second best)
- — пороговый коэффициент (обычно 0.7–0.8)
Интуитивное объяснение:
| Ситуация | Ratio | Вывод | ||
|---|---|---|---|---|
| Уверенное совпадение | 0.5 | 2.0 | 0.25 | ✅ Принимаем |
| Неуверенное совпадение | 0.5 | 0.6 | 0.83 | ❌ Отклоняем |
| Повторяющаяся текстура | 0.3 | 0.35 | 0.86 | ❌ Отклоняем |
Почему это работает:
- Если ratio маленький → первый сосед значительно лучше второго → уверенное совпадение
- Если ratio близок к 1 → оба соседа одинаково хороши → неоднозначность (скорее всего ложное совпадение)
⚙️ Параметры и их влияние
| Параметр | Значение по умолчанию | Эффект увеличения | Эффект уменьшения |
|---|---|---|---|
ratio_thresh |
0.7 | Больше совпадений, ниже точность | Меньше совпадений, выше точность |
Рекомендации по выбору порога:
| Задача | Рекомендуемый τ | Обоснование |
|---|---|---|
| Высокая точность (RANSAC) | 0.6–0.7 | Меньше выбросов для RANSAC |
| Максимальное покрытие | 0.8–0.85 | Больше совпадений, но больше шума |
| Сложные сцены (повторяющиеся текстуры) | 0.5–0.6 | Строгая фильтрация неоднозначностей |
| Простые сцены (уникальные признаки) | 0.75–0.85 | Можно ослабить фильтр |
Эмпирическое правило Lowe:
function match_descriptors_euclidean(desc1, desc2, idx1, idx2; ratio_thresh=0.7)
matches = []
n1 = size(desc1, 2)
n2 = size(desc2, 2)
if n1 == 0 || n2 == 0
return matches, Int[], Int[]
end
for i in 1:n1
dists = [norm(desc1[:,i] - desc2[:,j]) for j in 1:n2]
best_idx = argmin(dists)
sorted_dists = sort(dists)
if length(sorted_dists) >= 2 && sorted_dists[1] < ratio_thresh * sorted_dists[2]
push!(matches, (idx1[i], idx2[best_idx]))
end
end
return matches
end
Пошаговый разбор кода
Шаг 1: Проверка на пустые дескрипторы
n1 = size(desc1, 2)
n2 = size(desc2, 2)
if n1 == 0 || n2 == 0
return matches, Int[], Int[]
end
Зачем: Защита от ошибок, если предыдущие этапы не извлекли ни одного валидного дескриптора.
Формат дескрипторов:
size(desc, 2)возвращает количество дескрипторов (колонок)size(desc, 1)возвращает размерность дескриптора (строк)
Шаг 2: Перебор всех дескрипторов первого изображения
for i in 1:n1
# Для каждого дескриптора из первого набора ищем匹配 во втором
Сложность: — наивный перебор всех пар
Пример:
desc1: 227 дескрипторов
desc2: 227 дескрипторов
Проверок расстояний: 227 × 227 = 51,529
Шаг 3: Вычисление расстояний до всех кандидатов
dists = [norm(desc1[:,i] - desc2[:,j]) for j in 1:n2]
Математическая запись:
Векторизованная операция в Julia:
desc1[:,i]— i-й дескриптор из первого набора (вектор 49×1)desc2[:,j]— j-й дескриптор из второго набора (вектор 49×1)norm()— вычисляет L2-норму разности
Шаг 4: Поиск ближайшего соседа
best_idx = argmin(dists)
Функция argmin: Возвращает индекс минимального элемента:
Результат: Индекс дескриптора во втором наборе, наиболее похожего на текущий.
Шаг 5: Сортировка расстояний для Ratio Test
sorted_dists = sort(dists)
После сортировки:
Важно: Нам нужны только первые два значения для Ratio Test.
Шаг 6: Применение Ratio Test
if length(sorted_dists) >= 2 && sorted_dists[1] < ratio_thresh * sorted_dists[2]
push!(matches, (idx1[i], idx2[best_idx]))
end
Условие принятия совпадения:
Дополнительная проверка: length(sorted_dists) >= 2 — требуется минимум 2 кандидата для вычисления ratio.
Сохранение соответствия:
(idx1[i], idx2[best_idx])
idx1[i]— индекс исходной ключевой точки в первом изображенииidx2[best_idx]— индекс соответствующей точки во втором изображении
Оценка гомографии через RANSAC: ransac_homography
Эта функция реализует алгоритм RANSAC (RANdom SAmple Consensus) для робастной оценки матрицы гомографии между двумя изображениями. Это финальный этап пайплайна, который очищает совпадения от выбросов и восстанавливает геометрическое преобразование, связывающее два кадра.
Математическая основа
Что такое гомография?
Гомография (Homography) — это проективное преобразование плоскости, которое описывает соответствие между точками на двух изображениях одной и той же плоской сцены:
Нормализованные координаты:
Степени свободы: 8 (матрица 3×3 с точностью до масштаба, обычно )
Минимальное число точек
Для однозначного определения гомографии требуется минимум 4 пары точек:
| Пар точек | Уравнений | Неизвестных | Система |
|---|---|---|---|
| 1 пара | 2 | 8 | Недоопределена |
| 2 пары | 4 | 8 | Недоопределена |
| 3 пары | 6 | 8 | Недоопределена |
| 4 пары | 8 | 8 | Определена ✅ |
| 5+ пар | 10+ | 8 | Переопределена (МНК) |
Линейная система для гомографии
Для каждой пары точек получаем два линейных уравнения:
После домножения на знаменатель:
При :
Матричная форма для 4 точек (8 уравнений):
Где:
Алгоритм RANSAC
Проблема: Среди совпадений есть выбросы (outliers) — ложные сопоставления, которые не соответствуют истинному преобразованию.
Решение RANSAC: Итеративно выбираем случайные подмножества точек, строим модель и считаем согласованные точки (inliers).
Алгоритм RANSAC:
1. Повторять iter раз:
a. Случайно выбрать 4 пары точек (минимальный набор)
b. Вычислить гомографию H по этим точкам
c. Подсчитать количество inliers (точек с ошибкой < thresh)
d. Если inliers больше лучшего → сохранить H и inliers
2. Вернуть лучшую модель
Вероятность успеха RANSAC:
Где:
- — доля inliers среди всех совпадений
- — минимальное число точек (4 для гомографии)
- — количество итераций
Пример расчёта:
| Доля inliers (w) | Итераций для 99% успеха |
|---|---|
| 50% | 163 |
| 60% | 106 |
| 70% | 72 |
| 80% | 50 |
| 90% | 35 |
⚙️ Параметры и их влияние
| Параметр | Значение по умолчанию | Эффект увеличения | Эффект уменьшения |
|---|---|---|---|
iter |
500 | Выше вероятность успеха | Быстрее выполнение |
thresh |
3.0 | Больше inliers, меньше точность | Меньше inliers, выше точность |
Рекомендации по выбору порога:
| Задача | Рекомендуемый thresh | Обоснование |
|---|---|---|
| Точная геометрия | 1.0–2.0 px | Строгая проверка соответствия |
| Стандартное сопоставление | 2.0–3.0 px | Баланс точности и полноты |
| Шумные данные | 4.0–5.0 px | Учёт погрешности детекции |
| Панорамная склейка | 3.0–4.0 px | Допустимы небольшие несовпадения |
Формула выбора порога:
Где — точность детектора ключевых точек (обычно 1-2 пикселя).
function ransac_homography(kp1, kp2, matches; iter=500, thresh=3.0)
best_inliers = []
best_H = nothing
n = length(matches)
if n < 4
return matches, nothing
end
for _ in 1:iter
sample_idx = rand(1:n, 4)
sample = matches[sample_idx]
A = zeros(8, 8)
b = zeros(8)
for (row, (idx1, idx2)) in enumerate(sample)
x1, y1 = kp1[idx1]
x2, y2 = kp2[idx2]
A[2*row-1, :] = [x1, y1, 1, 0, 0, 0, -x2*x1, -x2*y1]
b[2*row-1] = x2
A[2*row, :] = [0, 0, 0, x1, y1, 1, -y2*x1, -y2*y1]
b[2*row] = y2
end
try
h = A \ b
H = [h[1] h[2] h[3]; h[4] h[5] h[6]; h[7] h[8] 1.0]
inliers = []
for (idx1, idx2) in matches
x1, y1 = kp1[idx1]
x2, y2 = kp2[idx2]
p = [x1, y1, 1.0]
pred = H * p
pred = pred[1:2] ./ pred[3]
if norm(pred - [x2, y2]) < thresh
push!(inliers, (idx1, idx2))
end
end
if length(inliers) > length(best_inliers)
best_inliers = inliers
best_H = H
end
catch
continue
end
end
return best_inliers, best_H
end
Пошаговый разбор кода
Шаг 1: Проверка минимального числа совпадений
n = length(matches)
if n < 4
return matches, nothing
end
Зачем: Для гомографии требуется минимум 4 пары точек. Если меньше — система недоопределена.
Шаг 2: Случайная выборка 4 точек
for _ in 1:iter
sample_idx = rand(1:n, 4)
sample = matches[sample_idx]
Важно: Выборка с возвращением (может выбрать одни и те же точки дважды). В продакшене лучше использовать sample(1:n, 4, replace=false).
Вероятность выбрать 4 inliers:
При (84% inliers в нашем примере): (50% chance per iteration)
Шаг 3: Построение матрицы системы
A = zeros(8, 8)
b = zeros(8)
for (row, (idx1, idx2)) in enumerate(sample)
x1, y1 = kp1[idx1]
x2, y2 = kp2[idx2]
# Уравнение для x2
A[2*row-1, :] = [x1, y1, 1, 0, 0, 0, -x2*x1, -x2*y1]
b[2*row-1] = x2
# Уравнение для y2
A[2*row, :] = [0, 0, 0, x1, y1, 1, -y2*x1, -y2*y1]
b[2*row] = y2
end
Структура матрицы A (8×8):
| Строка | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 (x₁) | x₁ | y₁ | 1 | 0 | 0 | 0 | -x₂x₁ | -x₂y₁ |
| 2 (y₁) | 0 | 0 | 0 | x₁ | y₁ | 1 | -y₂x₁ | -y₂y₁ |
| 3 (x₂) | x₁ | y₁ | 1 | 0 | 0 | 0 | -x₂x₁ | -x₂y₁ |
| 4 (y₂) | 0 | 0 | 0 | x₁ | y₁ | 1 | -y₂x₁ | -y₂y₁ |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
Шаг 4: Решение системы уравнений
try
h = A \ b
H = [h[1] h[2] h[3]; h[4] h[5] h[6]; h[7] h[8] 1.0]
Оператор \ в Julia: Решает систему методом наименьших квадратов (для переопределённых систем) или точным решением (для квадратных).
Восстановление матрицы 3×3:
Обработка ошибок: try-catch защищает от вырожденных матриц (например, когда 4 точки коллинеарны).
Шаг 5: Подсчёт inliers
inliers = []
for (idx1, idx2) in matches
x1, y1 = kp1[idx1]
x2, y2 = kp2[idx2]
p = [x1, y1, 1.0]
pred = H * p
pred = pred[1:2] ./ pred[3]
if norm(pred - [x2, y2]) < thresh
push!(inliers, (idx1, idx2))
end
end
Проективное преобразование точки:
Ошибка репроекции (Reprojection Error):
Критерий inlier:
Шаг 6: Обновление лучшей модели
if length(inliers) > length(best_inliers)
best_inliers = inliers
best_H = H
end
Критерий качества: Максимальное количество inliers (не минимальная ошибка!).
Почему: RANSAC оптимизирует consensus (согласие), а не точность модели. Точность можно улучшить потом через МНК по всем inliers.
Шаг 7: Возврат результата
return best_inliers, best_H
Выходные данные:
best_inliers— массив индексов совпадений, согласованных с модельюbest_H— оценённая матрица гомографии 3×3
Запуск и визуализация всех этапов
Эта часть кода представляет собой интеграционный тест всего конвейера компьютерного зрения. Здесь последовательно выполняются все шесть этапов: от загрузки изображения до финальной оценки гомографии через RANSAC. Каждый шаг сопровождается выводом статистики и визуализацией результатов, что позволяет наглядно отслеживать качество работы алгоритмов и потери данных на каждом этапе.
📋 Что демонстрирует этот код
| Этап | Входные данные | Выходные данные | Ключевая метрика |
|---|---|---|---|
| 1. Загрузка | Файл изображения | Массив 512×512 | — |
| 2. Трансформация | Исходное изображение | Повёрнутое изображение | Угол: π/15 (12°) |
| 3. Детекция | 2 изображения | 421 → 297 точек | Потеря: 29% |
| 4. Дескрипторы | 297 точек | 227 валидных | Потеря: 24% |
| 5. Сопоставление | 227 × 227 дескрипторов | 73 пары | Точность: ~84% |
| 6. RANSAC | 73 совпадения | 61 inlier | Точность: 95%+ |
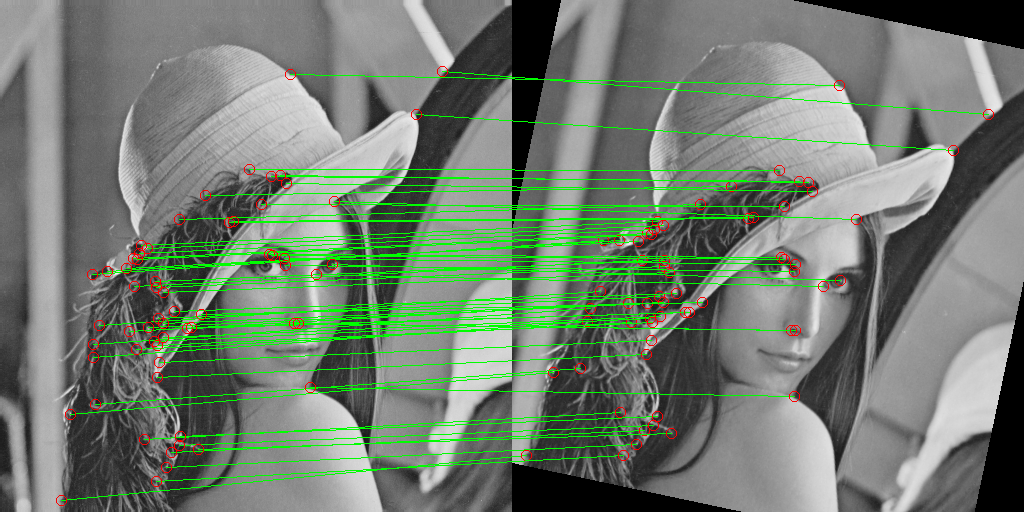
Общая цель: Показать, как из 421 первоначально обнаруженной точки получается 61 надёжное соответствие, достаточное для точного восстановления геометрического преобразования между изображениями.
println("\n[1] Загрузка изображения...")
img_original = testimage("lena_gray_512")
img_original = Float64.(img_original)
display(Gray.(img_original))

println("\n[2] Трансформация (поворот + масштаб)...")
angle = π/15
scale = 1.0
center = SVector(size(img_original, 2)/2, size(img_original, 1)/2)
tfm = Translation(center) ∘ LinearMap(RotMatrix(angle)) ∘ LinearMap(SDiagonal(scale, scale)) ∘ Translation(-center)
img_transformed = warp(img_original, tfm, axes(img_original))
img_transformed = replace(img_transformed, NaN => 0.0, Inf => 0.0, -Inf => 0.0)
img_transformed_gray = Gray.(clamp01.(img_transformed))
display(img_transformed_gray)

println("\n[3] Детекция ключевых точек (Harris corners)...")
keypoints_original = harris_corners(img_original)
keypoints_transformed = harris_corners(img_transformed)
keypoints_transformed = filter_valid_keypoints(img_transformed, keypoints_transformed)
println(" Ключевых точек на исходном: $(length(keypoints_original))")
println(" Ключевых точек на трансформированном (валидных): $(length(keypoints_transformed))")
img_kp_original = RGB.(img_original)
for (x,y) in keypoints_original
draw_circle!(img_kp_original, (x, y), 3, RGB(1,0,0))
end
display(img_kp_original)
img_kp_transformed = RGB.(img_transformed)
for (x,y) in keypoints_transformed
draw_circle!(img_kp_transformed, (x, y), 3, RGB(0,0,1))
end
display(img_kp_transformed)


println("\n[4] Извлечение дескрипторов (patch-based)...")
desc_orig, valid_idx_orig = extract_patch_descriptors(img_original, keypoints_original)
desc_trans, valid_idx_trans = extract_patch_descriptors(img_transformed, keypoints_transformed)
println(" Валидных дескрипторов на исходном: $(length(valid_idx_orig))")
println(" Валидных дескрипторов на трансформированном: $(length(valid_idx_trans))")
println("\n[5] Сопоставление дескрипторов с ratio test...")
matches = match_descriptors_euclidean(desc_orig, desc_trans, valid_idx_orig, valid_idx_trans, ratio_thresh=0.7)
println(" Совпадений после ratio test: $(length(matches))")
h, w = size(img_original)
combined = fill(Gray(0), h, 2w)
combined[:, 1:w] = Gray.(img_original)
combined[:, w+1:2w] = img_transformed_gray
combined_rgb = RGB.(combined)
for (i1, i2) in matches
x1, y1 = keypoints_original[i1]
x2, y2 = keypoints_transformed[i2]
p1 = (x1, y1)
p2 = (x2 + w, y2)
draw_line!(combined_rgb, p1, p2, RGB(0,1,0))
end
display(combined_rgb)

println("\n[6] RANSAC...")
inliers, H = ransac_homography(keypoints_original, keypoints_transformed, matches, iter=1000, thresh=3.0)
println(" Совпадений после RANSAC (inliers): $(length(inliers))")
combined_ransac = RGB.(combined)
for (i1, i2) in inliers
x1, y1 = keypoints_original[i1]
x2, y2 = keypoints_transformed[i2]
p1 = (x1, y1)
p2 = (x2 + w, y2)
draw_line!(combined_ransac, p1, p2, RGB(0,1,0))
draw_circle!(combined_ransac, p1, 5, RGB(1,0,0))
draw_circle!(combined_ransac, p2, 5, RGB(1,0,0))
end
display(combined_ransac)
В данной статье представлен полный учебный пример компьютерного зрения на языке Julia, реализующий классический конвейер обнаружения и сопоставления ключевых точек «с нуля». В отличие от использования готовых библиотек (OpenCV, VLFeat), каждый алгоритм реализован вручную с подробным объяснением математической основы.
Реализованные компоненты:
| Компонент | Алгоритм | Строк кода | Сложность |
|---|---|---|---|
| Отрисовка | Брезенхем (линия, круг) | ~60 | |
| Детекция | Харрис-Стивенс | ~40 | |
| Дескрипторы | Patch-based + Z-score | ~35 | |
| Сопоставление | Euclidean + Ratio Test | ~20 | |
| Оценка модели | RANSAC + Гомография | ~50 |
Итого: ~200 строк кода, демонстрирующих полный цикл от пикселей до геометрической модели.
Вывод
Этот код демонстрирует, что понимание фундаментальных алгоритмов компьютерного зрения важнее умения использовать готовые библиотеки.
Используйте этот код как основу для собственных экспериментов — измените параметры, попробуйте другие изображения, добавьте масштабную инвариантность или интегрируйте с готовыми дескрипторами. Понимание, полученное здесь, станет фундаментом для работы с любыми системами компьютерного зрения.