Обучение суррогатной нейросети
Суррогатная нейросеть из физической модели
Рассмотрим, как создать нейросеть на замену физической модели, что позволит нам упростить вычисления, добиться переносимости на контроллеры или скрыть детали реализации.
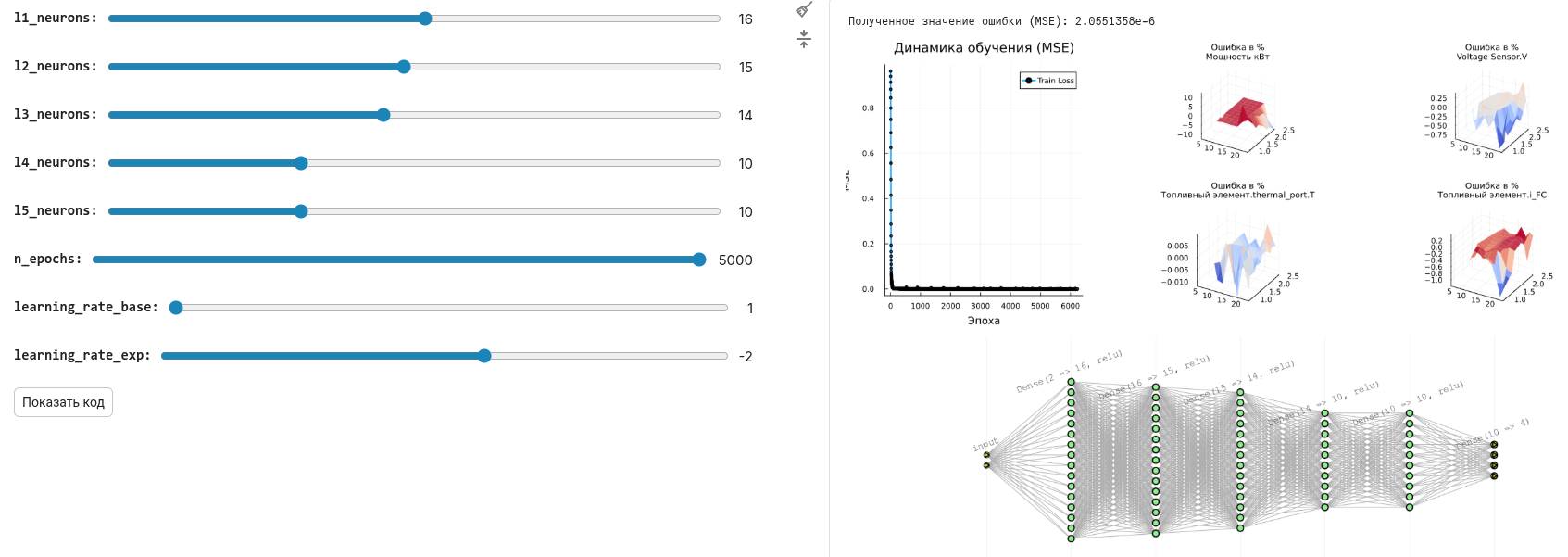
В результате мы сможем легко менять параметры нейросети при помощи маскированной ячейки кода и проверять качество прогноза по такому графику:
Преобразование моделей
Зачем может понадобиться преобразовывать модель в нейросеть? Может быть много сценариев, когда это интересно:
- преобразовать модель в код для контроллера,
- ускорить выполнение модели чтобы запускать ее в цикле,
- скрыть детали реализации модели, оставив только вычисления.
Нейросети - хорошо изученная и простая форма задания моделей, особенно полносвязанные, которые мы будем использовать в этом проекте.
Установим и загрузим несколько библиотек, а также откроем модель, которую будем преобразовывать в нейросеть.
Для этого примера мы взяли модель из проекта Система топливных элементов автора shestakoviktor.
Pkg.add(["ChainPlots", "Flux"])
using DataFrames, CSV, Flux, Random, Statistics, ChainPlots
using Flux: mse
gr();
engee.open( "$(@__DIR__)/" * "FuelCell.engee");
.png)
Наш подход позволит анализировать результаты, полученные через engee.run() для разных входных условий. Условия мы будем задавать, изменяя параметры разных блоков при помощи engee.set_param!().
Мы не сможем менять глобальные переменные в цикле, только свойства блоков. Julia не позволяет манипулировать глобальными переменными внутри локальных процедур. Изменение свойств блоков оставляет меньше шансов, что мы забудем произвести какие-то вычисления с глобальными расчетами перед выполнением.
Определяем интерфейсы
У нашей модели будет 4 выходных переменных (4 таргета в терминологии нейросетей):
out_vars = ["Мощность кВт", "Voltage Sensor.V", "Топливный элемент.thermal_port.T", "Топливный элемент.i_FC"]
Все эти структуры можно задавать по-разному, вот например задание входных переменных (двух фичей) через CSV таблицу:
csv_text = """
block, param, units, delta, lower, upper
FuelCell/Давление водорода (бар), Value, , 2.0, 2.0, 20.0
FuelCell/Подача топлива, slope, , 10/60, 50/60, 150/60
"""
adj_vars = CSV.read(IOBuffer(csv_text), DataFrame)
И другой вариант -- создать словари параметров и объединить их в DataFrame:
v1 = Dict(:block=>"FuelCell/Давление водорода (бар)",:param=>"Value", :units=>"", :delta=>2.0, :lower=>2.0, :upper=>20.0)
v2 = Dict(:block=>"FuelCell/Подача топлива",:param=>"slope", :units=>"", :delta=>10/60, :lower=>50/60, :upper=>150/60)
adj_vars = vcat(DataFrame.([v1, v2])...)
Таким образом мы выставили количество входов и выходов нейросети, в которую мы превратим физическую модель:
n_features, n_targets= nrow(adj_vars), length(out_vars)
Планирование эксперимента
Подготовим таблицу result_df. Количество столбцов в этой таблице равно количеству запусков исходной модели с разными комбинациями входных параметров. Их диапазон задан в настройках входных переменных (нижний предел lower, верхний предел upper и шаг delta).
ranges = [collect(row.lower:row.delta:row.upper) for row in eachrow(adj_vars)]
combinations = collect(Iterators.product(ranges...))
# Таблица с комбинациями значений всех диапазонов из adj_vars
result_df = DataFrame()
for (i, row) in enumerate(eachrow(adj_vars))
col_name = Symbol("$(row.block)/$(row.param)")
result_df[!, col_name] = [comb[i] for comb in combinations[:]]
end
println("Количество запусков модели: ", nrow(result_df))
first( result_df, 4 )
Запуск модели
Пройдемся по всем строкам таблицы эксперимента и наполним ее значениями выходных переменных.
В качестве выходных переменных возьмем финальное значение каждого интересующего нас сигнала.
Когда данные собраны, эту ячейку лучше закомментировать.
# Создаем новые столбцы для выходных переменных
for var in out_vars result_df[!, Symbol(var)] = fill(Float64(NaN), nrow(result_df)); end
# Выставляем параметры и запускаем модель
for row in eachrow(result_df)
for (i, col) in enumerate(names(result_df)[1:end-length(out_vars)])
block, param, unit = adj_vars.block[i], adj_vars.param[i], adj_vars.units[i]
unit == "" ? engee.set_param!(block, param => string(row[col])) : engee.set_param!(block, param => Dict("value" => string(row[col]), "unit" => String(unit)));
end
data = engee.run()
for var in out_vars row[Symbol(var)] = length(data[var].value) > 1 ? data[var].value[end] : NaN; end
end
# Сохраним результаты для дальнейшей обработки
CSV.write("$(@__DIR__)/data/outputfile.csv", result_df)
first( result_df, 4 )
Мы видим, что часть запусков закончилась неудачно. В этих местах выходные параметры равны NaN. Причина - несовместимые значения входных параметров или настройки решателя, которые можно улучшить.
Вот графики, которые мы будем воспроизводить при помощи нейросети:
result_df = DataFrame(CSV.File("$(@__DIR__)/data/outputfile.csv"))
include("$(@__DIR__)/scripts/create_plots.jl");
in_vars = names(result_df)[1:end-length(out_vars)]
p = [create_plots(result_df, :Blues, out_var, in_vars, result_df) for out_var in out_vars]
plot(p..., legend=false, size=(1500,500), titlefont=font(9), guidefont=font(7))

Подготовка данных для нейросети и обучение
Дело осталось за выбором топологии нейросети и количества нейронов в каждом слое. Каждый эксперимент требует собственного баланса параметров - ёмкости нейросети, точности и длительности обучения, и графическая форма позволяет перебирать их с наименьшими затратами времени.
include("$(@__DIR__)/scripts/prepare_data.jl");
include("$(@__DIR__)/scripts/plot_predictions.jl"); # - если мы хотим графики с сопоставлением прогноза и тренировочных данных
include("$(@__DIR__)/scripts/plot_prediction_errors.jl"); # - если мы хотим видеть ошибки
l1_neurons = 16 # @param {type:"slider",min:1,max:30,step:1}
l2_neurons = 15 # @param {type:"slider",min:1,max:30,step:1}
l3_neurons = 14 # @param {type:"slider",min:1,max:30,step:1}
l4_neurons = 10 # @param {type:"slider",min:1,max:30,step:1}
l5_neurons = 10 # @param {type:"slider",min:1,max:30,step:1}
n_epochs = 5000 # @param {type:"slider",min:1,max:5000,step:1}
learning_rate_base = 1 # @param {type:"slider",min:1,max:9,step:1}
learning_rate_exp = -2 # @param {type:"slider",min:-6,max:1,step:1}
models_list = []
loss_list = []
loss_plot_list = []
for i = 1:5
include("$(@__DIR__)/scripts/prepare_and_train_net.jl")
append!(models_list, [model])
append!(loss_plot_list, [train_losses])
append!(loss_list, loss(model, X_train_norm, y_train_norm))
end
min_id = findmin(loss_list)[2]
train_losses = loss_plot_list[min_id]
model = models_list[min_id]
best_loss = loss_list[min_id]
# График 1: Кривые обучения
p_loss = plot(1:n_epochs, train_losses, label="Train Loss", lw=2, marker=:circle, markersize=2)
title!(p_loss, "Динамика обучения (MSE)")
xlabel!(p_loss, "Эпоха")
ylabel!(p_loss, "MSE")
println("Полученное значение ошибки (MSE): ", best_loss)
# Графики поверхностей для всех целевых переменных
surface_plots = [plot_prediction_errors(model, X_train_norm, y_train_norm,
X_train_mean, X_train_std, y_train_mean, y_train_std, i, adj_vars,
title=out_vars[i])
for i in 1:n_targets]
# Отображаем все графики вместе
l = @layout [a{0.3w} b{0.7w}]
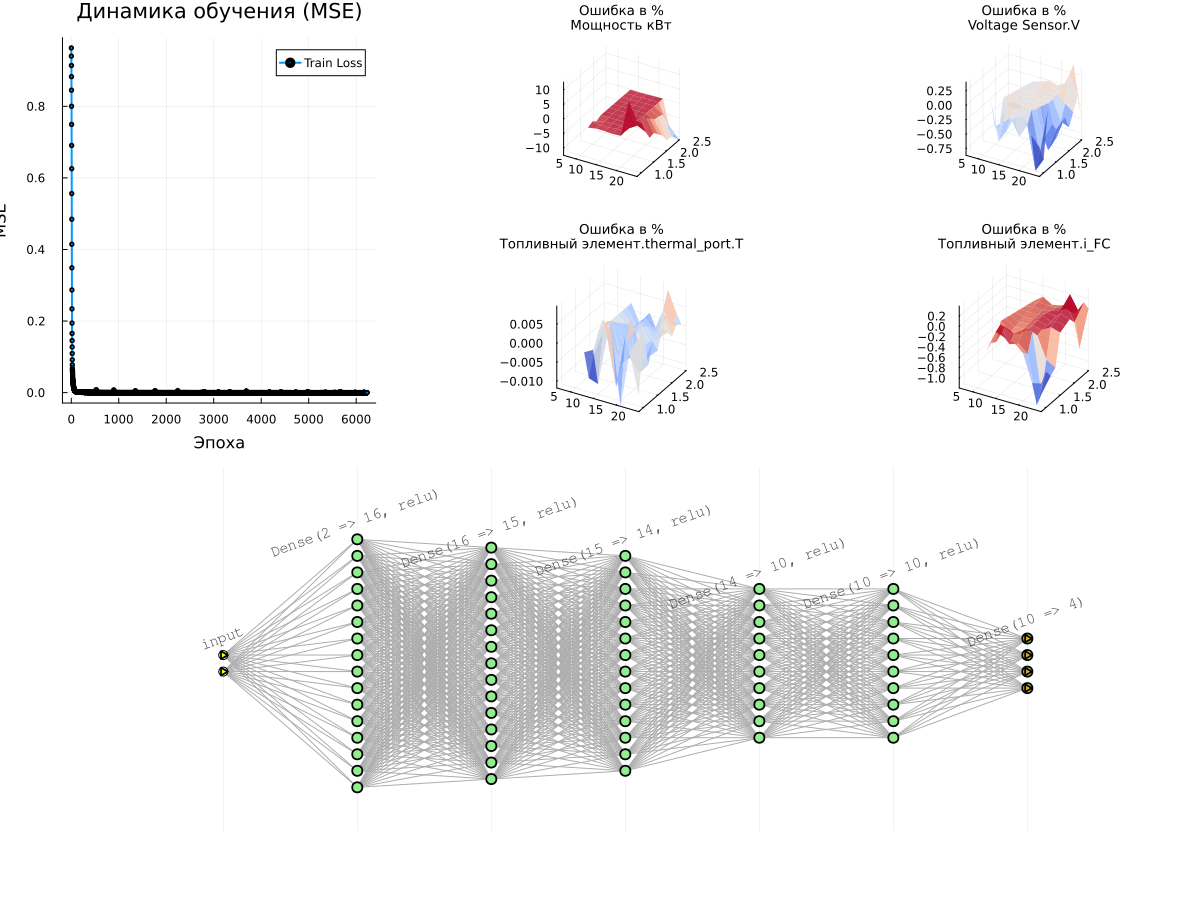
plot(plot(p_loss, plot(surface_plots...),layout=l), plot(model), layout=(2,1), size=(1200,900))
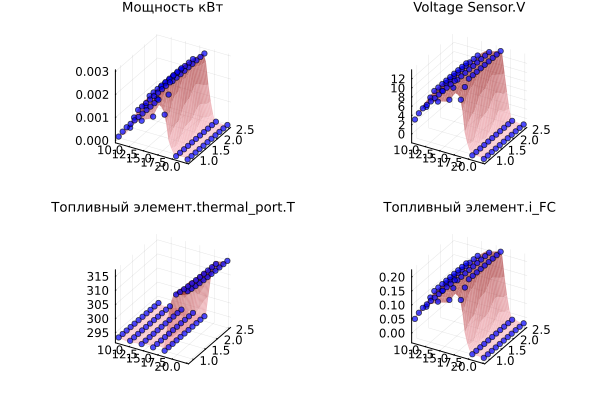
Проверим, как сочетаются прогнозы и исходные данные:
plot([plot_predictions(model, X_train_norm, y_train_norm, X_train_mean, X_train_std, y_train_mean, y_train_std, i, title=out_vars[i]) for i in 1:n_targets]...)
Замечания по процессу обучения
- Обучение проводится несколько раз, выбирается лучшая модель. Каждый запуск обучения возвращает нам новую нейросеть, и нужно снять зависимость от начальных параметров.
- Нет разделения на тренировочное и тестовое подмножество. Если обучающих точек в таблице будет много, то лучше реализовать это разделение и не рисковать переобучением.
- Данные для нейросети нормализованы. В процессе обучения используются данные очень разного масштаба (вольты, километры, …), и чтобы не вредить качеству прогноза, данные приведены к единичному нормальному распределению.
- Наибольшее время уходит на отрисовку графиков. В остальном, о скорости обучения волноваться не приходится, она очень высокая.
- Любое изменение параметров в большую сторону скорее всего улучшит качество аппроксимации нейросетью, но увеличение ёмкости приблизит переобучение.
Заключение
Мы представили методологию для создания нейросети на основе входов и выходов физической модели. Используя ее вы можете упаковать любую модель в нейросеть и пользоваться ей для прогнозов.