Сравнение производительности методов классификации
Сравнение производительности ансамблевых методов Julia и Matlab
Введение
Современные задачи машинного обучения требуют не только высокой точности моделей, но и эффективного использования вычислительных ресурсов. Выбор инструментария напрямую влияет на скорость разработки и время обучения, что особенно критично при работе с большими объёмами данных и ансамблевыми методами, известными своей ресурсоёмкостью.
Ансамблевые методы — это методы машинного обучения, которые объединяют несколько базовых моделей (например, деревья решений) для получения более точного и устойчивого прогноза, чем каждая модель по отдельности.
В данном примере представлен сравнительный анализ трёх подходов к обучению модели классификации на основе случайного леса:
- с использованием библиотек MLJ и DecisionTree на Julia,
- а также функции fitcensemble в подключаемом ядре Matlab.
Все методы решают одну и ту же задачу бинарной классификации на синтетических данных, что позволяет объективно сопоставить их производительность.
Импорт библиотек
Присоединим необходимые библиотеки.
import Pkg
Pkg.add(["Random", "Distributions", "LinearAlgebra", "Statistics", "DecisionTree", "MLJ", "MLJDecisionTreeInterface"])
using Random, Distributions, LinearAlgebra, Statistics
Генерация данных
Создадим десять красных и десять синих базовых точек. Обратите внимание, в Julia вы можете использовать символы эмодзи в именах переменных.
🔴 = rand(MvNormal([0.0, 1.0], 1.0I), 10)'
🔵 = rand(MvNormal([1.0, 0.0], 1.0I), 10)'
Отобразим базовые точки на координатной плоскости.
gr()
график1 = scatter(🔴[:, 1], 🔴[:, 2], color=:red, marker=:circle, label="Красные", legend=:topright)
scatter!(🔵[:, 1], 🔵[:, 2], color=:blue, marker=:circle, label="Синие")
display(график1)
Создадим по 50000 точек каждого цвета с центром в случайных базовых точках.
N = 50000
🔴 = 🔴[rand(1:10, N), :] + randn(N, 2) .* sqrt(0.02)
🔵 = 🔵[rand(1:10, N), :] + randn(N, 2) .* sqrt(0.02)
график2 =scatter(🔴[:, 1], 🔴[:, 2], color=:red, marker=:circle, markersize=1, label="Красные", alpha=0.36, legend=:topright)
scatter!(🔵[:, 1], 🔵[:, 2], color=:blue, marker=:circle, markersize=1, label="Синие", alpha=0.36)
display(график2)
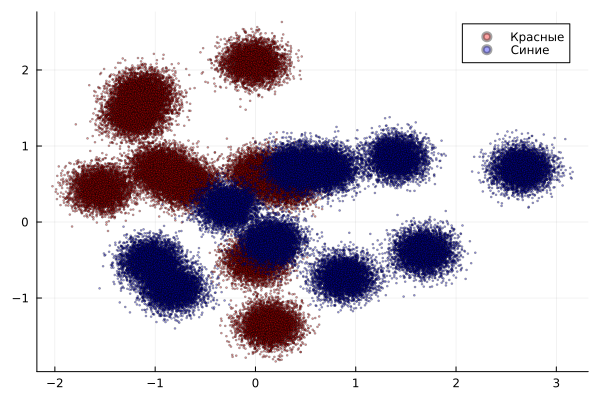
Объединим данные и создадим метки классов для задачи классификации. Создадим единичный вектор меток и присвоим метку -1 для синих точек.
данные = [🔴; 🔵]
метки = ones(2*N)
метки[N+1:2*N] .= -1
# красные 1, синие -1
display(данные)
Сравнение моделей классификации
MLJ
Выполним обучение модели с помощью инструментов библиотеки MLJ (Machine Learning in Julia).
using MLJ, MLJDecisionTreeInterface
дерево = @load DecisionTreeClassifier pkg=DecisionTree
время = @elapsed begin
модель = MLJ.fit!(machine(EnsembleModel(model = дерево(max_depth=-1), n=100, bagging_fraction=1.0, rng=1234),
DataFrame(данные, :auto), coerce(ifelse.(метки .== 1.0, 1, 2), Multiclass)))
end
display(модель)
println("Время обучения: ", время, " секунд")
Время обучения модели с помощью MLJ составило: 33.51 секунд.
Matlab fitensemble
Выполним обучение модели внутри ядра Matlab с помощью функции fitcensemble, и измерим время выполнения.
using MATLAB
cdata = данные
grp = метки
@mput cdata grp N
mat"""
tic
mdl = fitcensemble(cdata, grp, 'Method', 'Bag');
stime = toc;
disp(mdl)
"""
@mget(stime)
println("Время обучения: ", stime, " секунд")
Время обучения модели с помощью Matlab составило: 29.57 секунд.
DecisionTree
Выполним обучение модели с помощью инструментов библиотеки DecisionTree.
using DecisionTree
время = @elapsed begin
модель = build_forest(метки, данные, 2, 100, 1.0, rng=Random.GLOBAL_RNG)
end
display(модель)
println("Время обучения: ", время, " секунд")
Время обучения модели с помощью DecisionTree составило: 6.07 секунд. Это наилучший результат из исследуемых.
Заключение
В данном исследовании проведено обучение ансамбля из 100 решающих деревьев на синтетических данных. Сравнение трёх подходов показало существенную разницу в производительности.
Наилучшую производительность продемонстрировала нативная библиотека Julia DecisionTree (6.07 с), что делает её отличным выбором для высоконагруженных задач и прототипирования.
Результаты подтверждают, что Engee обеспечивает значительный прирост производительности по сравнению с Matlab, сохраняя при этом совместимость с его синтаксисом. Представленные методы классификации применимы в задачах компьютерного зрения, предиктивной аналитики, медицинской диагностики и финансового моделирования, где требуется высокая точность и скорость обработки больших объёмов информации.