JIT设计与实现
本文档解释了在codegen完成并生成未优化的LLVM IR之后,Julia JIT的设计和实现。 JIT负责优化和编译此IR到机器代码,并将其链接到当前进程并使代码可用于执行。
导言
JIT负责管理编译资源、查找以前编译的代码以及编译新代码。 它主要建立在LLVM的https://llvm.org/docs/ORCv2.html[On-Request-Compilation](ORCv2)技术,它为一些有用的特性提供支持,例如并发编译、延迟编译以及在单独进程中编译代码的能力。 虽然LLVM以LLJIT的形式提供了基本的JIT编译器,但Julia直接使用许多ORCv2Api来创建自己的自定义JIT编译器。
概览
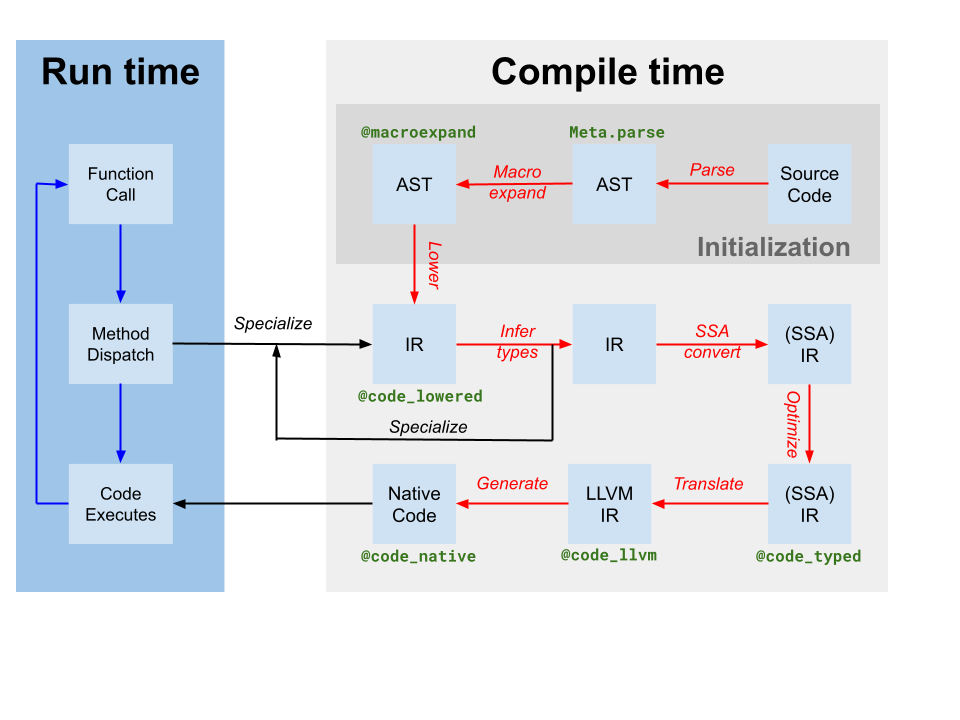
Codegen从由类型推断产生的原始Julia SSA IR(在上面的编译器图中标记为translate)中生成一个包含一个或多个Julia函数的IR的LLVM模块。 它还生成代码实例到LLVM函数名的映射。 然而,尽管基于Julia的编译器已经在Julia IR上应用了一些优化,但codegen生产的LLVM IR仍然包含许多优化的机会。 因此,JIT采取的第一步是运行与目标无关的优化pipeline[1]在LLVM模块上。 然后,JIT运行依赖于目标的优化管道,其中包括特定于目标的优化和代码生成,并输出目标文件。 最后,JIT将生成的目标文件链接到当前进程,并使代码可供执行。 所有这些都是由代码控制的 src/jitlayers.cpp.
目前,由于我们的一个链接器(RuntimeDyld)施加的限制,一次只允许一个线程进入optimize-compile-link管道。 但是,JIT旨在支持并发优化和编译,并且链接器限制预计将在将来在所有平台上完全取代RuntimeDyld时解除。
优化管道
优化管道基于LLVM的新传递管理器,但管道是根据Julia的需求定制的。 管道定义在 src/管道。cpp,并广泛地通过如下详述的若干阶段进行。
-
早期简化
-
这些传递主要用于简化IR和规范化模式,以便以后的传递可以更容易地识别这些模式。 此外,各种内部调用(如分支预测提示和注释)被降低到其他元数据或其他IR功能中。 脧锚脧赂`[医简化`](简化控制流图),https://llvm.org/docs/Passes.html#dce-dead-code-elimination[脧锚脧赂`DCE,DCE`](死码消除),以及https://llvm.org/docs/Passes.html#sroa-scalar-replacement-of-aggregates[脧锚脧赂`SROA`](聚合的标量替换)是这里的一些关键参与者。
-
早期优化
-
这些传递通常很便宜,主要集中在减少IR中的指令数量和将知识传播到其他指令上。 例如,https://en.wikipedia.org/wiki/Common_subexpression_elimination[脧锚脧赂`早期,早期`]用于执行公共子表达式消除,以及https://llvm.org/docs/Passes.html#instcombine-combine-redundant-instructions[脧锚脧赂`[医]InstCombine`]和https://llvm.org/doxygen/classllvm_1_1InstSimplifyPass.html#details[脧锚脧赂`[医]实例化`]执行一些小的窥视孔优化,使操作成本更低。
-
循环优化
-
这些通过规范化和简化循环。 循环通常是热代码,这使得循环优化对性能极其重要。 这里的主要参与者包括https://llvm.org/docs/Passes.html#loop-rotate-rotate-loops[脧锚脧赂`[医]环戊酸`],https://llvm.org/docs/Passes.html#licm-loop-invariant-code-motion[脧锚脧赂`执照`],和https://llvm.org/docs/Passes.html#loop-unroll-unroll-loops[脧锚脧赂`环流;环流`]. 一些边界检查消除也发生在这里,作为结果https://llvm.org/doxygen/InductiveRangeCheckElimination_8cpp_source.html[脧锚脧赂`伊尔斯`]可以证明永远不会超过某些界限的传球。
-
标量优化
-
标量优化管道包含许多更昂贵但更强大的传递,例如https://llvm.org/docs/Passes.html#gvn-global-value-numbering[脧锚脧赂`GVN`](全局值编号),https://llvm.org/docs/Passes.html#sccp-sparse-conditional-constant-propagation[脧锚脧赂`SCCP`](稀疏条件常数传播),以及另一轮边界检查消除。 这些传递的成本很高,但它们通常可以删除大量代码,并使矢量化更加成功和有效。 其他几个简化和优化过程穿插在更昂贵的过程中,以减少他们必须做的工作量。
-
矢量化
-
自动矢量化是一个非常强大的转换CPU密集型代码。 简单地说,矢量化允许执行一个https://en.wikipedia.org/wiki/Single_instruction,_multiple_data[多个数据上的单个指令](SIMD),例如在同一时间执行8个加法操作。 然而,证明代码既能够进行矢量化,又能够盈利地进行矢量化是困难的,这在很大程度上依赖于先前的优化传递来将IR按摩到值得进行矢量化的状态。
-
内在降低
-
Julia插入了许多自定义内部函数,原因包括对象分配、垃圾回收和异常处理。 这些内部函数最初是为了使优化机会更加明显,但现在它们被降低到LLVM IR中,以使IR能够作为机器代码发出。
-
清理工作
-
这些传递是最后机会优化,并执行小的优化,如融合乘加传播和除法余数简化。 此外,不支持半精度浮点数的目标将在这里将其半精度指令降低为单精度指令,并添加传递以提供消毒器支持。
依赖于目标的优化和代码生成
LLVM在同一管道中提供依赖于目标的优化和机器代码生成,该管道位于给定平台的TargetMachine中。 这些传递包括指令选择、指令调度、寄存器分配和机器码发射。 LLVM文档提供了该过程的一个很好的概述,LLVM源代码是查找管道和传递的详细信息的最佳位置。
连结
目前,Julia正在两个链接器之间转换:较旧的RuntimeDyld链接器和较新的链接器https://llvm.org/docs/JITLink.html[JITLink]链接器。 JITLink包含许多RuntimeDyld没有的功能,例如并发和可重入链接,但目前缺乏对分析集成的良好支持,并且还不支持RuntimeDyld支持的所有平台。 随着时间的推移,预计JITLink将完全取代RuntimeDyld。 有关JITLink的更多详细信息,请参阅LLVM文档。
执行死刑
一旦代码链接到当前进程,它就可以执行。 生成代码通过更新 调用, [医]特殊花,而 n.斑点,斑点 字段适当。 Codeinsts支持升级 调用, [医]特殊花,而 n.斑点,斑点 字段,只要在任何给定时间点存在的这些字段的每个组合都是有效的被调用。 这允许JIT在不使现有代码无效的情况下更新这些字段,从而支持未来潜在的并发JIT。 具体而言,以下状态可能有效:
-
调用为NULL,[医]特殊花是0b00,n.斑点,斑点为NULL -
这是codeinstitute的初始状态,表示尚未编译codeinstitute。
-
调用为非null,[医]特殊花是0b00,n.斑点,斑点为NULL -
这表明codeinst未使用任何特化进行编译,并且应该直接调用codeinst。 请注意,在这种情况下,
调用也不读[医]特殊花或n.斑点,斑点字段,因此可以在不使调用指针。 -
调用为非null,[医]特殊花是0b10,n.斑点,斑点为非null -
这表明codeinst已编译,但codegen认为没有必要使用专门的函数签名。
-
调用为非null,[医]特殊花是0b11,n.斑点,斑点为非null -
这表明codeinst已编译,codegen认为需要专门的函数签名。 该
n.斑点,斑点字段包含指向专用函数签名的指针。 该调用允许指针读取两者[医]特殊花和n.斑点,斑点菲尔兹。
此外,在更新过程中出现了许多不同的过渡状态。 要考虑这些潜在情况,在处理这些codeinst字段时应使用以下写入和读取模式。
-
写作时
调用,[医]特殊花,而n.斑点,斑点: -
假设旧值为NULL,执行specptr的原子比较交换操作。 这种比较交换操作至少应该具有获取-释放顺序,以保证写入中剩余内存操作的顺序。
-
如果
n.斑点,斑点是非null,停止写操作,并等待位0b10的[医]特殊花要写入,然后如果需要,从步骤1重新启动。 -
写入新的低位
[医]特殊花到其最终值。 这可能是一个轻松的写作。 -
写新的
调用指向其最终值的指针。 这必须至少有一个释放内存顺序与读取同步调用. -
设置的第二个位
[医]特殊花到1。 这必须至少是一个释放内存顺序,以便与[医]特殊花. 此步骤完成写操作,并向所有其他线程宣布已设置所有字段。 -
当阅读所有
调用,[医]特殊花,而n.斑点,斑点: -
阅读
n.斑点,斑点字段与任何内存排序。 -
阅读
调用至少具有获取内存顺序的字段. 此负载将被称为[医]初始. -
如果
[医]初始为NULL,则代码尚未可执行。调用为NULL,[医]特殊花可视为0b00,n.斑点,斑点可以被视为NULL。 -
如果
n.斑点,斑点为NULL,则[医]初始指针不能依赖n.斑点,斑点以保证正确执行。 因此,调用为非null,[医]特殊花可视为0b00,n.斑点,斑点可以被视为NULL。 -
如果
n.斑点,斑点为非空,则[医]初始可能不是决赛调用使用的字段n.斑点,斑点. 如果发生这种情况n.斑点,斑点已经写好了,但是调用尚未写入。 因此,旋转的第二个位[医]特殊花直到它被设置为1,至少获得内存排序。 -
重新阅读
调用字段与任何内存排序。 此负载将被称为最后,最后. -
阅读
[医]特殊花字段与任何内存排序。 -
调用是最后,最后,[医]特殊花是在步骤7中读取的值,n.斑点,斑点是步骤3中读取的值。 -
当更新
n.斑点,斑点到不同但等价的函数指针: -
执行新函数指针的发布存储到
n.斑点,斑点. 这里的竞赛必须是良性的,因为旧的函数指针仍然是有效的,任何新的指针也是有效的。 一旦指针被写入n.斑点,斑点,它必须始终是可调用的,无论它是否在以后被复盖。
正确读取这些字段是在 jl_read_codeinst_invoke.
虽然这些写入、读取和更新步骤很复杂,但它们可确保JIT可以更新codeinsts而不会使现有的codeinsts无效,并且JIT可以更新codeinsts而不会使现有的codeinsts无效 调用 指针。 这允许JIT将来可能在更高的优化级别重新优化函数,并且还将允许JIT将来支持函数的并发编译。