Working with ZIP/XML files using the example of translating MATLAB live scripts into ngscipt format
In this example, we will show how to work with OPC format files (Open Packaging Conventions), that is, with ZIP containers containing a set of different XML and other files. This format is found everywhere. For example, these types of formats are used in all Office applications (DOCX, XLSX etc.) and in many engineering packages (Autodesk, Simulink, Engee).
We will convert the technical calculations file from the format mlx in ngscript – we will transfer all text and code cells, illustrations, hyperlinks and formulas from one document to another.
Introduction
For working with popular formats like Office Open XML ready-made libraries are usually available (for example, XLSX.jl for spreadsheets). But often we need to quickly process a file format for which there are no ready-made libraries yet, or which do not take into account the necessary elements of the document syntax. Let's imagine ourselves in a scenario where we need to do this processing manually. As an educational example, we will analyze the program for transcoding from the LiveScript format of the MATLAB package to the format ngscript.
For relatively low-level work with the formats of these files, we will need the following libraries:
Pkg.add(["ZipFile", "EzXML"])
using EzXML, ZipFile, JSON, Base64
If any of them are not already installed, run the next cell, first removing the symbol. # (by commenting out the line).
# ]add EzXML ZipFile JSON Base64
It is enough to perform this installation once, but sometimes you can restart it to update library versions.
What does the MLX file consist of?
The Live Code file format uses Open Packaging Conventions technology, which is an extension of the zip file format. The code and formatted content are stored in an XML document that differs from the document using the Office Open XML format. To work with the contents of these files, it is enough to change the file extension to *.zip, and then unzip it through the context menu of the Engee file browser.
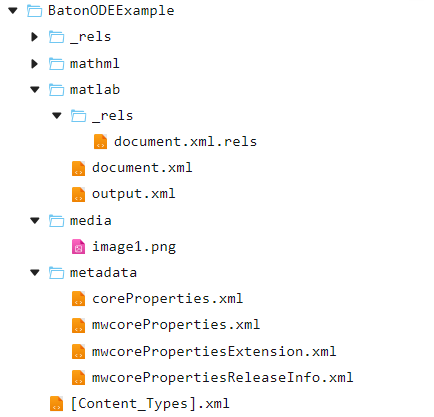
Let's examine the contents of the file *.mlx after unpacking. We will need the following files from the archive:
document.xml, where all the text information of the document is storeddocument.xml.rels– catalog of additional materials included in the document (formulas, illustrations)
.png)
In the folder media the illustrations are collected, which are inserted into the document, and in the folder mathml – used formulas in [MathML] format (https://ru.wikipedia.org/wiki/MathML ).
Uploading and processing MLX files
For the sake of simplifying the reuse of our code (* as well as for the sake of clarity of presentation*), we organize it in the form of a set of functions.
Here are the functions we are implementing at this stage:
- getting a list of files
mlxlocated in the catalog, - unpacking the archive and reading the files we need,
- processing of the media file links,
- getting a list of cells from an XML file,
- converting a cell from XML format to JSON format.
And one auxiliary function for working with illustrations embedded in the file.:
- getting MIME information about illustrations in the desired format (* from a name like "image.png" we make the MIME identifier "image/png"*)
First of all, we will get a list of files mlx in the catalog.
function get_list_of_files( base_folder )
# We scan the directory we need (not recursively, without examining the subfolders)
filenames = readdir( base_folder)
# We will filter only files with the `.mlx` extension.
list_of_files = [joinpath(base_folder,fname) for fname in filenames if endswith( fname, ".mlx")]
end;
Unpack it mlx file the file and add the contents we are interested in to the list.
function get_mlx_content( mlx_full_filename )
# Open the archive to read the contents.
mlx_reader = ZipFile.Reader( mlx_full_filename )
# Let's read the files that will interest us.
document_file = read( [f for f in mlx_reader.files if endswith(f.name, "document.xml")][1], String )
rels_files_list = [f for f in mlx_reader.files if endswith(f.name, "document.xml.rels")]
relations_file = length(rels_files_list) > 0 ? read( rels_files_list[1], String ) : nothing;
# This list will contain the name-content pairs.
media_files_list = Dict([ ("../" * f.name, base64encode( read(f, String) )) for f in mlx_reader.files if occursin("media/", f.name ) ])
# Closing the archive
close( mlx_reader )
return document_file, relations_file, media_files_list
end;
A function for reading the registry of media materials (pictures and equations).
function read_rels_file( input_string )
rels_dict = Dict()
if !(input_string == nothing) && !(input_string == "")
rels_tree = EzXML.parsexml( input_string );
ns = namespace( rels_tree.root )
for Rel in findall( "w:Relationship", root(rels_tree), ["w"=>ns])
rels_dict[Rel["Id"]] = Rel["Target"]
end
end
return rels_dict
end;
Creating a list of cells in the format we need.
function file_to_cells_list( input_string )
tree = EzXML.parsexml( input_string );
ns = namespace( tree.root )
# This list will contain a pair of values for each cell (paragraph) of the source document: their style and content.
parsed_mlx = []
body_node = findfirst( "w:body", root( tree ), ["w"=>ns] );
for p in findall( "w:p", body_node, ["w"=>ns] )
# Let's keep the paragraph style separate – usually this node occurs once inside each paragraph.
pStyle = ""
pPr_node = findfirst("w:pPr", p, ["w"=>ns])
if !isnothing( pPr_node )
# We will not process a paragraph if it is a section separator.
if !isnothing( findfirst("w:sectPr", pPr_node, ["w"=>ns]) ) continue; end;
# The usual paragraph style
pStyle_node = findfirst("w:pStyle", pPr_node, ["w"=>ns]);
if !isnothing( pStyle_node ) pStyle = pStyle_node["w:val"]; end;
end;
# Now let's go through all the nodes of the run type (fragments of the paragraph)
pContent = []
element_name = nothing;
for run in findall("w:*", p, ["w"=>ns])
# run_name = run.name
if run.name == "pPr" continue; end;
runProperty_node = findfirst("w:rPr", run, ["w"=>ns])
run_content = run.content;
if run.name == "customXml"
element_name = run["w:element"];
if element_name == "image"
imageNode = findfirst("w:customXmlPr", run, ["w"=>ns])
for attr in findall("w:attr", imageNode, ["w"=>ns])
if attr["w:name"] == "relationshipId"
run_content = attr["w:val"]; end
end
end
elseif run.name == "hyperlink" # Fragment type w:hyperlink
hyperlink_target = "w:docLocation" in attributes(run) ? run["w:docLocation"] : nothing;
run_content = (run.content, hyperlink_target)
else
element_name = nothing;
end;
append!( pContent, [(run.name, element_name, runProperty_node, run_content)] );
end
# Add a style and a paragraph to the list of cells
push!( parsed_mlx, (pStyle, pContent) )
end
return (parsed_mlx, ns)
end;
Let's create a function that returns meta information about illustrations for inclusion in the final document.
function process_image_info( image_name )
image_description = ""
image_name = lowercase(image_name)
if endswith( image_name, ".png" ) image_description = "image/png"
elseif endswith( image_name, ".jpg" ) image_description = "image/jpeg"
elseif endswith( image_name, ".jpeg" ) image_description = "image/jpeg"
elseif endswith( image_name, ".gif" ) image_description = "image/gif"
elseif endswith( image_name, ".svg" ) image_description = "image/svg+xml"
else image_description = "image/unknown"; end;
image_base64_prefix = "data:" * image_description * ";base64,"
return image_description, image_base64_prefix
end;
Converting a cell from XML format to JSON format.
function xml_text_cell_to_plain_text( cell_info, ns, rels_dict, media_files_list )
cell_type, content = cell_info
attachments = []
# Sometimes the cell style will set us the beginning of the output line (in markdown)
if cell_type == "title" plain_text = "# ";
elseif cell_type == "heading" plain_text = "## ";
else plain_text = ""; end;
for (run_name, run_element_type, runProperty_node, run_content) in content
if run_name == "pPr" continue
elseif run_name == "customXml"
# If the fragment is a mathematical expression
if run_element_type == "equation"
plain_text = plain_text * "\$" * run_content * "\$"
# If the fragment is an illustration
elseif run_element_type == "image"
image_name = split( rels_dict[run_content], "/")[end]
image_content = media_files_list[rels_dict[run_content]]
image_type, image_prefix = process_image_info( image_name )
image_base64_content = image_prefix * image_content
append!( attachments, [(image_name, image_type, image_base64_content)] )
plain_text = ""
end
# If the fragment is a hyperlink
elseif run_name == "hyperlink"
(hlink_name, hlink_target) = run_content
if isnothing(hlink_target) plain_text = plain_text * hlink_name;
else plain_text = plain_text * "[" * hlink_name * "](" * hlink_target * ")"; end;
# If the fragment is a code expression (monospaced font)
elseif !isnothing(runProperty_node) && !isnothing(findfirst("w:rFonts", runProperty_node, ["w"=>ns])) && findfirst("w:rFonts", runProperty_node, ["w"=>ns])["w:cs"] == "monospace"
plain_text = plain_text * "`" * run_content * "`";
else
# There is just text in the cell
plain_text = plain_text * run_content;
end
end
return (cell_type, plain_text, attachments)
end;
A verification function for examining input files
You can check how many cells, media files, and other pieces of information have been read from each input .mlx the file.
for mlx_filename in get_list_of_files( "$(@__DIR__)/input" )
(mlx_file, rels_file, media_list) = get_mlx_content( mlx_filename )
println( )
println( "* File ", mlx_filename, " contains:" )
cell_list, ns = file_to_cells_list( mlx_file )
println( length([c for c in cell_list if c[1] != "code"]), " text cells")
println( length([c for c in cell_list if c[1] == "code"]), " code cells")
rels_dict = read_rels_file( rels_file )
if length(keys(rels_dict)) > 0
print( length(keys(rels_dict)), " references to external files" );
println( " (of these ", length([trg for (ref,trg) in rels_dict if occursin("../media", trg)]), " in the illustration)")
end;
end
Creating a template for the final ngscript files
Now we need to prepare the file. .ngscript, in which we will place the cells of our document. The Engee script format ensures backward compatibility, although changes sometimes occur. To have a fairly fresh document template ngscript let's use as a template the same document that is currently open in front of you – the script. mlx_to_ngscript_parser.ngscript.
Upload a sample file ngscript And we'll make it out of it:
- Document template,
- text cell template,
- Code cell template,
which we will supplement with information as we process the input mlx files.
doc_template = JSON.parsefile( "$(@__DIR__)/mlx_to_ngscript_parser.ngscript" );
code_cell_template = [c for c in doc_template["cells"] if c["cell_type"]=="code" ][1];
text_cell_template = [c for c in doc_template["cells"] if c["cell_type"]=="markdown" ][1];
text_cell_template["isParagraph"] = false; # Edit to create a "regular" paragraph rather than a headline
doc_template["cells"] = [];
Let's see what templates we got.:
doc_template
text_cell_template
code_cell_template
These three templates will be enough for us to generate a new one. .ngscript a file for each file .mlx in the directory of input files.
Filling in the JSON template
In the final function of this script, we will do the following:
- Let's go through all of them
mlxfiles in the directory - We will process the contents of each file
- For each, we will create a script template
ngscript - We will add text and code cells to it one at a time, not forgetting about graphic attachments.
In addition, we will create everything necessary to make the script in the language MATLAB it could have been run in an environment of Engee:
- We will add a call to the required library at the beginning of the file.,
- For all cells where graph output is called (for example,
plotandscatter), we will add commands to save the graph to the file storage and output it using the libraryImages.jlso that the graph appears in the report.
for mlx_filename in get_list_of_files( "$(@__DIR__)/input" )
# Let's find out everything we need about the next mlx file being studied.
(mlx_file, rels_file, media_list) = get_mlx_content( mlx_filename )
cell_list, ns = file_to_cells_list( mlx_file )
rels_dict = read_rels_file( rels_file )
# Create a template for a new document and add a new cell with the initialization code
ngscript_doc = deepcopy(doc_template);
new_cell = deepcopy( code_cell_template );
new_cell["source"][1] = "using MATLAB\nmat\"cd('\$(@__DIR__)')\"";
push!( ngscript_doc["cells"], new_cell ); # Adding a cell to the document
for cell in cell_list
cell_type, plain_text, attachments = xml_text_cell_to_plain_text( cell, ns, rels_dict, media_list )
plot_counter = 0
if cell_type == "code"
# Transfer the MATLAB code to the cell and add a frame in the form of the mat prefix"""..."""
new_cell = deepcopy( code_cell_template )
new_cell["source"][1] = "mat\"\"\"\n" * plain_text * "\n\"\"\"";
# If the cell contains the substring plot, add
# MATLAB-instructions for saving a graph
# and Engee-instructions for removing it in the report
if cell_type == "code" && occursin("plot", plain_text) || occursin("scatter", plain_text)
new_cell["source"][1] = "mat\"\"\"\n" * plain_text * "\nsaveas(gcf,'plot_$(plot_counter).png')\n\"\"\"\nusing Images; load(\"plot_$(plot_counter).png\")";
plot_counter = plot_counter + 1;
end;
push!( ngscript_doc["cells"], new_cell );
else
# Adding a text cell
new_cell = deepcopy( text_cell_template )
new_cell["source"][1] = plain_text
# Adding attachments to the cell
if length(attachments) != 0
for (image_name, image_type, image_base64_content) in attachments
new_cell["attachments"][image_name] = Dict()
new_cell["attachments"][image_name][image_type] = image_base64_content
end
end
push!( ngscript_doc["cells"], new_cell )
end
end
# Let's save the script under a new name
new_script_name = replace( mlx_filename, ".mlx" => ".ngscript" )
new_script_name = replace( new_script_name, "input" => "output")
# Let's pre-serialize and save the ngscript
stringdata = JSON.json( ngscript_doc )
open(new_script_name, "w") do f write(f, stringdata); end;
end
Conclusion
In this demo, we converted a file from the format MLX/OPC (based on ZIP/XML) in the format ngscript (based on JSON). The result is a tool that converts part of the information from a set of documents LiveScript Wednesday MATLAB in the documents .ngscript Engee platforms.
From the individual functions of this example, you can learn ideas about opening files, working with data in XML format, and generating documents based on JSON. This example also demonstrates the strong capabilities of Engee in terms of organizing technical computing available in conjunction with model-oriented design tools.