Глубокая сверточная генеративно-состязательная сеть (DCGAN)
Это руководство для начинающих по генерированию изображений рукописных цифр с помощью глубокой сверточной генеративно-состязательной сети, основанное на руководстве TensorFlow по сетям DCGAN.
Что такое GAN?
Генеративно-состязательные сети, или просто GAN, впервые описанные в статье Гудфеллоу с соавторами, стали одной из самых инновационных идей в современном машинном обучении. Сети GAN широко применяются в области обработки изображений и звука для генерирования высококачественных искусственных данных, которые можно легко выдавать за реальные.
Сеть GAN состоит из двух подмоделей: генератора и дискриминатора, которые действуют друг против друга. Генератор можно уподобить художнику, который рисует (генерирует) новые изображения, похожие на настоящие, а дискриминатор — критику, который учится отличать настоящие изображения от поддельных.
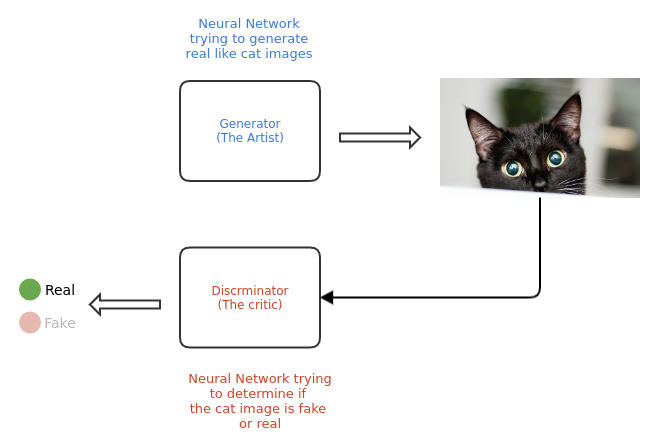
Изначально генератор и дискриминатор GAN ничего или почти ничего не знают о базовых данных. В ходе обучения генератор постепенно учится создавать изображения, все более похожие на настоящие, а дискриминатор все лучше их отличает. Процесс достигает равновесия, когда дискриминатор больше не может отличить реальные изображения от поддельных.
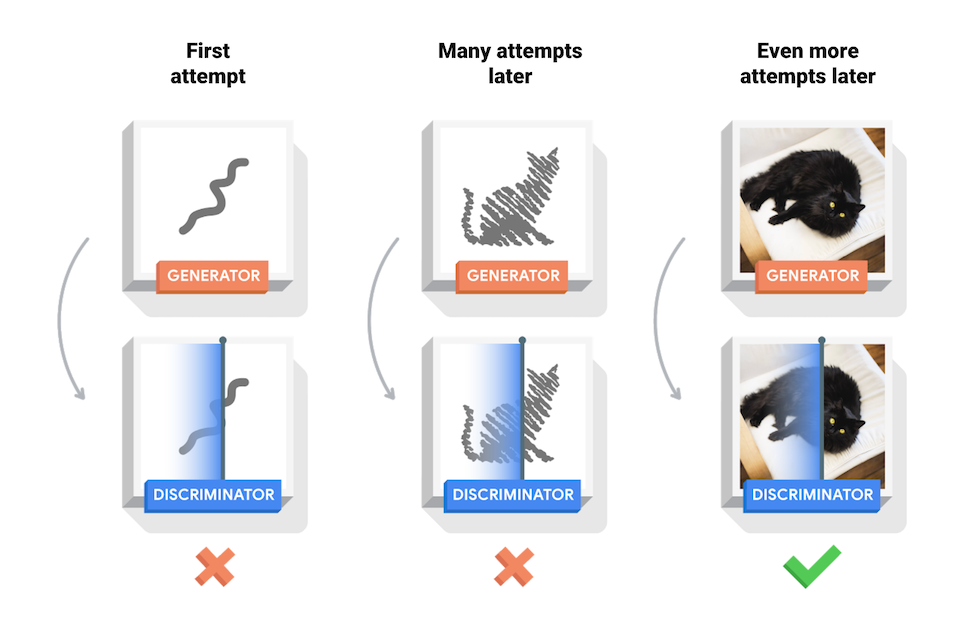
В этом руководстве демонстрируется процесс обучения сети DCGAN на основе набора данных MNIST рукописных цифр. На анимации показана последовательность изображений, создаваемых генератором, который обучался в течение 25 эпох. Начинается все со случайного шума, но постепенно изображения становятся все более похожими на рукописные цифры.

Настройка
Прежде чем приступать к реализации DCGAN, необходимо установить ряд пакетов Julia.
using Pkg
# Активируем новую среду проекта в текущем каталоге
Pkg.activate(".")
# Добавляем в среду необходимые пакеты
Pkg.add(["Images", "Flux", "MLDatasets", "CUDA", "Parameters"])Примечание. В зависимости от скорости подключения к Интернету на установку пакетов может потребоваться несколько минут.
После установки библиотек загрузите необходимые пакеты и функции:
using Base.Iterators: partition
using Printf
using Statistics
using Random
using Images
using Flux: params, DataLoader
using Flux.Optimise: update!
using Flux.Losses: logitbinarycrossentropy
using MLDatasets: MNIST
using CUDAДалее мы задаем значения по умолчанию для скорости обучения, размера пакетов, эпох, использования устройства GPU (если оно доступно) и других гиперпараметров модели.
Base.@kwdef struct HyperParams
batch_size::Int = 128
latent_dim::Int = 100
epochs::Int = 25
verbose_freq::Int = 1000
output_dim::Int = 5
disc_lr::Float64 = 0.0002
gen_lr::Float64 = 0.0002
device::Function = gpu
endЗагрузка данных
Как уже говорилось, мы будем использовать набор данных MNIST с рукописными цифрами. Поэтому мы начнем с простой функции для загрузки и предварительной обработки изображений MNIST:
function load_MNIST_images(hparams)
images = MNIST.traintensor(Float32)
# Нормализуем изображения к (-1, 1)
normalized_images = @. 2f0 * images - 1f0
image_tensor = reshape(normalized_images, 28, 28, 1, :)
# Создаем объект dataloader, который выполняет итерацию по мини-пакетам тензора изображений
dataloader = DataLoader(image_tensor, batchsize=hparams.batch_size, shuffle=true)
return dataloader
endДополнительные сведения о загрузке изображений во Flux см. в этом руководстве.
Примечание. Данные, возвращаемые объектом dataloader, загружаются в память ЦП. Для обучения на GPU необходимо предварительно передать данные в память GPU.
Создание моделей
Генератор
Наш генератор, то есть художник, — это нейронная сеть, которая сопоставляет данные низкой размерности с формой высокой размерности.
-
Этими начальными низкоразмерными данными обычно является вектор случайных значений, выбранных из нормального распределения.
-
Данные высокой размерности — это генерируемое изображение.
Слой Dense принимает на входе начальные данные, которые несколько раз подвергаются повышающей дискретизации с помощью слоя ConvTranspose, пока не будет достигнут требуемый размер выходных данных (в данном случае 28 x 28 x 1). Кроме того, после каждого слоя ConvTranspose мы применяем пакетную нормализацию, чтобы стабилизировать процесс обучения.
Мы будем использовать функцию активации relu для каждого слоя, кроме выходного, где применяется активация tanh.
Мы также применим метод инициализации весов, описанный в оригинальной статье о DCGAN.
# Функция для инициализации весов модели значениями,
# выбранными из гауссова распределения с μ=0 и σ=0,02
dcgan_init(shape...) = randn(Float32, shape) * 0.02f0function Generator(latent_dim)
Chain(
Dense(latent_dim, 7*7*256, bias=false),
BatchNorm(7*7*256, relu),
x -> reshape(x, 7, 7, 256, :),
ConvTranspose((5, 5), 256 => 128; stride = 1, pad = 2, init = dcgan_init, bias=false),
BatchNorm(128, relu),
ConvTranspose((4, 4), 128 => 64; stride = 2, pad = 1, init = dcgan_init, bias=false),
BatchNorm(64, relu),
# Активация tanh обеспечивает нахождение выхода в диапазоне (-1, 1)
ConvTranspose((4, 4), 64 => 1, tanh; stride = 2, pad = 1, init = dcgan_init, bias=false),
)
endПора устроить небольшую проверку! Мы создадим фиктивный генератор и подадим в него случайный вектор в качестве начальных данных. В случае правильной инициализации генератора он вернет массив размером (28, 28, 1, batch_size). При неправильном размере выходных данных макрос @assert в Julia вызовет исключение.
# Создаем фиктивный генератор с латентным измерением 100
generator = Generator(100)
noise = randn(Float32, 100, 3) # Последняя ось — это размер пакета
# Подаем в генератор случайный шум
gen_image = generator(noise)
@assert size(gen_image) == (28, 28, 1, 3)Нашей модели генератора еще предстоит обучиться правильным весам, поэтому пока она не выдает похожее на что-либо изображение. Чтобы обучить наш неумелый генератор, нужен его оппонент, дискриминатор.
Дискриминатор
Дискриминатор — это простой классификатор изображений на основе CNN. Слой Conv используется с функцией активации leakyrelu.
function Discriminator()
Chain(
Conv((4, 4), 1 => 64; stride = 2, pad = 1, init = dcgan_init),
x->leakyrelu.(x, 0.2f0),
Dropout(0.3),
Conv((4, 4), 64 => 128; stride = 2, pad = 1, init = dcgan_init),
x->leakyrelu.(x, 0.2f0),
Dropout(0.3),
# Теперь выходные данные имеют форму (7, 7, 128, размер_пакета)
flatten,
Dense(7 * 7 * 128, 1)
)
endБолее подробные сведения о реализации классификатора изображений на основе CNN см. в этом руководстве.
Теперь давайте проверим, работает ли наш дискриминатор.
# Фиктивный дискриминатор
discriminator = Discriminator()
# Передаем в дискриминатор сгенерированное изображение
logits = discriminator(gen_image)
@assert size(logits) == (1, 3)Как и в случае с фиктивным генератором, необученный дискриминатор не знает, какое изображение настоящее, а какое — поддельное. Он должен обучаться одновременно с генератором, чтобы выдавать положительные значения для настоящих изображений и отрицательные — для поддельных.
Функции потерь для GAN
В задаче GAN задействуются только две метки: «поддельное» и «настоящее». Поэтому естественным выбором для предварительной функции потерь будет бинарная перекрестная энтропия.
Но хотя во Flux есть функция binarycrossentropy для этой цели, для обеспечения численной устойчивости всегда желательно вычислять перекрестную энтропию с помощью логитов. Для этого во Flux есть специальная функция logitbinarycrossentropy. С математической точки зрения она эквивалентна binarycrossentropy(σ(ŷ), y, kwargs...).
Потери дискриминатора
Потери дискриминатора количественно выражают то, насколько хорошо дискриминатор может отличать настоящие изображения от поддельных. С их помощью сравнивается следующее:
-
прогнозы дискриминатора для настоящих изображений с массивом, состоящим из единиц;
-
прогнозы дискриминатора для поддельных (сгенерированных) изображений с массивом, состоящим из нулей.
Эти два значения потерь суммируются для получения скалярных потерь. Поэтому функцию потерь дискриминатора можно записать в следующем виде:
function discriminator_loss(real_output, fake_output)
real_loss = logitbinarycrossentropy(real_output, 1)
fake_loss = logitbinarycrossentropy(fake_output, 0)
return real_loss + fake_loss
endПотери генератора
Потери генератора количественно выражают то, насколько хорошо он умеет обманывать дискриминатор. Очевидно, что если генератор хорошо справляется со своей задачей, дискриминатор будет классифицировать поддельные изображения как настоящие (1).
generator_loss(fake_output) = logitbinarycrossentropy(fake_output, 1)Для нашей сети также необходимы оптимизаторы. Если вы не знаете, что это такое, прочитайте эту статью. И для генератора, и для дискриминатора мы будем использовать оптимизатор ADAM.
Вспомогательные функции
Выходные значения генератора находятся в диапазоне (-1, 1), и чтобы представить их как изображение, их необходимо денормализовать. Для удобства мы определим функцию для визуализации выходных данных генератора в виде сетки изображений.
function create_output_image(gen, fixed_noise, hparams)
fake_images = cpu(gen.(fixed_noise))
image_array = reduce(vcat, reduce.(hcat, partition(fake_images, hparams.output_dim)))
image_array = permutedims(dropdims(image_array; dims=(3, 4)), (2, 1))
image_array = @. Gray(image_array + 1f0) / 2f0
return image_array
endОбучение
Чтобы упростить задачу обучения, мы вынесем обучение генератора и дискриминатора в две отдельные функции.
function train_discriminator!(gen, disc, real_img, fake_img, opt, ps, hparams)
disc_loss, grads = Flux.withgradient(ps) do
discriminator_loss(disc(real_img), disc(fake_img))
end
# Обновляем параметры дискриминатора
update!(opt, ps, grads)
return disc_loss
endДля генератора определим похожую функцию.
function train_generator!(gen, disc, fake_img, opt, ps, hparams)
gen_loss, grads = Flux.withgradient(ps) do
generator_loss(disc(fake_img))
end
update!(opt, ps, grads)
return gen_loss
endОпределив все необходимые функции, мы объединяем их в одну функцию train, которая сначала настраивает все модели и оптимизаторы, а затем обучает сеть GAN в течение указанного количества эпох.
function train(hparams)
dev = hparams.device
# Проверяем доступность CUDA
if hparams.device == gpu
if !CUDA.has_cuda()
dev = cpu
@warn "No gpu found, falling back to CPU"
end
end
# Загружаем нормализованные изображения MNIST
dataloader = load_MNIST_images(hparams)
# Инициализируем модели и передаем их в соответствующее устройство
disc = Discriminator() |> dev
gen = Generator(hparams.latent_dim) |> dev
# Собираем параметры генератора и дискриминатора
disc_ps = params(disc)
gen_ps = params(gen)
# Инициализируем оптимизаторы ADAM для обеих подмоделей
# с соответствующими скоростями обучения
disc_opt = ADAM(hparams.disc_lr)
gen_opt = ADAM(hparams.gen_lr)
# Создаем пакет фиксированного шума для визуализации обучения генератора с течением времени
fixed_noise = [randn(Float32, hparams.latent_dim, 1) |> dev for _=1:hparams.output_dim^2]
# Цикл обучения
train_steps = 0
for ep in 1:hparams.epochs
@info "Epoch $ep"
for real_img in dataloader
# Передаем данные на GPU
real_img = real_img |> dev
# Создаем случайный шум
noise = randn!(similar(real_img, (hparams.latent_dim, hparams.batch_size)))
# Передаем шум в генератор для создания искусственного изображения
fake_img = gen(noise)
# Обновляем дискриминатор и генератор
loss_disc = train_discriminator!(gen, disc, real_img, fake_img, disc_opt, disc_ps, hparams)
loss_gen = train_generator!(gen, disc, fake_img, gen_opt, gen_ps, hparams)
if train_steps % hparams.verbose_freq == 0
@info("Train step $(train_steps), Discriminator loss = $(loss_disc), Generator loss = $(loss_gen)")
# Сохраняем сгенерированное искусственное изображение
output_image = create_output_image(gen, fixed_noise, hparams)
save(@sprintf("output/dcgan_steps_%06d.png", train_steps), output_image)
end
train_steps += 1
end
end
output_image = create_output_image(gen, fixed_noise, hparams)
save(@sprintf("output/dcgan_steps_%06d.png", train_steps), output_image)
return nothing
endНаконец, мы можем обучить GAN:
# Определяем гиперпараметры (здесь мы оставляем значения по умолчанию)
hparams = HyperParams()
train(hparams)Вывод
Сгенерированные изображения хранятся в папке output. Для визуализации выходных данных генератора с течением времени мы создаем GIF-файл со сгенерированными изображениями.
folder = "output"
# Получаем имена файлов изображений из папки
img_paths = readdir(folder, join=true)
# Загружаем все изображения как массив
images = load.(img_paths)
# Объединяем все изображения в массиве для создания матрицы изображений
gif_mat = cat(images..., dims=3)
save("./output.gif", gif_mat)Ресурсы и ссылки
|
Впервые опубликовано на сайте fluxml.ai 8 октября 2021 г. автором Деептенду Сантра (Deeptendu Santra) |