Руководство. Линейная регрессия
Flux представляет собой чистый стек машинного обучения Julia, позволяющий строить модели прогнозирования. Ниже приведены шаги типичной программы Flux.
-
Предоставление обучающих и тестовых данных
-
Построение модели с настраиваемыми параметрами для составления прогнозов
-
Итеративное обучение модели с изменением параметров для улучшения прогнозов
-
Проверка модели На внутреннем уровне Flux использует технику автоматического дифференцирования для получения градиентов, которые помогают улучшить прогнозы. Flux также полностью написан на Julia, поэтому вы можете легко заменить любой слой Flux своим собственным кодом, чтобы улучшить понимание или выполнить особые требования.
На этой странице приводится пошаговое руководство по использованию алгоритма линейной регрессии в Julia с применением Flux. Мы начнем с создания простой модели линейной регрессии для фиктивных данных, а затем перейдем к реальному набору данных. В первой части потребуется написать некоторые части модели самостоятельно, но далее они будут заменены компонентами Flux.
Начнем с построения простой модели линейной регрессии. Эта модель будет обучаться на точках данных в формате (x₁, y₁), (x₂, y₂), ... , (xₙ, yₙ). В реальных ситуациях у x может быть множество признаков, а y означает метку. В нашем примере у каждого x один признак. Таким образом, наши данные будут состоять из n точек данных, каждая из которых сопоставляет один признак с одной меткой.
Импорт необходимых пакетов Julia:
julia> using Flux, PlotsГенерирование набора данных
Обычно данные берутся из реального мира, и такой случай мы рассмотрим в последней части данного руководства. Пока же начнем с более простой ситуации. Здесь мы генерируем координаты x точек данных и сопоставляем их с соответствующими координатами y с помощью простой функции. Напомним, что здесь каждый x эквивалентен признаку, а каждый y — это соответствующая метка. При объединении всех x и y формируется полный набор данных.
julia> x = hcat(collect(Float32, -3:0.1:3)...)
1×61 Matrix{Float32}:
-3.0 -2.9 -2.8 -2.7 -2.6 -2.5 … 2.4 2.5 2.6 2.7 2.8 2.9 3.0Вызов hcat генерирует объект Matrix, содержащий числа от -3.0 до 3.0 с шагом 0.1. В каждом столбце этой матрицы содержится отдельный x, всего 61 координата x. На следующем шаге следует сгенерировать соответствующие метки (y).
julia> f(x) = @. 3x + 2;
julia> y = f(x)
1×61 Matrix{Float32}:
-7.0 -6.7 -6.4 -6.1 -5.8 -5.5 … 9.5 9.8 10.1 10.4 10.7 11.0Функция f сопоставляет каждый x с y, а так как координаты x сведены в Matrix, выражение транслирует скалярные значения с помощью макроса @.. Точки данных готовы, но они слишком идеальны. В реальном сценарии функции f для генерирования значений y не было бы. Вместо этого пришлось бы добавлять метки вручную.
julia> x = x .* reshape(rand(Float32, 61), (1, 61));Визуализация итоговых данных:
julia> plot(vec(x), vec(y), lw = 3, seriestype = :scatter, label = "", title = "Generated data", xlabel = "x", ylabel= "y");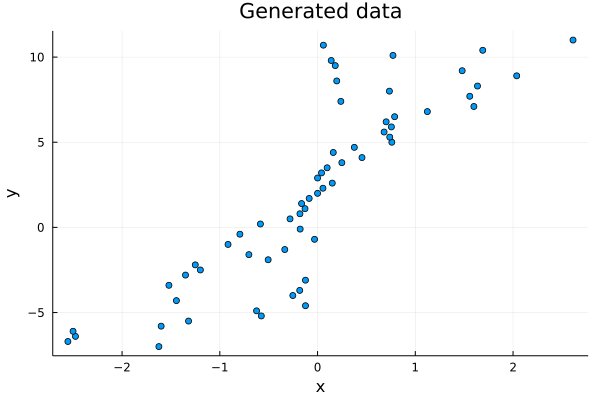
Теперь данные выглядят достаточно случайными. Однако значения x и y все еще имеют некоторую корреляцию, поэтому алгоритм линейной регрессии хорошо подойдет для такого набора данных.
Теперь можно продолжить и построить модель для нашего набора данных.
Построение модели
Модель линейной регрессии математически выражается так:
где W — матрица весов, а b — смещение. В нашем случае матрица весов (W) будет состоять из единственного элемента, так как признак только один. Определить нашу модель в Julia можно в точно такой же форме!
julia> custom_model(W, b, x) = @. W*x + b
custom_model (generic function with 1 method)Макрос @. позволяет выполнять вычисления путем трансляции скалярных величин (например, смещения).
Далее необходимо инициализировать параметры модели, то есть вес и смещение. Для разных моделей машинного обучения существует множество методов инициализации, но для данного примера давайте возьмем вес из равномерного распределения и инициализируем смещение со значением 0.
julia> W = rand(Float32, 1, 1)
1×1 Matrix{Float32}:
0.99285793
julia> b = [0.0f0]
1-element Vector{Float32}:
0.0Пора проверить, работает ли наша модель.
julia> custom_model(W, b, x) |> size
(1, 61)
julia> custom_model(W, b, x)[1], y[1]
(-1.6116865f0, -7.0f0)Работает! Но прогнозы совершенно неверные. Чтобы улучшить их, необходимо обучить модель, но перед этим следует определить функцию потерь. В идеале функция потерь должна возвращать величину, которую мы будем пытаться минимизировать в течение всего процесса обучения. Здесь в качестве функции потерь мы используем среднеквадратическую сумму погрешностей.
julia> function custom_loss(W, b, x, y)
ŷ = custom_model(W, b, x)
sum((y .- ŷ).^2) / length(x)
end;
julia> custom_loss(W, b, x, y)
23.772217f0Вызвав функцию потерь для значений x и y, можно увидеть, насколько прогнозы (ŷ) далеки от реальных меток. Если быть точнее, она вычисляет сумму квадратов остаточных погрешностей и делит ее на общее количество точек данных.
Мы успешно определили модель и функцию потерь, но, что удивительно, пока не прибегали к Flux. Давайте посмотрим, как написать тот же код с использованием Flux.
julia> flux_model = Dense(1 => 1)
Dense(1 => 1) # 2 параметраDense(1 => 1) означает слой с одним нейроном, имеющим один вход (признак) и один выход. Этот слой в точности соответствует определенной выше математической модели. На внутреннем уровне Flux вычисляет выход с использованием того же выражения! Но на этот раз нам не нужно самим инициализировать параметры — Flux сделает это за нас.
julia> flux_model.weight, flux_model.bias
(Float32[-1.2678515;;], Float32[0.0])Теперь можно проверить, правильно ли работает модель. Мы можем передать сразу все данные, где каждый x имеет ровно один признак (вход):
julia> flux_model(x) |> size
(1, 61)
julia> flux_model(x)[1], y[1]
(-1.8525281f0, -7.0f0)Работает! Следующий шаг — определение функции потерь с помощью функций Flux:
julia> function flux_loss(flux_model, x, y)
ŷ = flux_model(x)
Flux.mse(ŷ, y)
end;
julia> flux_loss(flux_model, x, y)
22.74856f0Все работает, как и прежде! Похоже на то, будто Flux предоставляет нам эффективные оболочки для функций, которые иначе пришлось бы писать самим. Наконец, в качестве последнего шага в этом разделе, давайте посмотрим, насколько flux_model отличается от custom_model. Для этого неплохо будет задать фиксированные одинаковые значения для параметров обеих моделей. Давайте изменим параметры custom_model так, чтобы они соответствовали параметрам flux_model:
julia> W = Float32[1.1412252]
1-element Vector{Float32}:
1.1412252Чтобы проверить, как обе модели справляются со своей задачей на основе этих данных, давайте определим потери с помощью функций loss и flux_loss:
julia> custom_loss(W, b, x, y), flux_loss(flux_model, x, y)
(22.74856f0, 22.74856f0)Потери одинаковые! Это означает, что наши модели model и flux_model в какой-то степени равносильны и функции потерь полностью идентичны! Различие между моделями состоит в том, что слой Dense во Flux поддерживает множество других аргументов, с помощью которых его можно настроить дополнительно. Но в рамках данного руководства давайте ограничимся нашей простой моделью custom_model.
Обучение модели
Давайте обучим нашу модель с помощью классического алгоритма градиентного спуска. Согласно алгоритму градиентного спуска веса и смещения должны итеративно обновляться по следующим математическим уравнениям:
Здесь W — матрица весов, b — вектор смещений, — скорость обучения, — производная функции потерь относительно веса, а — производная функции потерь относительно смещения.
Производные вычисляются с помощью инструмента автоматического дифференцирования. Во Flux для этой цели применяется Zygote.jl. Так как Zygote.jl — это автономный пакет Julia, его можно использовать и без Flux. Дополнительные сведения см. в документации по Zygote.jl.
В первую очередь следует получить градиент функции потерь относительно весов и смещений. Flux повторно экспортирует функцию gradient из Zygote, поэтому импортировать Zygote явным образом для ее использования не требуется.
julia> dLdW, dLdb, _, _ = gradient(custom_loss, W, b, x, y);Теперь можно обновить параметры по алгоритму градиентного спуска:
julia> W .= W .- 0.1 .* dLdW
1-element Vector{Float32}:
1.8144473
julia> b .= b .- 0.1 .* dLdb
1-element Vector{Float32}:
0.41325632Параметры обновлены. Теперь можно проверить значение функции потерь:
julia> custom_loss(W, b, x, y)
17.157953f0Потери уменьшились! Это значит, что мы успешно обучили модель за одну эпоху. Мы можем ввести написанный выше код обучения в цикл и обучить модель в течение большего числа эпох. Можно настроить фиксированное количество эпох либо остановку при соблюдении какого-либо условия, например change in loss < 0.1. Цикл можно адаптировать под потребности пользователя, а условия указывать в виде обычного кода Julia.
Давайте включим логику обучения в функцию и повторим тестирование:
julia> function train_custom_model()
dLdW, dLdb, _, _ = gradient(custom_loss, W, b, x, y)
@. W = W - 0.1 * dLdW
@. b = b - 0.1 * dLdb
end;
julia> train_custom_model();
julia> W, b, custom_loss(W, b, x, y)
(Float32[2.340657], Float32[0.7516814], 13.64972f0)Модель работает, а потери уменьшились еще больше! Это была вторая эпоха процесса обучения. Давайте добавим логику в цикл for и обучим модель в течение 30 эпох.
julia> for i = 1:40
train_custom_model()
end
julia> W, b, custom_loss(W, b, x, y)
(Float32[4.2422233], Float32[2.2460847], 7.6680417f0)Потери существенно снизились, и параметры обновились.
Можно обучать модель дольше или подобрать гиперпараметры так, чтобы нужный результат достигался быстрее, но давайте остановимся на этом. Мы обучали модель в течение 42 эпох, и потери снизились с 22.74856 до 7.6680417f. Пора приступать к визуализации.
Результаты
Главной целью этого руководства было построить линию по точкам из набора данных с помощью алгоритма линейной регрессии. Обучение прошло успешно, и потери существенно уменьшились. Давайте посмотрим, как выглядит построенная линия. Напомним, что Wx + b — это попросту уравнение прямой, где slope = W[1], а y-intercept = b[1] (с индексацией от 1, так как W и b — итерируемые объекты).
Построим прямую и точки данных с помощью Plot.jl:
julia> plot(reshape(x, (61, 1)), reshape(y, (61, 1)), lw = 3, seriestype = :scatter, label = "", title = "Simple Linear Regression", xlabel = "x", ylabel= "y");
julia> plot!((x) -> b[1] + W[1] * x, -3, 3, label="Custom model", lw=2);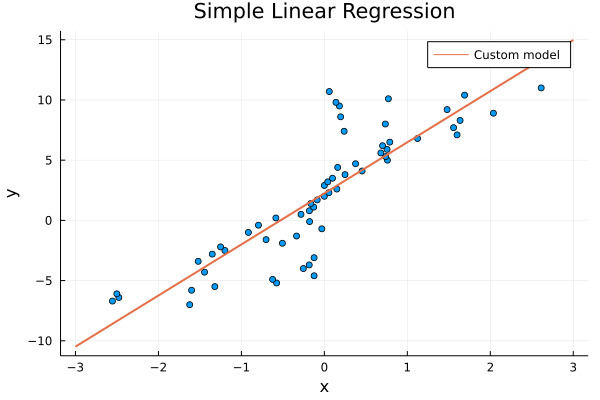
Прямая хорошо соответствует данным. Есть что улучшить, но оставим это вам! Вы можете поэкспериментировать с оптимизаторами, количеством эпох, скоростью обучения и другими параметрами, чтобы улучшить соответствие и уменьшить потери!
Модель линейной регрессии на основе реального набора данных
Теперь перейдем к сравнительно сложной модели линейной регрессии. Здесь мы используем реальный набор данных MLDatasets.jl, в котором точки данных не ограничены одним признаком. Сначала импортируем необходимые пакеты:
julia> using Flux, Statistics, MLDatasets, DataFramesСбор реальных данных
Сначала инициализируем набор данных. Мы будем использовать набор данных BostonHousing, состоящий из 506 точек данных. У каждой из этих точек 13 признаков и соответствующая метка — цена дома. Каждая координата x по-прежнему сопоставлена с единственной меткой y, но теперь у одного x 13 признаков.
julia> dataset = BostonHousing();
julia> x, y = BostonHousing(as_df=false)[:];
julia> x, y = Float32.(x), Float32.(y);Теперь можно разделить полученные данные на обучающий и проверочный наборы:
julia> x_train, x_test, y_train, y_test = x[:, 1:400], x[:, 401:end], y[:, 1:400], y[:, 401:end];
julia> x_train |> size, x_test |> size, y_train |> size, y_test |> size
((13, 400), (13, 106), (1, 400), (1, 106))Эти данные содержат разное количество признаков, то есть у признаков разный масштаб. В данном случае было бы разумно нормализовать (normalise) данные, чтобы сделать процесс обучения эффективнее и быстрее. Перед нормализацией давайте проверим среднеквадратичное отклонение обучающих данных.
julia> std(x_train)
134.06786f0Данные действительно не нормализованы. Нормализовать обучающие данные можно с помощью функции Flux.normalise.
julia> x_train_n = Flux.normalise(x_train);
julia> std(x_train_n)
1.0000844f0Теперь среднеквадратичное отклонение близко к единице. Данные готовы!
Построение модели Flux
Теперь можно напрямую воспользоваться пакетом Flux, чтобы переложить на него всю работу! Давайте определим модель, которая принимает 13 входов (признаков) и выдает один выход (метку). Затем мы пропустим через эту модель сразу все данные, и обо всем позаботится Flux! Напомним, что модель можно было бы объявить и в виде обычного кода Julia. У модели будет 14 параметров: 13 весов и 1 смещение.
julia> model = Dense(13 => 1)
Dense(13 => 1) # 14 параметровКак и ранее, следующим этапом необходимо определить функцию потерь для количественной оценки точности. Чем меньше потери, тем лучше модель.
julia> function loss(model, x, y)
ŷ = model(x)
Flux.mse(ŷ, y)
end;
julia> loss(model, x_train_n, y_train)
676.1656f0Теперь можно перейти к этапу обучения.
Обучение модели Flux
Для процесса обучения будет использоваться та же математическая логика, но теперь можно передать модель в вызове gradient и доверить вычисление производных Flux и Zygote!
julia> function train_model()
dLdm, _, _ = gradient(loss, model, x_train_n, y_train)
@. model.weight = model.weight - 0.000001 * dLdm.weight
@. model.bias = model.bias - 0.000001 * dLdm.bias
end;В отличие от предыдущей процедуры обучения, на этот раз мы решаем, что не хотим задавать фиксированное количество эпох в коде. Мы хотим, чтобы обучение прекращалось при сходимости потерь, то есть когда change in loss < δ. Величину δ можно изменять так, как нужно пользователю, но в данном руководстве давайте зададим ее равной 10⁻³.
Такие пользовательские циклы обучения можно легко создавать с помощью Flux и обычного кода Julia!
julia> loss_init = Inf;
julia> while true
train_model()
if loss_init == Inf
loss_init = loss(model, x_train_n, y_train)
continue
end
if abs(loss_init - loss(model, x_train_n, y_train)) < 1e-4
break
else
loss_init = loss(model, x_train_n, y_train)
end
end;Сначала в коде инициализируется начальное значение потерь: infinity. Затем выполняется бесконечный цикл, который прерывается при change in loss < 10⁻³. Если это условие не выполняется, то значение loss_init изменяется на величину текущих потерь и начинается следующая итерация.
Этот пользовательский цикл работает! Данный пример демонстрирует, насколько легко пользователь может написать любую подпрограмму обучения с помощью Flux и Julia.
Давайте посмотрим на потери:
julia> loss(model, x_train_n, y_train)
27.1272f0Потери существенно уменьшились! Их можно снизить еще больше, выбрав еще меньшее значение δ.
Проверка модели Flux
На последнем этапе этого руководства мы протестируем модель с помощью проверочных данных. Сначала мы нормализуем проверочные данные, а затем вычислим соответствующие потери.
julia> x_test_n = Flux.normalise(x_test);
julia> loss(model, x_test_n, y_test)
66.91015f0Потери не так малы, как для обучающих данных, но приемлемы. Это также показывает, что модель не переобучается.
Подведем итог: мы начали с создания случайного, но скоррелированного набора данных для модели custom model. Мы увидели, как можно построить простую модель линейной регрессии с использованием и без использования Flux и что эти модели почти идентичны.
Затем мы обучили модель, вручную написав алгоритм градиентного спуска и оптимизировав потери. Мы также узнали, что Flux предоставляет различные оболочки и крайне простой и интуитивно понятный API для пользователей.
Ознакомившись с основами Flux и Julia, мы перешли к построению модели машинного обучения для реального набора данных. Мы повторили те же действия, но на этот раз с гораздо большим количеством признаков и точек данных и использованием всех возможностей Flux. Наконец, мы разработали более гибкий цикл обучения, чем жестко заданный, и запустили модель на нормализованном наборе данных.
|
Впервые опубликовано 21 ноября 2022 г. Автор: Саранш Чопра (Saransh Chopra). |