Руководство ReinforcementLearning
Одномерное случайное блуждание
Предположим, что агент находится в позиции 4 на следующей числовой оси. На каждом шаге он может сместиться влево или вправо. Эти действия представлены здесь соответственно как 1 и 2. По достижении конца оси игра завершается. Если агент останавливается в позиции 7, он получает награду +1, а если в позиции 1 — штраф -1. В остальных случаях награда равна 0.
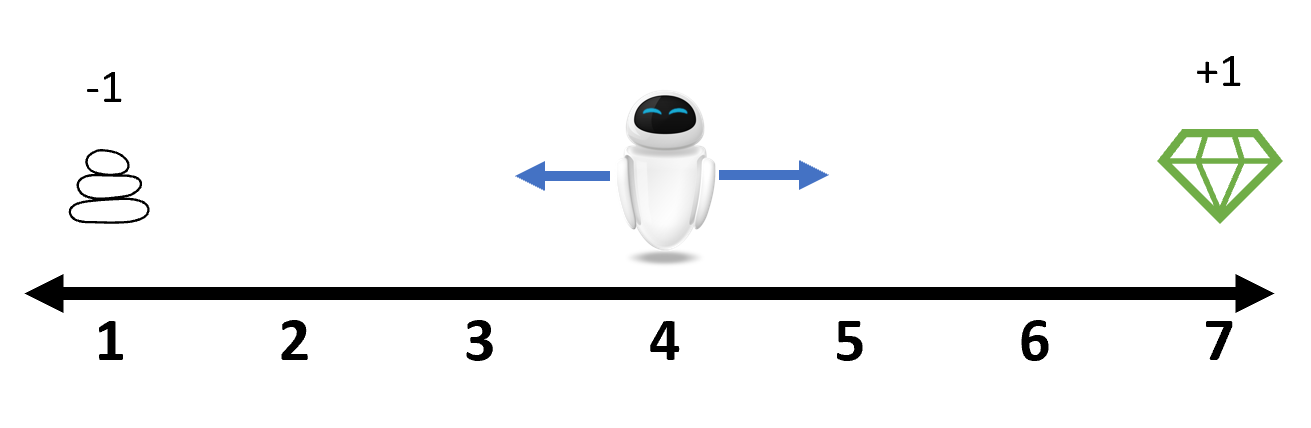
Для этого случая уже есть готовая среда RandomWalk1D. Давайте сначала ознакомимся с основными интерфейсами.
julia> using ReinforcementLearning
julia> env = RandomWalk1D()
# RandomWalk1D
## Traits
| Trait Type | Value |
|:----------------- | --------------------:|
| NumAgentStyle | SingleAgent() |
| DynamicStyle | Sequential() |
| InformationStyle | PerfectInformation() |
| ChanceStyle | Deterministic() |
| RewardStyle | TerminalReward() |
| UtilityStyle | GeneralSum() |
| ActionStyle | MinimalActionSet() |
| StateStyle | Observation{Int64}() |
| DefaultStateStyle | Observation{Int64}() |
| EpisodeStyle | Episodic() |
## Is Environment Terminated?
No
## State Space
`Base.OneTo(7)`
## Action Space
`Base.OneTo(2)`
## Current State
```
4
```
julia> S = state_space(env)
Base.OneTo(7)
julia> s = state(env) # начальное положение
4
julia> A = action_space(env)
Base.OneTo(2)
julia> is_terminated(env)
false
julia> while true
act!(env, rand(A))
is_terminated(env) && break
end
julia> state(env)
1
julia> reward(env)
-1.0Более подробное объяснение используемых выше функций приводится в ReinforcementLearningBase.jl.
В этой простой игре наша задача — найти оптимальную политику для агента, позволяющую получить максимальную совокупную награду за эпизод. Представленная выше политика случайного выбора является хорошей отправной точкой. Осталось лишь вычислить суммарную награду. Из-за распространенности такого рабочего процесса в задачах обучения с подкреплением предоставляется расширенная функция Base.run, позволяющая проектировать рабочий процесс описательным образом.
julia> run(
RandomPolicy(),
RandomWalk1D(),
StopAfterNEpisodes(10),
TotalRewardPerEpisode()
)
TotalRewardPerEpisode{Val{true}, Float64}([1.0, 1.0, 1.0, -1.0, 1.0, 1.0, -1.0, -1.0, 1.0, 1.0], 0.0, true)Далее давайте познакомимся с одной из самых распространенных политик, QBasedPolicy. Она состоит из двух частей: функции значений «состояние-действие» для оценки значения каждой пары «состояние-действие» и исследователя для выбора действия к выполнению в зависимости от результирующих значений «состояние-действие».
julia> NS = length(S)
7
julia> NA = length(A)
2
julia> policy = QBasedPolicy(
learner = TDLearner(
TabularQApproximator(
n_state = NS,
n_action = NA,
),
:SARS
),
explorer = EpsilonGreedyExplorer(0.1)
)
QBasedPolicy{TDLearner{:SARS, TabularQApproximator{Matrix{Float64}}}, EpsilonGreedyExplorer{:linear, false, TaskLocalRNG}}(TDLearner{:SARS, TabularQApproximator{Matrix{Float64}}}(TabularQApproximator{Matrix{Float64}}([0.0 0.0 … 0.0 0.0; 0.0 0.0 … 0.0 0.0]), 1.0, 0.01, 0), EpsilonGreedyExplorer{:linear, false, TaskLocalRNG}(0.1, 1.0, 0, 0, 1, TaskLocalRNG()))Здесь мы выбираем TDLearner и EpsilonGreedyExplorer. Но их можно заменить на какие-либо другие обучатели или исследователи Q-значений. Как и ранее, мы можем применить эту политику к среде env для оценки ее производительности.
julia> run(
policy,
RandomWalk1D(),
StopAfterNEpisodes(10),
TotalRewardPerEpisode()
)
TotalRewardPerEpisode{Val{true}, Float64}([-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], 0.0, true)До сих пор политики, с которыми мы встречались, были очень простыми. Они не предусматривали оптимизаций. Они находятся в так называемом режиме исполнителя, то есть на каждом шаге они только статически генерируют действия. Однако главной целью обучения с подкреплением является улучшение политики в ходе взаимодействий со средами. В таком случае говорится, что политика находится в режиме обучателя. Для выполнения политик в режиме обучателя имеется специальная политика-оболочка Agent .
julia> using ReinforcementLearningTrajectories
ERROR: ArgumentError: Package ReinforcementLearningTrajectories not found in current path, maybe you meant `import/using .ReinforcementLearningTrajectories`.
- Otherwise, run `import Pkg; Pkg.add("ReinforcementLearningTrajectories")` to install the ReinforcementLearningTrajectories package.
julia> trajectory = Trajectory(
ElasticArraySARTSTraces(;
state = Int64 => (),
action = Int64 => (),
reward = Float64 => (),
terminal = Bool => (),
),
DummySampler(),
InsertSampleRatioController(),
)
Trajectory{EpisodesBuffer{(:state, :next_state, :action, :reward, :terminal), Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, ElasticArraySARTSTraces{Tuple{MultiplexTraces{(:state, :next_state), Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Int64}, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, 5, Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}}, Vector{Int64}, BitVector}, DummySampler, InsertSampleRatioController, typeof(identity)}(@NamedTuple{state::Int64, next_state::Int64, action::Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, reward::Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, terminal::Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}[], DummySampler(), InsertSampleRatioController(1.0, 1, 0, 0), identity)
julia> agent = Agent(
policy = RandomPolicy(),
trajectory = trajectory
)
Agent{RandomPolicy{Nothing, TaskLocalRNG}, Trajectory{EpisodesBuffer{(:state, :next_state, :action, :reward, :terminal), Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, ElasticArraySARTSTraces{Tuple{MultiplexTraces{(:state, :next_state), Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Int64}, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, 5, Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}}, Vector{Int64}, BitVector}, DummySampler, InsertSampleRatioController, typeof(identity)}}(RandomPolicy{Nothing, TaskLocalRNG}(nothing, TaskLocalRNG()), Trajectory{EpisodesBuffer{(:state, :next_state, :action, :reward, :terminal), Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, ElasticArraySARTSTraces{Tuple{MultiplexTraces{(:state, :next_state), Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Int64}, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, 5, Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}}, Vector{Int64}, BitVector}, DummySampler, InsertSampleRatioController, typeof(identity)}(@NamedTuple{state::Int64, next_state::Int64, action::Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, reward::Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, terminal::Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}[], DummySampler(), InsertSampleRatioController(1.0, 1, 0, 0), identity))
julia> run(agent, env, StopAfterNEpisodes(10), TotalRewardPerEpisode())
TotalRewardPerEpisode{Val{true}, Float64}([1.0, 1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, -1.0], 0.0, true)Здесь объект Trajectory используется для сохранения информации о состоянии, действии, награде и завершении (SAR*T*) во время взаимодействий со средой.