Руководство. Генеративно-состязательные сети
В этом руководстве описывается реализация базовой генеративно-состязательной сети (GAN) с помощью Flux и процесс ее обучения на наборе данных MNIST. Они основаны на руководстве Pytorch. Оригинальная статья Гудфеллоу (Goodfellow) и соавторов, в которой впервые были описаны принципы GAN, может послужить отличным источником информации о назначении и теоретических основах GAN:
В предлагаемой схеме состязательной сети генеративная модель противостоит своему сопернику — дискриминантной модели, которая учится определять, происходит ли образец из распределения модели или распределения данных. Генеративную модель можно уподобить банде фальшивомонетчиков, которые подделывают деньги и пытаются сбыть их, не попавшись, а дискриминантную модель — полиции, которая должна распознать поддельные деньги. Это соперничество заставляет обе стороны улучшать свои методы до тех пор, пока подделка не станет неотличима от оригинала.
Давайте реализуем GAN во Flux. Для начала импортируем несколько полезных пакетов:
using MLDatasets: MNIST
using Flux.Data: DataLoader
using Flux
using CUDA
using Zygote
using UnicodePlotsЧтобы скачать пакет в REPL Julia, введите ] для перехода в пакетный режим, а затем введите add MLDatasets или выполните эту операцию с помощью модуля Pkg следующим образом:
> import Pkg
> Pkg.add("MLDatasets")Хотя библиотека UnicodePlots не является обязательной, с ее помощью можно визуализировать сгенерированные выборки в терминале во время обучения. Наблюдение результата напрямую, а не в отдельном окне значительно упрощает отладку.
Далее определим значения для скорости обучения, размера пакета, количества эпох и других гиперпараметров. На этом же этапе можно определить оптимизаторы для сети генератора и дискриминатора. Подробнее о том, что это такое, поговорим позже.
lr_g = 2e-4 # Скорость обучения сети генератора
lr_d = 2e-4 # Скорость обучения сети дискриминатора
batch_size = 128 # размер пакета
num_epochs = 1000 # Количество эпох обучения
output_period = 100 # Длина периода для графиков образцов генератора
n_features = 28 * 28# Количество пикселей в каждом образце из набора данных MNIST
latent_dim = 100 # Измерение скрытого пространства
opt_dscr = ADAM(lr_d)# Оптимизатор для дискриминатора
opt_gen = ADAM(lr_g) # Оптимизатор для генератораВ этом руководстве предполагается, что в системе, в которой выполняется скрипт, доступен GPU с поддержкой CUDA. Если это не так, просто удалите декораторы |>gpu: конвейеризация.
Загрузка данных
Набор данных MNIST доступен в репозитории MLDatasets. При первом создании экземпляра вам будет предложено его скачать. Дайте согласие.
Сети GAN можно обучать в неконтролируемом режиме. Поэтому оставьте только изображения из набора данных, исключив метки.
После загрузки обучающих данных необходимо нормализовать значения в диапазоне [0:1] к значениям в диапазоне [-1:1]. Обучение сетей GAN связано с известными сложностями, и такая нормализация является одним из рекомендуемых приемов. Нормализованные данные используются для определения загрузчика данных, который отвечает за формирование пакетов и перемешивание данных.
# Загрузка набора данных
train_x, _ = MNIST.traindata(Float32);
# В этом наборе данных пиксели имеют значения ∈ [0:1]. Сопоставим их с интервалом [-1:1]
train_x = 2f0 * reshape(train_x, 28, 28, 1, :) .- 1f0 |>gpu;
# DataLoader позволяет получать доступ к данным в пакетном режиме и отвечает за перемешивание.
train_loader = DataLoader(train_x, batchsize=batch_size, shuffle=true);Определение сетей
В стандартной сети GAN и дискриминатор, и генератор представляют собой обычные многослойные перцептроны с прямой связью. Для обеспечения нелинейности модели мы используем блоки линейной ректификации с утечками leakyrelu.
В данном случае коэффициент α (в leakyrelu ниже) устанавливается равным 0,2. Проведенные ранее эксперименты показали, что это значение обеспечивает эффективное обучение сети. Также было выявлено, что функция предотвращения переобучения обеспечивает хорошее обобщение обученной сети, поэтому мы используем ее ниже. Предотвращение переобучения обычно активно при обучении модели и неактивно при выводе. При вызове модели в градиентном контексте Flux автоматически активирует режим обучения. В качестве конечной нелинейности мы используем функцию активации sigmoid.
discriminator = Chain(Dense(n_features, 1024, x -> leakyrelu(x, 0.2f0)),
Dropout(0.3),
Dense(1024, 512, x -> leakyrelu(x, 0.2f0)),
Dropout(0.3),
Dense(512, 256, x -> leakyrelu(x, 0.2f0)),
Dropout(0.3),
Dense(256, 1, sigmoid)) |> gpuГенератор определим сходным образом. Эта сеть сопоставляет латентную переменную (переменную, которая не наблюдается напрямую, а выводится) с пространством изображений, и мы задаем входное и выходное измерения соответствующим образом. tanh приводит вывод последнего слоя к значениям в диапазоне [-1:1], то есть в том же диапазоне, к которому были приведены обучающие данные.
generator = Chain(Dense(latent_dim, 256, x -> leakyrelu(x, 0.2f0)),
Dense(256, 512, x -> leakyrelu(x, 0.2f0)),
Dense(512, 1024, x -> leakyrelu(x, 0.2f0)),
Dense(1024, n_features, tanh)) |> gpuОбучающие функции для сетей
Для обучения дискриминатора ему предоставляются реальные данные из набора данных MNIST и искусственные данные, на основе которых он пытается спрогнозировать правильные метки для каждого образца. Разумеется, правильными метками являются 1 для данных в пределах распределения и 0 для данных вне распределения, поступивших от генератора. В качестве функции потерь выбрана бинарная перекрестная энтропия. Хотя в документации Flux предлагается использовать бинарную перекрестную энтропию на основе логистической регрессии, обучение GAN с этой функцией потерь представляет сложность. Эта функция возвращает потери дискриминатора в целях регистрации. Потери можно вычислить в том же вызове, в котором вычисляется откат, а откат можно получать непосредственно из Zygote вместо вызова Flux.train! для модели. В таком случае для вычисления градиентов функции потерь с учетом параметров дискриминатора достаточно вычислить откат с начальным градиентом 1,0. Эти градиенты используются для обновления параметров модели
function train_dscr!(discriminator, real_data, fake_data)
this_batch = size(real_data)[end] # Количество образцов в пакете
# Объединяем реальные и искусственные данные в один большой вектор
all_data = hcat(real_data, fake_data)
# Целевой вектор для прогнозов: 1 для реальных данных, 0 для искусственных данных.
all_target = [ones(eltype(real_data), 1, this_batch) zeros(eltype(fake_data), 1, this_batch)] |> gpu;
ps = Flux.params(discriminator)
loss, pullback = Zygote.pullback(ps) do
preds = discriminator(all_data)
loss = Flux.Losses.binarycrossentropy(preds, all_target)
end
# Для получения градиентов мы вычисляем откат с начальным градиентом 1,0.
grads = pullback(1f0)
# Обновляем параметры дискриминатора, используя вычисленные выше градиенты.
Flux.update!(opt_dscr, Flux.params(discriminator), grads)
return loss
endТеперь нужно определить функцию для обучения сети генератора. Задача генератора состоит в том, чтобы обмануть дискриминатор, поэтому генератор получает одобрение, когда дискриминатор с высокой вероятностью определяет образец как подлинный. В функции обучения необходимо сначала произвести выборку шума, то есть данных с нормальным распределением. Это необходимо сделать за пределами отката, так как градиенты необходимо получить не относительно шума, а относительно параметров генератора. Внутри отката необходимо сначала применить генератор к шуму, так как градиент будет браться с учетом параметров генератора. Кроме того, необходимо вызвать дискриминатор, чтобы вычислить функцию потерь внутри отката. При этом следует не забыть отключить слои предотвращения переобучения дискриминатора. Для этого дискриминатор переводится в режим проверки перед откатом. Сразу после отката он возвращается в режим обучения. Затем мы вычисляем откат, как и ранее, вызываем его с начальным градиентом 1,0, обновляем параметры сети генератора и возвращаем потери.
function train_gen!(discriminator, generator)
# Выборка шума
noise = randn(latent_dim, batch_size) |> gpu;
# Определяем параметры и получаем откат
ps = Flux.params(generator)
# Переводим дискриминатор в режим проверки, чтобы отключить слои предотвращения переобучения
testmode!(discriminator)
# Вычисляем функцию потерь при вычислении отката. Получаем потери без затрат
loss, back = Zygote.pullback(ps) do
preds = discriminator(generator(noise));
loss = Flux.Losses.binarycrossentropy(preds, 1.)
end
# Вычисляем откат с начальным градиентом 1,0, чтобы получить градиенты для
# параметров генератора
grads = back(1.0f0)
Flux.update!(opt_gen, Flux.params(generator), grads)
# Возвращаем дискриминатор в автоматический режим
trainmode!(discriminator, mode=:auto)
return loss
endОбучение
Теперь мы готовы обучить сеть GAN. В цикле обучения мы отслеживаем потери генератора и дискриминатора на уровне образца, используя пакетные потери, возвращаемые двумя определенными выше функциями обучения. В рамках каждой эпохи мы производим итерацию по мини-пакетам, предоставленным загрузчиком данных. Перед вызовом функций обучения требуется минимальная обработка данных.
lossvec_gen = zeros(num_epochs)
lossvec_dscr = zeros(num_epochs)
for n in 1:num_epochs
loss_sum_gen = 0.0f0
loss_sum_dscr = 0.0f0
for x in train_loader
# - Изображения преобразуются из формы 28 x 28 x размер_пакета в более плоскую форму 784 x размер_пакета
real_data = flatten(x);
# Обучаем дискриминатор
noise = randn(latent_dim, size(x)[end]) |> gpu
fake_data = generator(noise)
loss_dscr = train_dscr!(discriminator, real_data, fake_data)
loss_sum_dscr += loss_dscr
# Обучаем генератор
loss_gen = train_gen!(discriminator, generator)
loss_sum_gen += loss_gen
end
# Добавляем потери генератора и дискриминатора на уровне образца
lossvec_gen[n] = loss_sum_gen / size(train_x)[end]
lossvec_dscr[n] = loss_sum_dscr / size(train_x)[end]
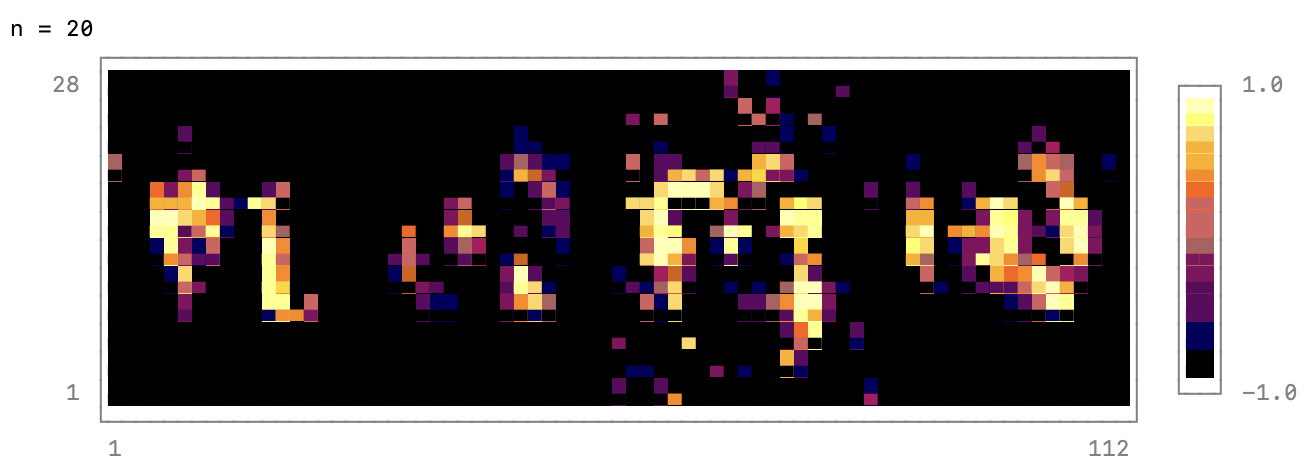
if n % output_period == 0
@show n
noise = randn(latent_dim, 4) |> gpu;
fake_data = reshape(generator(noise), 28, 4*28);
p = heatmap(fake_data, colormap=:inferno)
print(p)
end
endПри гиперпараметрах, приведенных в этом примере, генератор выдает полезные изображения примерно после 1000 эпох. А после 5000 эпох результат внешне неотличим от реальных данных MNIST. При использовании GPU Nvidia V100 и ЦП Power9 2,7 ГГц с 32 аппаратными потоками 100 эпох обучения занимают примерно 80 секунд. Степень использования GPU составляет 30—40 %. Чтобы чаще проверять состояние сети во время обучения, можно задать, например, значение output_period=20. Обучать GAN с использованием ЦП не рекомендуется, так как каждая эпоха при этом занимает примерно 10 минут.
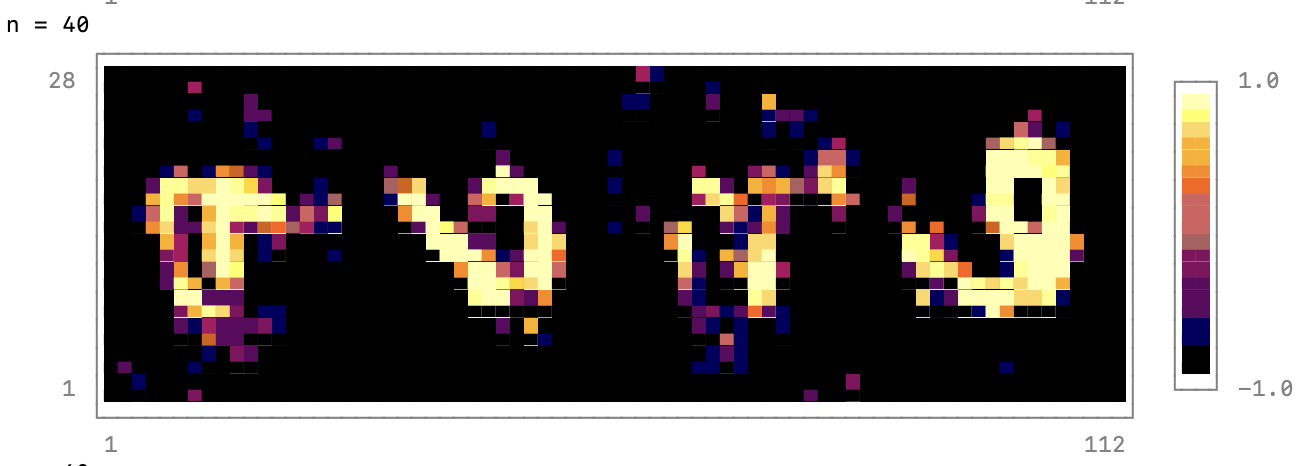
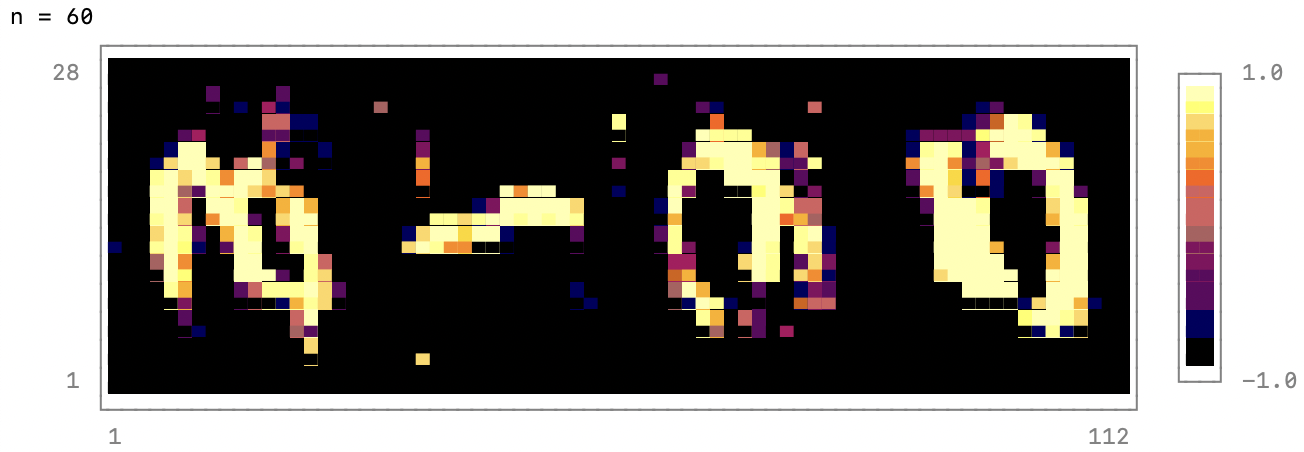

Ресурсы
|
Впервые опубликовано на сайте fluxml.ai 14 октября 2021 г. автором Ральфом Кубе (Ralph Kube). |