Разработка и реализация JIT
В этом документе приводятся сведения о разработке и реализации JIT Julia после завершения генерации кода и создания неоптимизированного представления IR LLVM. JIT отвечает за оптимизацию и компиляцию этого IR в машинный код, а также за его компоновку в текущий процесс и предоставление доступа к коду для выполнения.
Введение
JIT осуществляет управление ресурсами компиляции, поиск ранее скомпилированного кода и компиляцию нового кода. В основном он построен на технологии компиляции по запросу (ORCv2) в LLVM, которая реализует поддержку ряда полезных функций, таких как параллельная компиляция, отложенная компиляция и возможность компиляции кода в отдельном процессе. Хотя LLVM предоставляет базовый JIT-компилятор в виде LLJIT, для создания собственного JIT-компилятора в Julia напрямую используются многие API ORCv2.
Обзор
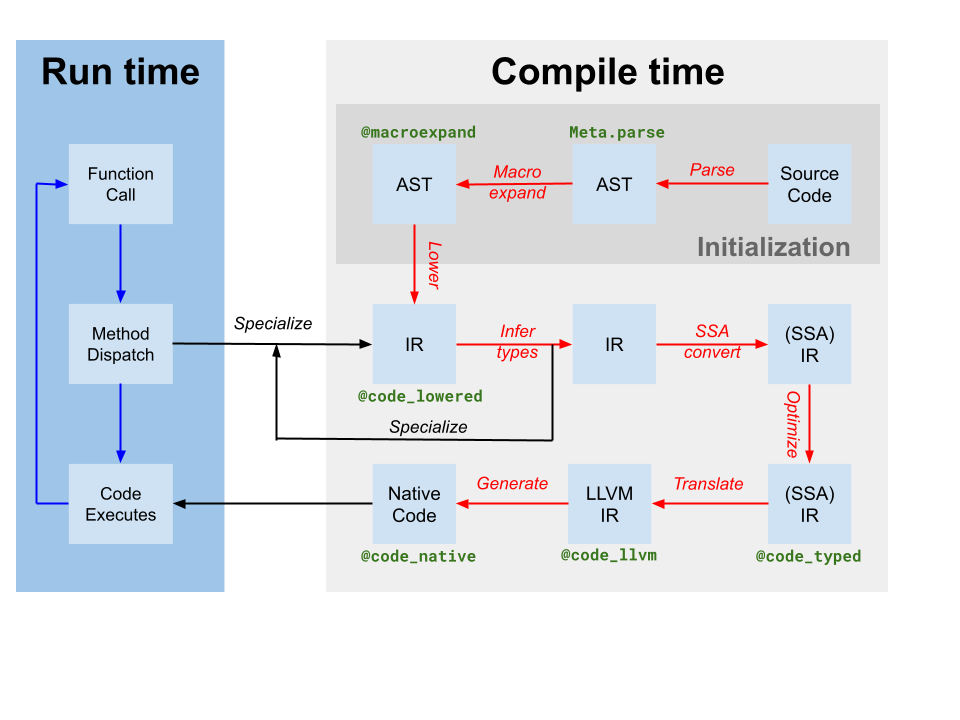
При генерации кода создается модуль LLVM, содержащий IR для одной или нескольких функций Julia, из исходного IR SSA Julia, полученного в результате вывода типов (помечен как translate (преобразование) на диаграмме компилятора выше). Также производится сопоставление экземпляра кода с именем функции LLVM. Однако, несмотря на то, что компилятор на основе Julia применил некоторые оптимизации к IR Julia, представление IR LLVM, полученное при генерации кода, все еще содержит много возможностей для оптимизации. Таким образом, первым шагом JIT является запуск независимого от целевого объекта конвейера оптимизации[1] в модуле LLVM. Затем JIT запускает зависящий от цели конвейер оптимизации для оптимизации и генерации кода и выводит файл объекта. Наконец, JIT компонует полученный файл объекта в текущий процесс и делает код доступным для выполнения. Все эти действия контролируются кодом в файле src/jitlayers.cpp.
В настоящее время в конвейер оптимизации-компиляции-компоновки одновременно может попасть только один поток. Это связано с ограничениями, налагаемыми одним из наших компоновщиков (RuntimeDyld). Однако JIT разработан для поддержки одновременной оптимизации и компиляции, и ожидается, что в будущем, когда RuntimeDyld будет полностью заменен на всех платформах, ограничение компоновщика будет снято.
Конвейер оптимизации
Конвейер оптимизации основан на новом диспетчере проходов LLVM, но адаптирован под нужды Julia. Конвейер определен в src/pipeline.cpp и в целом проходит несколько этапов, которые подробно описаны ниже.
-
Упрощение на ранних этапах
-
Эти проходы в основном используются для упрощения IR и канонизации шаблонов, чтобы последующие проходы могли легче идентифицировать эти шаблоны. Кроме того, различные внутренние вызовы, такие как подсказки для предсказания ветвей и аннотации, понижаются до других метаданных или других функций IR. Ключевую роль здесь играют
SimplifyCFG(упрощение графика порядка управления),DCE(исключение нерабочего кода) иSROA(скалярная замена агрегатов). -
Оптимизация на ранних этапах
-
Эти проходы обычно дешевы и в основном направлены на уменьшение количества инструкций в IR и распространение знаний в другие инструкции. Например,
EarlyCSEиспользуется для устранения общих подвыражений, аInstCombineиInstSimplifyвыполняют ряд небольших локальных оптимизаций для удешевления операций. -
Оптимизация циклов
-
Эти проходы канонизируют и упрощают циклы. Циклы часто являются «горячим» кодом, что делает оптимизацию циклов чрезвычайно важной для производительности. Ключевую роль здесь играют
LoopRotate,LICMиLoopFullUnroll. В результате проходаIRCEтакже происходит устранение части проверки границ, которое подтверждает, что определенные границы никогда не превышаются. -
Скалярная оптимизация
-
Конвейер скалярной оптимизации содержит ряд более дорогих, но более мощных проходов, таких как
GVN(нумерация глобальных значений),SCCP(распространение разреженных условных констант) и еще один цикл устранения проверки границ. Эти проходы стоят дорого, но зачастую они позволяют удалить большое количество кода и сделать векторизацию гораздо более успешной и эффективной. Несколько других проходов упрощений и оптимизаций чередуются с более дорогими, чтобы сократить объем работы, которую им приходится выполнять. -
Векторизация
-
Автоматическая векторизация — это чрезвычайно мощное преобразование для кода, требующего интенсивной загрузки ЦП. Если коротко, векторизация позволяет выполнять одну инструкцию с множеством данных (SIMD), например выполнять 8 операций сложения одновременно. Однако доказать, что код одновременно поддерживает векторизацию и выгоден для векторизации, довольно сложно, и это в значительной степени зависит от предварительных проходов оптимизации для перевода IR в состояние, в котором векторизация будет оправдана.
-
Понижение внутренних функций
-
Julia вставляет ряд пользовательских собственных внутренних функций для таких целей, как распределение объектов, сборка мусора и обработка исключений. Изначально эти внутренние функции были размещены для того, чтобы сделать возможности оптимизации более очевидными, но теперь они понижены в IR LLVM, чтобы IR можно было выдавать в виде машинного кода.
-
Очистка
-
Эти проходы являются оптимизациями последнего шанса и выполняют небольшие оптимизации, такие как распространение объединенного умножения-сложения и упрощение деления-нахождения остатка. Кроме того, для целевых объектов, не поддерживающих числа с плавающей запятой половинной точности, инструкции половинной точности будут понижены до инструкций одинарной точности, и будут добавлены проходы для поддержки санитайзеров.
Зависящая от целевого объекта оптимизация и генерация кода
LLVM обеспечивает зависящую от целевого объекта оптимизацию и генерацию машинного кода в одном конвейере, расположенном в TargetMachine для данной платформы. В число этих проходов входят выбор инструкций, планирование инструкций, выделение реестров и создание машинного кода. Хороший обзор этого процесса приводится в документации по LLVM, а более подробные сведения о конвейере и проходах можно найти в исходном коде LLVM.
Компоновка
В настоящее время Julia находится на этапе перехода со старого компоновщика RuntimeDyld на более новый JITLink. JITLink содержит ряд возможностей, которых нет у RuntimeDyld, например параллельную и повторно входимую компоновку, но сейчас у него нет достаточной поддержки интеграции профилирования и пока он не поддерживает все платформы, которые поддерживает RuntimeDyld. Ожидается, что со временем JITLink полностью заменит RuntimeDyld. Более подробные сведения о JITLink можно найти в документации по LLVM.
Выполнение
Код, скомпонованный в текущий процесс, становится доступным для выполнения. Генерирующий экземпляр кода узнает об этом в результате соответствующего обновления полей invoke, specsigflags и specptr. Экземпляры кода поддерживают обновление полей invoke, specsigflags и specptr при условии возможности вызова каждого их сочетания, существующего в любой момент времени. В этом случае JIT может обновлять эти поля, не аннулируя существующие экземпляры кода, поддерживая потенциально возможный в будущем параллельный JIT. В частности, могут быть действительны следующие состояния:
-
invokeимеет значение NULL,specsigflagsимеет значение 0b00,specptrимеет значение NULL -
Это начальное состояние экземпляра кода, которое указывает на то, что экземпляр кода еще не скомпилирован.
-
invokeимеет ненулевое значение,specsigflagsимеет значение 0b00,specptrимеет значение NULL -
Это указывает на то, что экземпляр кода не был скомпилирован с какой-либо специализацией и что его следует вызывать напрямую. Обратите внимание, что в данном случае
invokeне считывает ни полеspecsigflags, ни полеspecptr, поэтому их можно изменить, не аннулируя указательinvoke. -
invokeимеет ненулевое значение,specsigflagsимеет значение 0b10,specptrимеет ненулевое значение -
Это указывает на то, что экземпляр кода был скомпилирован, но специализированная сигнатура функции признана ненужной для генерации кода.
-
invokeимеет ненулевое значение,specsigflagsимеет значение 0b11,specptrимеет ненулевое значение -
Это указывает на то, что экземпляр кода был скомпилирован, и специализированная сигнатура функции признана необходимой для генерации кода. Поле
specptrсодержит указатель на специализированную сигнатуру функции. Указательinvokeможет считывать оба поляspecsigflagsиspecptr.
Кроме того, в процессе обновления возникает несколько различных переходных состояний. Чтобы учесть эти возможные ситуации, при работе с этими полями экземпляра кода следует использовать следующие шаблоны записи и чтения.
-
При записи в поля
invoke,specsigflagsиspecptr: -
Выполните атомарную операцию сравнения-обмена для поля specptr с предположением, что старое значение было равно NULL. Эта операция сравнения-обмена должна иметь, по крайней мере, упорядочение захвата-освобождения, чтобы гарантировать упорядочение оставшихся операций с памятью при записи.
-
Если
specptrне равен нулю, прекратите операцию записи и дождитесь записи бита 0b10specsigflags, затем при необходимости начните с шага 1. -
Запишите новый младший бит для поля
specsigflagsв качестве его конечного значения. Это может быть ослабленная операция записи. -
Запишите новый указатель для
invokeв качестве его конечного значения. Для синхронизации с операциями чтенияinvokeу него должно быть, по крайней мере, упорядочение освобождения памяти. -
Задайте второму биту
specsigflagsзначение 1. Для синхронизации с операциями чтенияspecsigflagsтребуется, по крайней мере, упорядочение освобождения памяти. Этот шаг завершает операцию записи и сообщает всем остальным потокам о том, что все поля были заданы. -
При чтении всех полей
invoke,specsigflagsиspecptr: -
Считать поле
specptrс любым порядком памяти. -
Прочитайте поле
invokeс минимальным порядком запоминания acquire. Эта загрузка будет называтьсяinitial_invoke. -
Если
initial_invokeравно NULL, код еще не готов к выполнению.invokeравно NULL,specsigflagsможет рассматриваться как 0b00,specptrможет рассматриваться как NULL. -
Если
specptrимеет значение NULL, то указательinitial_invokeне должен полагаться наspecptrдля правильного выполнения. Поэтомуinvokeимеет ненулевое значение,specsigflagsможет рассматриваться как имеющее значение 0b00,specptrможет рассматриваться как имеющее значение NULL. -
Если
specptrимеет ненулевое значение, тоinitial_invokeможет не быть конечным полемinvoke, использующимspecptr. Это может произойти, еслиspecptrуже записано, аinvoke— еще нет. Поэтому перебирайте второй бит поляspecsigflagsдо тех пор, пока не будет задано значение 1, по крайней мере, с упорядочением памяти захвата. -
Перечитайте поле
invokeс любым порядком памяти. Эта загрузка будет называтьсяfinal_invoke. -
Считайте поле
specsigflagsс любым упорядочением памяти. -
invokeявляетсяfinal_invoke,specsigflags— это значение, считанное на шаге 7,specptr— это значение, считанное на шаге 3. -
При обновлении
specptrдо другого, но аналогичного указателя функции: -
Выполните освобождение памяти нового указателя функции в
specptr. Гонки здесь должны неопасны, так как старый указатель функции должен быть все еще допустимым, так же как и любой новый. Указатель, записанный вspecptr, всегда должен быть доступен для вызова, независимо от того, будет ли он впоследствии перезаписан или нет.
Правильное считывание этих полей реализовано в jl_read_codeinst_invoke.
Несмотря на сложность, эти шаги записи, чтения и обновления гарантируют, что JIT может обновлять экземпляры кода без аннулирования существующих экземпляров и что JIT может обновлять экземпляры кода без аннулирования существующих указателей invoke. Это позволяет JIT в будущем повторно оптимизировать функции на более высоких уровнях оптимизации, а также поддерживать параллельную компиляцию функций.