数据近似
数据近似--应用 AnyMath*选择两组点(例如,*向量X*和*向量Y)之间的分析关系。 应用程序会自动查找所选模型的参数,在源数据之上构建曲线,并计算质量指标。 这对于节省时间是有效的:无需编程,您可以获得可视化图形和现成的函数表达式。
要打开应用程序,请转到 示例并交替单击*打开示例 AnyMath*→*开始 AnyMath*→*保存并打开*。 这将打开engee_curve_fitting_app。ngscript文件在 脚本编辑器 ![]() 在工作区中 AnyMath.
在工作区中 AnyMath.
要启动应用程序,请按照engee_curve_fitting_app中提供的说明进行操作。ngscript文件。 启动后,data approximation应用程序将在单独的浏览器选项卡中打开。:
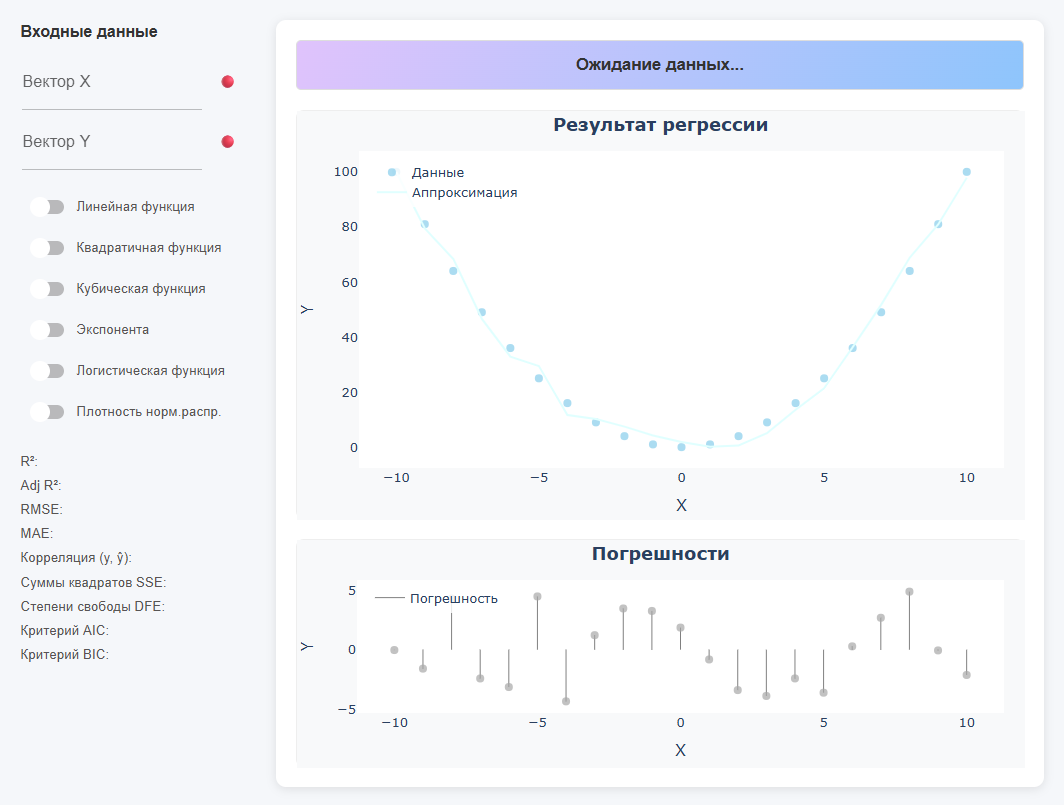
上面的彩色线显示了找到的函数的方程(如果没有数据,那么它写*"等待数据。.."). 左侧是用于输入输入数据和选择功能类型以及显示指标的面板。 中心有两个图形:*回归结果(点 + 曲线)和*误差*(残差)。
数据输入
应用程序从工作区读取数据 AnyMath(值应出现在 可变窗口 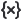 ). 在字段*Vector X*和*Vector Y*中,指定可用变量的名称。 状态指示器显示在字段旁边。:
). 在字段*Vector X*和*Vector Y*中,指定可用变量的名称。 状态指示器显示在字段旁边。:
*🔴--未找到向量; *🟡--只设置了一个向量,或者向量长度不匹配,模型计算还没有开始。; *🟢--向量已设置,模型已构建。
|
数据要求: *长度 |
这是处理输入数据的主要方式,但应用程序支持其他数据输入选项。:
*数组的直接赋值
+
X = [1, 2, 3, 4, 5]
Y = [2.1, 4.0, 5.9, 8.3, 10.2]+
*从DataFrame按列
+
using DataFrames
x = DataFrame(a = [1,2,3,4,5], b = [1,3,5,7,9])+ 结论:
+
5×2 DataFrame
Row │ a b
│ Int64 Int64
─────┼──────────────
1 │ 1 1
2 │ 2 3
3 │ 3 5
4 │ 4 7
5 │ 5 9+ 然后在应用程序中:
+
*作为表达式(对数组的操作)
+
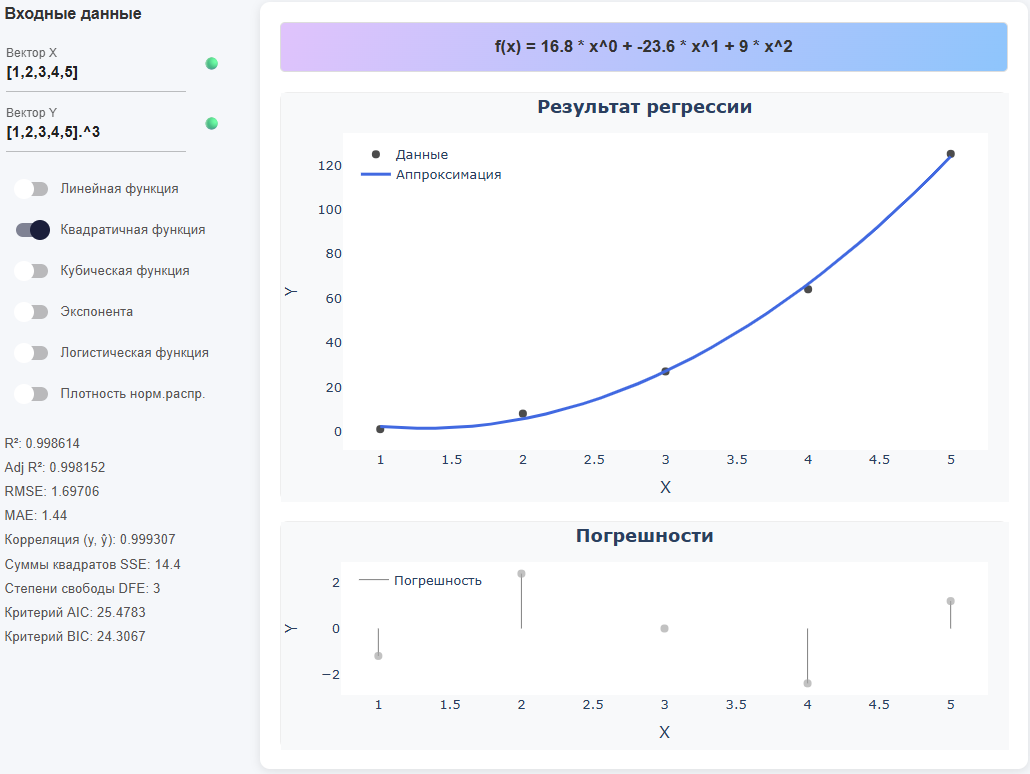
*变量和表达式的混合
+
X = [1,2,3,4,5]
Y = X .^ 3 # 零碎指数化(需要^之前的点)+
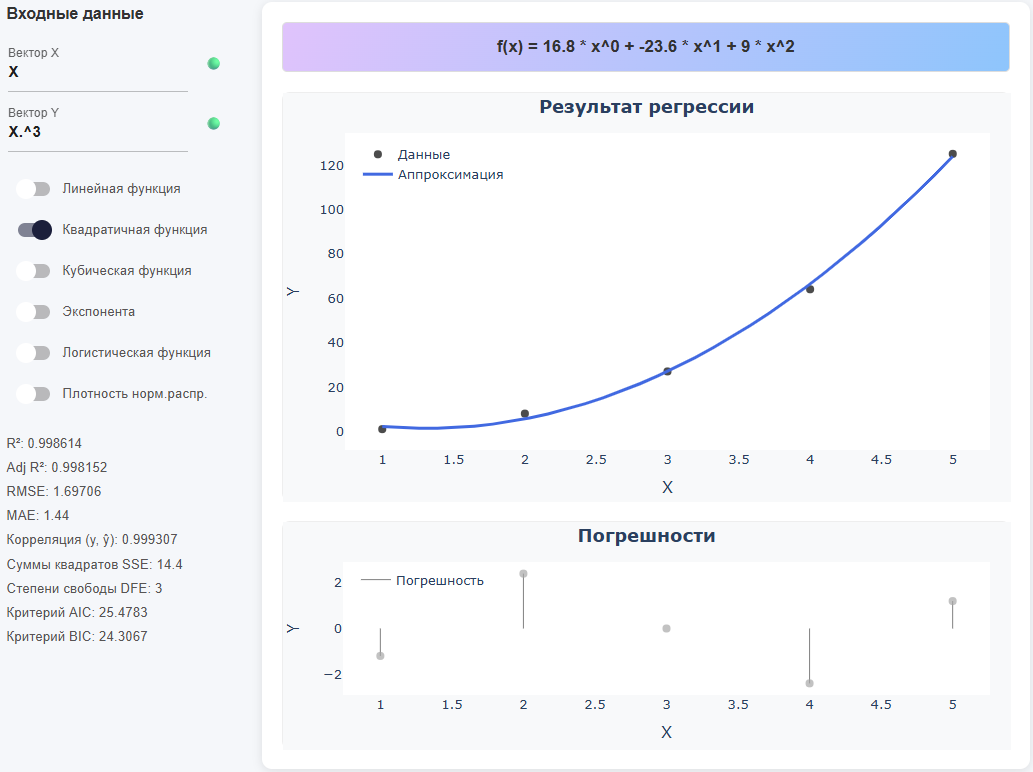
近似函数的选择
打开左侧面板中的一个开关。:
*线性函数-描述没有曲率的恒定幅度变化率;适用于近似直线趋势和快速"第一近似"。 方程: .
*二次函数-捕获一个"弧"(抛物线曲率),并允许您模拟单个极值(最小值/最大值)的存在。 方程: .
*三次函数-可以模拟拐点(曲率变化)和不对称轮廓;对于没有饱和的S形趋势有用。 方程: .
*指数-描述相对变化近似恒定时的成比例增长/下降;需要正值 Y,参数通过线性化选择 ln(y). 方程: .
*Logistic函数-具有饱和度的有限增长模型(S形曲线);适用于具有自然极限(下限和上限)的分数/概率和数量。 方程: .
*规范的密度。 分布-将高斯"钟"调整为对称峰值数据;当 Y 反映平均周围的密度/频率,并向边缘下降。 方程: .
| 对于多项式,选择由数据证明的顺序。 过度的复杂性会损害泛化能力。 通过*Adj R2*,*AIC*和*BIC*比较模型。 |
质量指标
每次近似后,都会计算度量(显示在函数列表下):

*R2(测定系数)-显示变异的分数 Y,由模型解释;位于0的范围内。.1(更接近1更好)。 重要提示:高R2并不能保证没有偏差和"好"残差。
Adj R2(调整后的R2)—R2版本,考虑到模型参数的数量;惩罚过度的复杂性,因此在比较不同的模型时更加诚实。 公式:
哪里 n -点数, p -特征的数量(没有常数)。
RMSE*是均方根误差的根(单位与 Y);方便作为错误的"典型尺度"。 公式: , .
MAE*是平均绝对误差;"以相同的单位"解释,对异常值的敏感度低于RMSE。 当"模平均"误差很重要时,它很有用。
相关性(y,ζ)*是实际之间的线性关系 y 和预测 ŷ (从 −1至1)。 高相关性意味着方向的一致性,但它不能保证小误差或模型的正确形状。
误差平方和(SSE) — ;许多方法的基本"成本"。 它取决于数据的规模,因此它本身不太适合比较不同的集合。
自由度(dfe)-通常 (点减去参数和一个常数);用于计算方差,置信度估计和Adj R2。
AIC标准*是一个信息标准:拟合质量和参数数量的平衡;只有模型在同一数据集上进行比较。 越少越好;不解释绝对值。
BIC标准*与AIC类似,但对复杂性有更严厉的惩罚(更倾向于更简单的模型)。 越少越好。
| 在选择模型时,将重点放在*Adj R2/AIC/BIC*结合余数图的分析:随机,"无结构"残基是足够模型的标志;系统模式是选择不同类型函数的原因。 |
使用图表
*回归结果-黑点(源数据)和蓝线(模型):
+
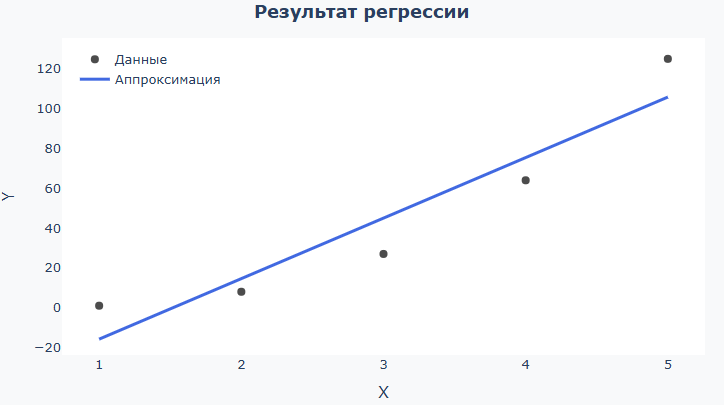
+
看到多少线符合你的期望,适合"沿云"的点在整个范围内。 如果数据简单且线条过于蜿蜒,则模型很可能过于复杂。 如果线几乎是直的,并且许多点离它太远,则模型太简单。 对于logistic函数,检查线是否平滑地"饱和"到边界。 对于正常密度,请检查"钟"在形状和宽度上与数据相似。 如果要从考虑中删除一定范围的数据(例如,沿着矢量边缘的点),请在输入字段中而不是 x_数据 和 y_数据 你可以进入 x_数据[10:结束-10] 和 y_数据[10:结束-10]. 这样,您将为除10个最外面的点(两侧)之外的所有点构建一个模型。
*错误-差异列 y − ŷ 用零线:
+

+ 一个好的迹象是残差的列在随机方向上位于0线周围,具有大致相同的偏差幅度,没有明显的模式。 如果正在查看"模式"(弧形,波浪)或条形偏移,则模型很可能形状不正确。 如果条形向边缘明显变高,则边界处的错误会增加(可能没有足够的数据或选择了错误的函数类型)。 单个非常高的柱线是异常值;应该单独检查或从向量中排除它们,以获得更干净的度量。
Plotly库的功能可以方便地使用图形。:

-
 -下载图为PNG;
-下载图为PNG; -
 -选择一个区域并放大其内容的能力;
-选择一个区域并放大其内容的能力; -
 -用于在坐标平面上移动图形的工具;
-用于在坐标平面上移动图形的工具; -
 -在坐标平面上放大;
-在坐标平面上放大; -
 -减少坐标平面的比例;
-减少坐标平面的比例; -
 -返回坐标平面的默认比例;
-返回坐标平面的默认比例; -
 -重置坐标轴。
-重置坐标轴。
在命令行上检查结果 AnyMath
-
从应用程序的顶行复制模型方程。 例如:
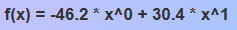
-
将表达式插入 命令提示符
 并建立一个图表:
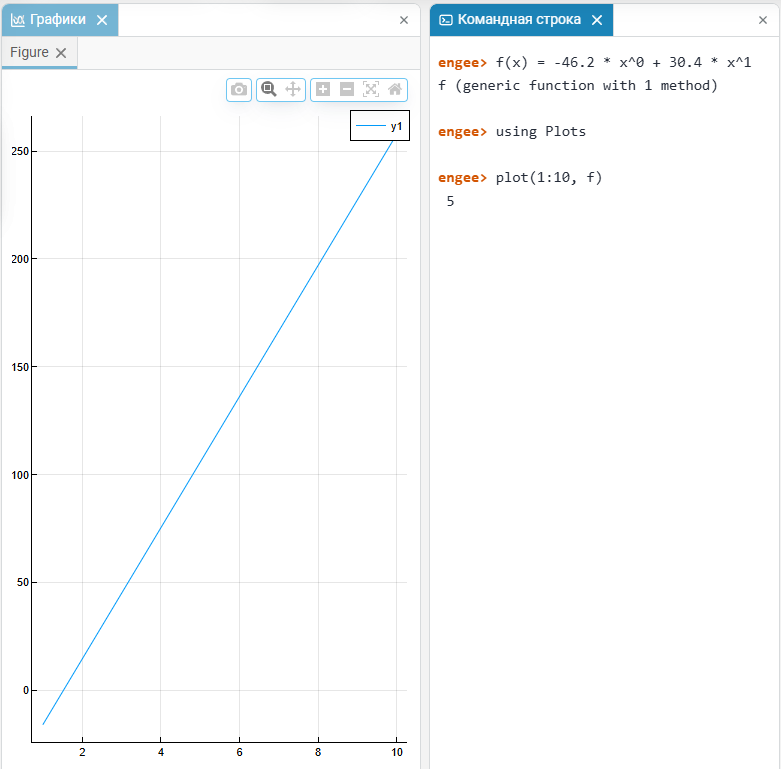
并建立一个图表:# 示例:从应用程序中插入表达式 f(x) = -46.2 * x^0 + 30.4 * x^1 # 在区间1上绘制f的值。.10 plot(1:10, f) -
图表将在图表窗口中绘制。 AnyMath:
如果方程涉及向量上的零碎操作,则使用带点的语法。: .^, .*, ./.
|