2-D Обнаружение с ПУЛТ
Блок CFAR-алгоритма детектирования приемника для двумерных сигналов.
Тип: CFARDetector2D
|
Путь в библиотеке: |

Описание
Блок 2-D Обнаружение с ПУЛТ реализует детектор с поддержанием постоянной величины вероятности ложной тревоги для двумерных сигналов. Обнаружение происходит, когда значение ячейки сигнала превышает пороговое значение. Для поддержания постоянной вероятности ложной тревоги порог устанавливается кратным мощности шума изображения. Детектор оценивает мощность шума от соседних ячеек, окружающих тестируемую ячейку (CUT), используя один из трех методов усреднения по ячейкам или метод статистики порядка (OS).
Методами усреднения по ячейкам являются:
-
Усреднение по ячейке (CA).
-
Усреднение по наибольшей ячейке (GOCA).
-
Усреднение по наименьшей ячейке (SOCA).
Для каждой тестовой ячейки детектор:
-
Оценивает статистику шума по значениям ячеек в полосе обучения, окружающей тестируемую ячейку.
-
Вычисляет порог, умножая оценку шума на пороговый коэффициент.
-
Сравнивает значение тестируемой ячейки с пороговым значением, чтобы определить наличие или отсутствие цели. Если значение больше порога, то цель присутствует.
Порты
Вход
X — входной сигнал
вещественная матрица M на N | вещественный массив M на N на P
Входной сигнал задается в виде вещественной матрицы размера M на N или вещественного массива размера M на N на P. M и N представляют собой строки и столбцы матрицы.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
idx — вектор индексов проверяемых ячеек
матрица целых положительных чисел 2 на L
Расположение тестовых ячеек, заданное в виде матрицы целых положительных чисел размером 2 на L, где L — количество тестовых ячеек. Каждый столбец idx задает индекс строки и столбца тестовой ячейки. Расположение тестовых ячеек ограничено таким образом, чтобы их обучающие области полностью лежали в пределах входного сигнала.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
K — пороговый коэффициент обнаружения
положительный скаляр
Пороговый коэффициент, используемый для расчета порога обнаружения, задается виде положительной скалярной величины.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
Выход
Y — выход обнаружителя
логическая матрица (по умолчанию) | вещественная матрица
Формат данных на выходе обнаружителя зависит от свойства Output Format:
-
Если для параметра Output Format установлено значение
Cut result, то Y представляет собой матрицу D на P, содержащую логические результаты обнаружения тестируемых ячеек. D — длинаcutidx, а P — величина третьей размерности X. Строки Y соответствуют строкамcutidx. Для каждой строки Y содержит логическую1в столбце, если в соответствующей ячейке X есть обнаружение. В ином случае Y содержит логическую0. -
Если для параметра Output Format установлено значение
Detection index, то Y — это матрица K на L, содержащая индексы обнаружений. K — число размерностей X. L — число обнаружений, найденных во входных данных. Если X — матрица, то Y содержит индексы строк и столбцов каждого обнаружения в X в виде[detrow;detcol]. Если X — массив, то Y содержит индексы строк, столбцов и страниц каждого обнаружения в X в виде[detrow;detcol;detpage]. Если для параметра Source of the number of detections установлено значениеProperty, то L равно значению параметра Maximum number of detections. Если количество фактических обнаружений меньше этого значения, то столбцы без обнаружений устанавливаются вNaN.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
Th — вычисленный порог обнаружения
вещественная матрица
Вычисленный порог обнаружения для каждой обнаруженной ячейки, возвращаемый в виде вещественной матрицы. Данные на порту Th имеют ту же размерность, что и Y.
-
Если для параметра Output format установлено значение
Detection index, то Th возвращает порог обнаружения. -
Если для параметра Output format установлено значение
CUT result, то Th возвращает порог обнаружения для каждого соответствующего обнаружения в Y. Если для параметра Source of the number of detections установлено значениеProperty, то L равно значению параметра Maximum number of detections. Если количество фактических обнаружений меньше этого значения, то столбцы без обнаружений устанавливаются вNaN.
Зависимости
Чтобы использовать этот порт, установите флажок Output Detection Threshold.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
N — расчетная мощность шума
вещественная матрица
Оценка мощности шума для каждой обнаруженной ячейки, возвращаемая в виде вещественной матрицы.
-
Если для параметра Output format установлено значение
Detection index, то N возвращает мощность шума, если элемент Y равен1, иNaN, если элемент Y равен0. Если для параметра Source of the number of detections установлено значениеProperty, то L равно значению параметра Maximum number of detections. Если количество фактических обнаружений меньше этого значения, то столбцы без обнаружений устанавливаются вNaN. -
Если для параметра Output format установлено значение
CUT result, то N возвращает мощность шума для каждого соответствующего обнаружения в Y.
Зависимости
Чтобы использовать этот порт, установите флажок Output estimated noise power.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
Параметры
CFAR algorithm — алгоритм оценки мощности шума
CA (по умолчанию) | GOCA | SOCA | OS
Алгоритм оценки мощности шума, задаваемый как CA, GOCA, SOCA или OS. Для CA, GOCA, SOCA мощность шума представляет собой среднее значение ячеек в обучающей выборке.
Для OS мощность шума — это k-е значение ячейки, полученное в результате численного упорядочивания всех значений обучающих ячеек. Задайте k параметром Rank of order statisic.
-
CA— алгоритм усреднения по ячейкам. Вычисляет выборочное среднее значение всех обучающих ячеек, окружающих ячейку CUT. -
GOCA— алгоритм усреднения по ячейкам. Разделяет двумерное окно обучения, окружающее ячейку CUT, на левую и правую половины. Затем алгоритм вычисляет выборочное среднее для каждой половины и выбирает наибольшее среднее. -
SOCA— алгоритм усреднения по наименьшей ячейке. Разделяет двумерное окно обучения, окружающее ячейку CUT, на левую и правую половины. Затем алгоритм вычисляет среднее значение выборки для каждой половины и выбирает наименьшее среднее. -
OS— алгоритм статистики порядка. Сортирует обучающие ячейки в порядке возрастания числовых значений. Затем алгоритм выбирает k-е значение из списка. k — это ранг, задаваемый параметром Rank of order statistic.
Rank of order statistic — ранг порядковой статистики
1 (по умолчанию) | целое положительное число
Задайте ранг порядковой статистики, используемой в двухмерном алгоритме CFAR, в виде целого положительного числа. Значение этого параметра должно лежать в диапазоне от 1 до , где — количество обучающих ячеек. При значении 1 выбирается наименьшее значение в обучающей области.
Зависимости
Чтобы использовать этот параметр, установите для параметра CFAR Algorithm значение OS.
Size in cells of the guard region band — ширина защитной полосы
[1,1] (по умолчанию) | неотрицательный целый скаляр | 2-элементный вектор целых положительных чисел
Количество защитных ячеек в строке и столбце с каждой стороны тестируемой ячейки в виде неотрицательных целых чисел. Первый элемент задает размер защитной полосы по размеру строки. Второй элемент задает размер защитной области по размеру строки. Указание Size in cells of the guard region band в виде скаляра эквивалентно указанию вектора с одинаковым значением для обоих измерений. Например, значение [1 1] указывает на то, что вокруг каждой ячейки CUT находится область шириной в одну защитную ячейку.
Size in cells of the training region band — ширина обучающей области
[1,1] (по умолчанию) | неотрицательный целый скаляр | 2-элементный вектор целых положительных чисел
Размер в ячейках полосы обучающей области, задаваемый в виде целого неотрицательного числа или матрицы 1 на 2 из целых неотрицательных чисел. Первый элемент задает размер полосы обучения по строке, второй — по столбцу. Указание Size in cells of the training region band в виде скаляра эквивалентно указанию вектора с одинаковым значением для обоих измерений. Например, значение [1 1] означает, что для каждой тестируемой ячейки имеется область шириной в одну обучающую ячейку, окружающая защитную область.
Threshold factor method — метод определения порогового коэффициента
Auto (по умолчанию) | Input port | Custom
Метод определения порогового коэффициента, задается как Auto, Input port или Custom.
-
Auto— пороговый коэффициент определяется на основе оценочной статистики шума и вероятности ложной тревоги. -
Input port— пороговый коэффициент задается с помощью входного порта K. -
Custom— пороговый коэффициент задается с помощью параметра Custom threshold factor.
Custom threshold factor — настраиваемый пороговый коэффициент
1 (по умолчанию) | положительный скаляр
Настраиваемый пороговый коэффициент обнаружения, задаваемый в виде положительного скаляра.
Зависимости
Чтобы использовать этот параметр, установите для параметра Threshold factor method значение Custom.
Probability of false alarm — вероятность ложной тревоги
0.1 (по умолчанию) | вещественный скаляр в диапазоне от 0 до 1
Вероятность ложной тревоги, задаваемая в виде вещественного скаляра в диапазоне от 0 до 1. Пороговый коэффициент можно рассчитать из требуемой вероятности ложной тревоги.
Зависимости
Чтобы использовать этот параметр, установите для параметра Threshold factor method значение Auto.
Output format — формат результатов обнаружения
CUT result (по умолчанию) | Detection index
Формат результатов обнаружения, задается как CUT result или Detection index.
-
CUT result— результаты обнаружения представляют собой логические значения обнаружения (1или0) для каждой тестируемой ячейки. -
Detection index— результаты представляют собой вектор или матрицу, содержащую индексы тестируемых ячеек, превышающих порог обнаружения.
Output threshold detection — включение порогового выхода обнаружения
выключено (по умолчанию) | включено
Установите этот флажок, чтобы включить вывод пороговых значений обнаружения через выходной порт Th.
Output estimated noise power — включение порогового выхода обнаружения
выключено (по умолчанию) | включено
Установите этот флажок, чтобы включить вывод оценочной мощности шума через выходной порт N.
Source of the number of detections — источник числа обнаружений для отчета
Auto (по умолчанию) | Property
Источник числа обнаружений, задается как Auto или Property.
-
Auto— количество регистрируемых индексов обнаружения равно общему количеству тестируемых ячеек, в которых обнаружены индексы. -
Property— количество сообщаемых обнаружений определяется значением параметра Maximum number of detections.
Зависимости
Чтобы использовать этот параметр, установите для параметра Output format значение Detection index.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
Maximum number of detections — максимальное количество индексов обнаружений на выходе
1 (по умолчанию) | целое положительное число
Максимальное количество индексов обнаружений, которое необходимо получить на выходе, задается в виде целого положительного числа.
Зависимости
Чтобы использовать этот параметр, установите для параметра Output format значение Detection index и для параметра Source of the number of detections значение Property.
Типы данных: Float16, Float32, Float64, Int8, Int16, Int32, Int64, UInt8, UInt16, UInt32, UInt64, Bool
Алгоритмы
2-D CFAR алгоритм требует оценки мощности шума. Мощность шума вычисляется по ячейкам, которые, как предполагается, не содержат целевого сигнала. Эти ячейки являются обучающими. Обучающие ячейки образуют полосу вокруг тестируемой ячейки (CUT), но могут быть отделены от CUT защитной полосой. Порог обнаружения рассчитывается путем умножения мощности шума на пороговый коэффициент.
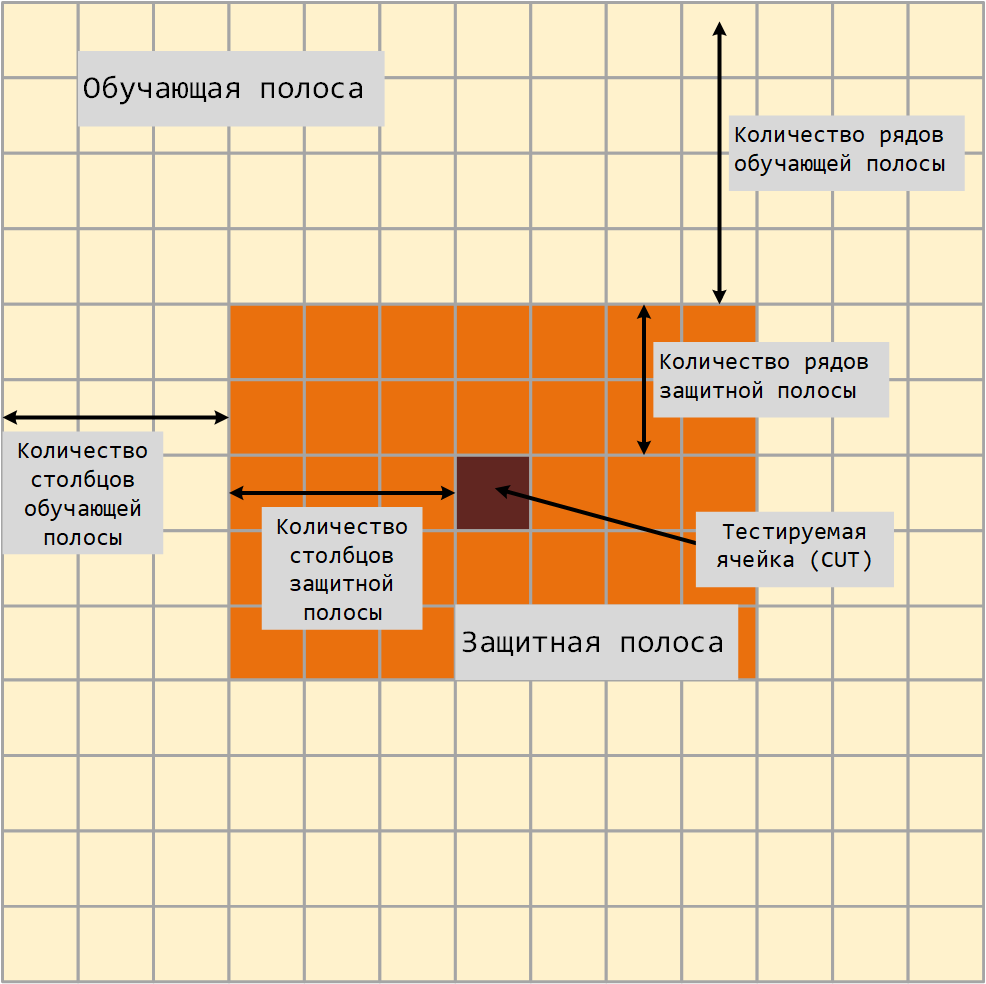
Для усреднения GOCA и SOCA мощность шума определяется как среднее значение одной из левой или правой половин области обучающих ячеек.
Поскольку число столбцов в обучающей области нечетное, то ячейки среднего столбца в равной степени относятся либо к левой, либо к правой половине.
При использовании порядково-статистического метода ранг не может быть больше, чем количество ячеек в области обучающих ячеек . Вы можете рассчитать .
-
— количество столбцов обучающей полосы.
-
— количество рядов обучающей полосы.
-
— количество столбцов защитной полосы.
-
— количество рядов защитной полосы.
Общее количество ячеек в комбинированной обучающей области, защитной области и ячейке CUT составляет:
.
Общее количество ячеек в комбинированной защитной области и ячейке CUT составляет
.
Количество обучающих ячеек составляет .
По конструкции число обучающих ячеек всегда четное. Поэтому для реализации медианного фильтра можно выбрать ранг или .