二维 CFAR 探测器
二维信号的CFAR接收机检测算法的块。
模块类型: CFARDetector2D
|
库中的路径: |

资料描述
座 二维 CFAR 探测器 实现对二维信号具有恒定虚警概率值的检测器。 当信号单元的值超过阈值时发生检测。 为了保持虚警的恒定概率,阈值被设置为图像噪声功率的倍数。 检测器使用三种小区平均方法之一或阶数统计(OS)方法评估来自被测小区(CUT)周围的相邻小区的噪声功率。
小区平均的方法有:
-
小区平均(CA)。
-
在最大的细胞(GOCA)上平均。
-
最小单元平均(SOCA)。
对于每个测试单元,检测器:
-
基于围绕测试小区的训练频带中的小区值评估噪声统计。
-
通过将噪声估计值乘以阈值因子来计算阈值。
-
将被测小区的值与阈值进行比较,以确定目标的存在或不存在。 如果该值大于阈值,则目标存在。
港口
入口
X-输入信号传递:q[<br>]'实数矩阵M by N'|'实数阵M by N by P`
输入信号被给定为大小为M乘N的实数矩阵或大小为M乘N乘P的实数阵列。M和N表示矩阵的行和列。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
idx 是被检查的传递单元的索引向量:q[<br>’正整数2乘L的矩阵`
测试单元的位置,定义为大小为2乘L的正整数矩阵,其中L是测试单元的数量。 每个 idx 列指定测试单元格的行和列索引。 测试单元的位置受到限制,使其训练区域完全位于输入信号内。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
K 为通过检测的阈值系数:q[<br>]'正标量`
用于计算检测阈值的阈值系数被设置为正标量值。
数据类型'Float16,'Float32','Float64','Int8',Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,`Bool'
出口;出口
Y-通过检测器输出:q[<br>]逻辑矩阵(默认)|/'实矩阵
从检测器输出的数据的格式取决于*Output Format属性。*:
-
如果*Output Format*参数设置为’Cut result',则*Y*是一个包含检测待测细胞的逻辑结果的d-by-P矩阵。 D是’cutidx’的长度,P是第三维*X*的值。 *Y*线对应于’cutidx’线。 对于每一行,*Y*在列中包含一个逻辑`1',如果在相应的单元格*X*中存在检测。 否则,*Y*包含逻辑'0'。
-
如果* 输出格式*参数设置为"检测索引`,则*Y*是包含检测索引的K乘l矩阵。 K是维数*X*。 L是在输入数据中找到的检测次数。 如果*X*是矩阵,则*Y*以`[detrow;detcol]
的形式包含*X*中每个检测的行和列索引。 如果*X*是一个数组,则*Y*以[detrow;detcol;detpage]的形式包含*X*中每个检测的行,列和页的索引。 如果检测次数*参数的*源设置为’属性,则L等于*最大检测次数*参数的值。 如果实际检测的数量小于此值,则没有检测的列将设置为"NaN"。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
Th-通过检测的计算阈值:q[<br>]'实矩阵`
计算出的每个检测小区的检测阈值,作为实矩阵返回。 Th 端口上的数据具有与 Y 相同的维度。
-
如果*Output format*参数设置为`Detection index',则*Th*返回检测阈值。
-
如果*Output format*参数设置为’CUT result',则*Th*返回*Y*中每个相应检测的检测阈值。 如果检测次数*参数的*源设置为’属性`,则L等于*最大检测次数*参数的值。 如果实际检测的数量小于此值,则没有检测的列将设置为"NaN"。
依赖关系
要使用此端口,请选中 输出检测阈值 复选框。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
N—估计通噪声功率:q[<br>]实矩阵
每个检测到的小区的噪声功率的估计,作为实矩阵返回。
-
如果*Output format*参数设置为`Detection index',则如果*Y*元素为`1`,则*N*返回噪声功率,如果*Y*元素为`0`,则返回`NaN`。 如果检测次数*参数的*源设置为’属性`,则L等于*最大检测次数*参数的值。 如果实际检测的数量小于此值,则没有检测的列将设置为"NaN"。
-
如果*Output format*参数设置为’CUT result',则*N*返回*Y*中每个相应检测的噪声功率。
依赖关系
要使用此端口请选中 输出估计噪声功率 复选框。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
参数
CFAR算法-通过噪声功率估计算法:q[<br>]'CA(default)|'GOCA|’SOCA|’OS
噪声功率估计算法,指定为’CA`、GOCA、SOCA’或’OS'。 对于’CA、'GOCA'、'SOCA`,噪声功率为训练样本中像元的平均值。
对于’OS`,噪声功率是信元的第k个值,作为训练信元的所有值的数值排序的结果获得。 用 秩统计 参数设置k。
-
'CA’是逐个小区平均算法。 计算切割细胞周围的所有训练细胞的样本平均值。
-
GOCA是一种逐小区平均算法。 将围绕被切割细胞的二维学习窗口分成左半和右半。 然后,该算法计算每半的样本平均值并选择最大的平均值。
-
SOCA是一种在最小单元上进行平均的算法。 将围绕被切割细胞的二维学习窗口分成左半和右半。 然后,算法计算每半的样本平均值并选择最小的平均值。
-
'OS’是一种用于订单统计的算法。 按照数值的升序对训练单元格进行排序。 然后算法从列表中选择第k个值。 k是由*rank of order statistical*参数设置的秩。
顺序统计的秩-顺序统计的秩通过:q[<br>]1(默认)|/'正整数
将二维CFAR算法中使用的序数统计量的秩设置为正整数。 此参数的值必须在从`1’到 ,在哪里 -训练细胞的数量。 值'1`,选择训练区域中最小的值。
依赖关系
要使用此参数,请将 CFAR算法 参数设置为’OS'。
保护区带的单元格中的大小—保护通带的宽度:q[<br>]'[1,1](默认)|/'非负整数标量|``正整数的2元素向量'
在被测单元的每一侧的行和列中的安全单元的数量,以非负整数的形式。 第一元素根据字符串的大小设置保护条的大小。 第二个元素根据字符串的大小设置安全区域的大小。 将保护区域band*的单元格中的*Size指定为标量相当于为两个维度指定具有相同值的向量。 例如,值'[1 1]'指示在每个切割单元周围有一个宽为一个安全单元的区域。
训练区域的单元格中的大小band-训练区域的宽度
'[1,1](default)|/'非负整数标量|``正整数的2元素向量'
训练区域的条带的像元中的大小,设为非负整数或非负整数的1乘2矩阵。 第一个元素按行设置学习带的大小,第二个按列设置学习带的大小。 将训练区域band*的像元中的*Size指定为标量等效于为两个维度指定具有相同值的向量。 例如,值'[1 1]'表示对于每个测试小区有一个宽度为一个训练小区的区域包围保护区。
阈值系数方法-确定通过阈值系数的方法:q[<br>]'Auto(default)|’Input port|``Custom'
阈值系数的确定方法设置为’Auto'、'Input port’或’Custom'。
-
"自动"-阈值系数是根据估计的噪声统计和虚警概率确定的。
-
'输入端口'-使用输入端口K设置阈值系数。
-
"自定义"-使用* 自定义阈值因子*参数设置阈值因子。
自定义阈值因子-可配置的阈值通过因子:q[<br>]'1(默认)|/'正标量`
可配置的阈值检测系数,设置为正标量。
依赖关系
要使用此参数,请将 Threshold factor method 参数设置为’Custom'。
虚警概率-虚警通过概率:q[<br>]'0.1(默认值)|'0到1范围内的真实标量
虚警的概率,设置为从`0`到`1’范围内的真实标量。 阈值系数可由所需的虚警概率计算。
依赖关系
要使用此参数,请将 Threshold factor method 参数设置为’Auto'。
输出格式-检测结果的格式为
'剪切结果(默认)|'检测索引
检测结果的格式设置为’剪切结果’或’检测索引'。
-
"剪切结果"-检测结果表示每个测试单元的逻辑检测值("1"或"0")。
-
"检测指数—-结果是一个向量或矩阵,其中包含超过检测阈值的被测试细胞的指数。
输出阈值检测-启用阈值检测输出通道q[<br>]disabled(默认情况下)|/'enabled
选择此选项可启用通过 Th 输出端口输出检测阈值。
输出估计噪声功率-启用阈值检测输出通道q[<br>]disabled(默认情况下)|/'enabled
选择此选项可使能通过输出端口 N 输出估计的噪声功率。
检测次数的来源-通过报告的检测次数的来源:q[<br>]'Auto(default)|'Property
检测次数的来源设置为"Auto"或"Property"。
-
'Auto'-注册的检测索引的数量等于在其中检测索引的测试单元的总数。
-
"属性"-报告的检测次数由* 最大检测次数*参数的值决定。
依赖关系
要使用此参数,请将 输出格式 参数设置为"检测索引"。
数据类型'Float16,'Float32','Float64','Int8',Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,`Bool'
最大检测次数-pass输出处的最大检测索引数:q[<br>]'1(默认)|/'正整数`
必须在输出处获得的检测索引的最大数目被设置为正整数。
依赖关系
要使用此参数,请将 Output format 参数设置为`Detection index`,将 source of the number of detections 参数设置为`Property'。
数据类型:`Float16`,Float32,Float64,Int8,Int16,Int32,Int64,Uint8,UInt16,UInt32,UInt64,Bool
算法
2-D CFAR算法需要估计噪声功率。 噪声功率是从假定不包含目标信号的信元计算的。 这些细胞是训练细胞。 训练细胞在测试细胞周围形成条带(切割),但可通过保护条带与切割分开。 通过将噪声功率乘以阈值因子来计算检测阈值。
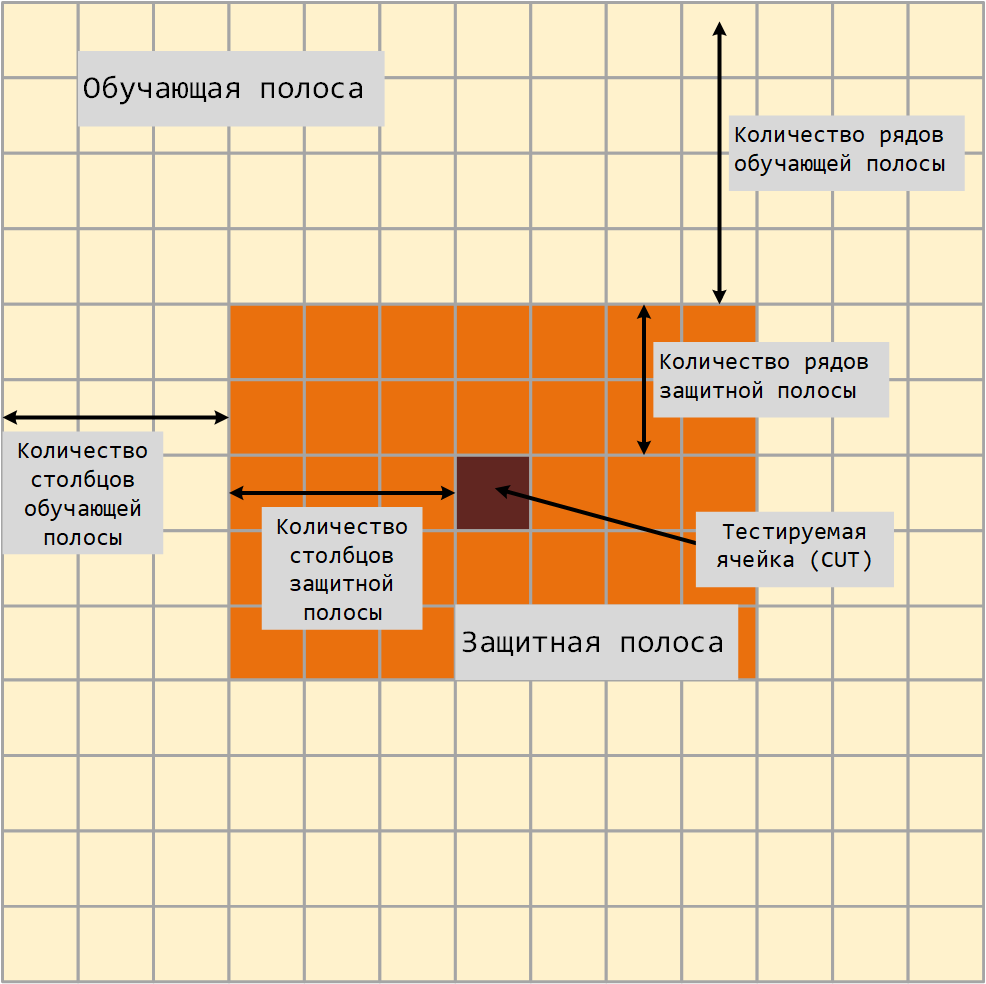
对于GOCA和SOCA平均,噪声功率被定义为训练小区区域的左半部分或右半部分之一的平均值。
由于训练区域中的列数为奇数,因此中间列中的单元格同样属于左半部分或右半部分。
使用序数统计方法时,秩不能大于训练小区区域的小区数。 . 你可以计算 .
-
-训练条的列数。
-
-训练条的行数。
-
-保护条的列数。
-
-保护条的行数。
合训练区域、保护区域和切割小区中的小区总数为:
.
合的保护区和被切割的细胞中的细胞总数为
.
训练小区的个数为 .
通过设计,训练细胞的数量总是均匀的。 因此,要实现中值滤波器,可以选择秩 或 .