JIT Design and Implementation
This document explains the design and implementation of Julia’s JIT, after codegen has finished and unoptimized LLVM IR has been produced. The JIT is responsible for optimizing and compiling this IR to machine code, and for linking it into the current process and making the code available for execution.
Introduction
The JIT is responsible for managing compilation resources, looking up previously compiled code, and compiling new code. It is primarily built on LLVM’s On-Request-Compilation (ORCv2) technology, which provides support for a number of useful features such as concurrent compilation, lazy compilation, and the ability to compile code in a separate process. Though LLVM provides a basic JIT compiler in the form of LLJIT, Julia uses many ORCv2 APIs directly to create its own custom JIT compiler.
Overview
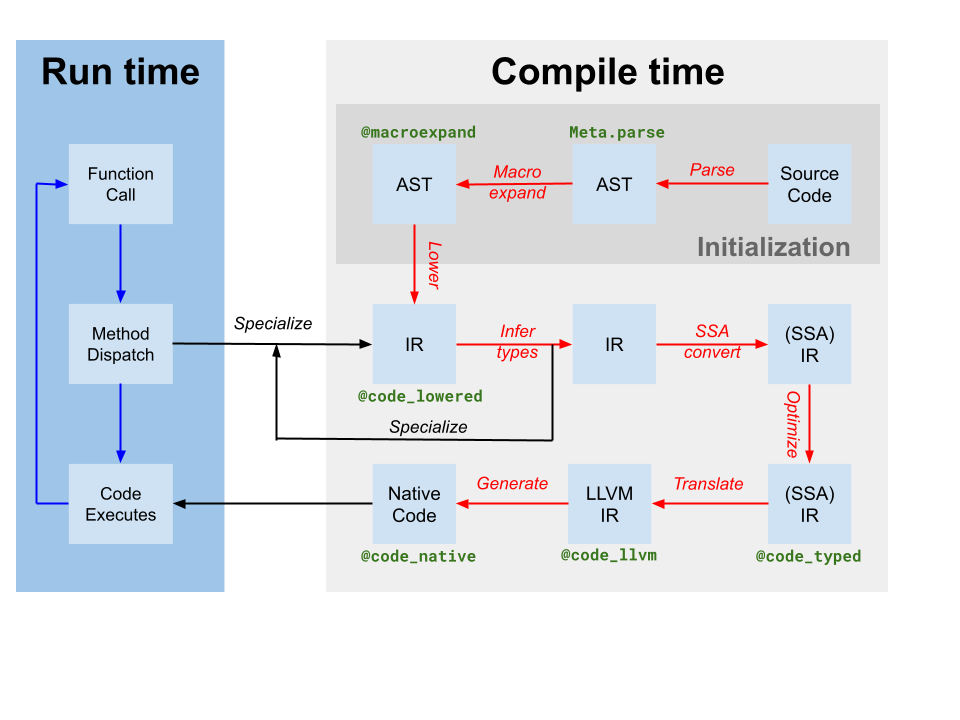
Codegen produces an LLVM module containing IR for one or more Julia functions from the original Julia SSA IR produced by type inference (labeled as translate on the compiler diagram above). It also produces a mapping of code-instance to LLVM function name. However, though some optimizations have been applied by the Julia-based compiler on Julia IR, the LLVM IR produced by codegen still contains many opportunities for optimization. Thus, the first step the JIT takes is to run a target-independent optimization pipeline[1] on the LLVM module. Then, the JIT runs a target-dependent optimization pipeline, which includes target-specific optimizations and code generation, and outputs an object file. Finally, the JIT links the resulting object file into the current process and makes the code available for execution. All of this is controlled by code in src/jitlayers.cpp.
Currently, only one thread at a time is permitted to enter the optimize-compile-link pipeline at a time, due to restrictions imposed by one of our linkers (RuntimeDyld). However, the JIT is designed to support concurrent optimization and compilation, and the linker restriction is expected to be lifted in the future when RuntimeDyld has been fully superseded on all platforms.
Optimization Pipeline
The optimization pipeline is based off LLVM’s new pass manager, but the pipeline is customized for Julia’s needs. The pipeline is defined in src/pipeline.cpp, and broadly proceeds through a number of stages as detailed below.
-
Early Simplification
-
These passes are mainly used to simplify the IR and canonicalize patterns so that later passes can identify those patterns more easily. Additionally, various intrinsic calls such as branch prediction hints and annotations are lowered into other metadata or other IR features.
SimplifyCFG(simplify control flow graph),DCE(dead code elimination), andSROA(scalar replacement of aggregates) are some of the key players here. -
Early Optimization
-
These passes are typically cheap and are primarily focused around reducing the number of instructions in the IR and propagating knowledge to other instructions. For example,
EarlyCSEis used to perform common subexpression elimination, andInstCombineandInstSimplifyperform a number of small peephole optimizations to make operations less expensive. -
Loop Optimization
-
These passes canonicalize and simplify loops. Loops are often hot code, which makes loop optimization extremely important for performance. Key players here include
LoopRotate,LICM, andLoopFullUnroll. Some bounds check elimination also happens here, as a result of theIRCEpass which can prove certain bounds are never exceeded. -
Scalar Optimization
-
The scalar optimization pipeline contains a number of more expensive, but more powerful passes such as
GVN(global value numbering),SCCP(sparse conditional constant propagation), and another round of bounds check elimination. These passes are expensive, but they can often remove large amounts of code and make vectorization much more successful and effective. Several other simplification and optimization passes intersperse the more expensive ones to reduce the amount of work they have to do. -
Vectorization
-
Automatic vectorization is an extremely powerful transformation for CPU-intensive code. Briefly, vectorization allows execution of a single instruction on multiple data (SIMD), e.g. performing 8 addition operations at the same time. However, proving code to be both capable of vectorization and profitable to vectorize is difficult, and this relies heavily on the prior optimization passes to massage the IR into a state where vectorization is worth it.
-
Intrinsic Lowering
-
Julia inserts a number of custom intrinsics, for reasons such as object allocation, garbage collection, and exception handling. These intrinsics were originally placed to make optimization opportunities more obvious, but they are now lowered into LLVM IR to enable the IR to be emitted as machine code.
-
Cleanup
-
These passes are last-chance optimizations, and perform small optimizations such as fused multiply-add propagation and division-remainder simplification. Additionally, targets that do not support half-precision floating point numbers will have their half-precision instructions lowered into single-precision instructions here, and passes are added to provide sanitizer support.
Target-Dependent Optimization and Code Generation
LLVM provides target-dependent optimization and machine code generation in the same pipeline, located in the TargetMachine for a given platform. These passes include instruction selection, instruction scheduling, register allocation, and machine code emission. The LLVM documentation provides a good overview of the process, and the LLVM source code is the best place to look for details on the pipeline and passes.
Linking
Currently, Julia is transitioning between two linkers: the older RuntimeDyld linker, and the newer JITLink linker. JITLink contains a number of features that RuntimeDyld does not have, such as concurrent and reentrant linking, but currently lacks good support for profiling integrations and does not yet support all of the platforms that RuntimeDyld supports. Over time, JITLink is expected to replace RuntimeDyld entirely. Further details on JITLink can be found in the LLVM documentation.
Execution
Once the code has been linked into the current process, it is available for execution. This fact is made known to the generating codeinst by updating the invoke, specsigflags, and specptr fields appropriately. Codeinsts support upgrading invoke, specsigflags, and specptr fields, so long as every combination of these fields that exists at any given point in time is valid to be called. This allows the JIT to update these fields without invalidating existing codeinsts, supporting a potential future concurrent JIT. Specifically, the following states may be valid:
-
invokeis NULL,specsigflagsis 0b00,specptris NULL -
This is the initial state of a codeinst, and indicates that the codeinst has not yet been compiled.
-
invokeis non-null,specsigflagsis 0b00,specptris NULL -
This indicates that the codeinst was not compiled with any specialization, and that the codeinst should be invoked directly. Note that in this instance,
invokedoes not read either thespecsigflagsorspecptrfields, and therefore they may be modified without invalidating theinvokepointer. -
invokeis non-null,specsigflagsis 0b10,specptris non-null -
This indicates that the codeinst was compiled, but a specialized function signature was deemed unnecessary by codegen.
-
invokeis non-null,specsigflagsis 0b11,specptris non-null -
This indicates that the codeinst was compiled, and a specialized function signature was deemed necessary by codegen. The
specptrfield contains a pointer to the specialized function signature. Theinvokepointer is permitted to read bothspecsigflagsandspecptrfields.
In addition, there are a number of different transitional states that occur during the update process. To account for these potential situations, the following write and read patterns should be used when dealing with these codeinst fields.
-
When writing
invoke,specsigflags, andspecptr: -
Perform an atomic compare-exchange operation of specptr assuming the old value was NULL. This compare-exchange operation should have at least acquire-release ordering, to provide ordering guarantees of the remaining memory operations in the write.
-
If
specptrwas non-null, cease the write operation and wait for bit 0b10 ofspecsigflagsto be written, then restart from step 1 if desired. -
Write the new low bit of
specsigflagsto its final value. This may be a relaxed write. -
Write the new
invokepointer to its final value. This must have at least a release memory ordering to synchronize with reads ofinvoke. -
Set the second bit of
specsigflagsto 1. This must be at least a release memory ordering to synchronize with reads ofspecsigflags. This step completes the write operation and announces to all other threads that all fields have been set. -
When reading all of
invoke,specsigflags, andspecptr: -
Read the
specptrfield with any memory ordering. -
Read the
invokefield with at least an acquire memory ordering. This load will be referred to asinitial_invoke. -
If
initial_invokeis NULL, the codeinst is not yet executable.invokeis NULL,specsigflagsmay be treated as 0b00,specptrmay be treated as NULL. -
If
specptris NULL, then theinitial_invokepointer must not be relying onspecptrto guarantee correct execution. Therefore,invokeis non-null,specsigflagsmay be treated as 0b00,specptrmay be treated as NULL. -
If
specptris non-null, theninitial_invokemight not be the finalinvokefield that usesspecptr. This can occur ifspecptrhas been written, butinvokehas not yet been written. Therefore, spin on the second bit ofspecsigflagsuntil it is set to 1 with at least acquire memory ordering. -
Re-read the
invokefield with any memory ordering. This load will be referred to asfinal_invoke. -
Read the
specsigflagsfield with any memory ordering. -
invokeisfinal_invoke,specsigflagsis the value read in step 7,specptris the value read in step 3. -
When updating a
specptrto a different but equivalent function pointer: -
Perform a release store of the new function pointer to
specptr. Races here must be benign, as the old function pointer is required to still be valid, and any new ones are also required to be valid as well. Once a pointer has been written tospecptr, it must always be callable whether or not it is later overwritten.
Correctly reading these fields is implemented in jl_read_codeinst_invoke.
Although these write, read, and update steps are complicated, they ensure that the JIT can update codeinsts without invalidating existing codeinsts, and that the JIT can update codeinsts without invalidating existing invoke pointers. This allows the JIT to potentially reoptimize functions at higher optimization levels in the future, and also will allow the JIT to support concurrent compilation of functions in the future.