Application of deep Q-learning (DQN) to solve a control problem in a discrete environment using the example of the Snake game
In this paper, the agent is trained in the Snake game using the Deep Q-Network (DQN) algorithm. The aim is to demonstrate the use of reinforcement learning methods to solve a control problem in a discrete environment.
The agent (snake) must learn how to collect food, avoiding collisions with walls and his own body. The state of the environment is described by a set of features, and the neural network approximates a Q-function that evaluates the usefulness of each possible action.
In the learning process, the replay memory technique and the target network are used to stabilize convergence. After the training, the trained agent is tested with visualization of the gameplay and analysis of the results obtained.
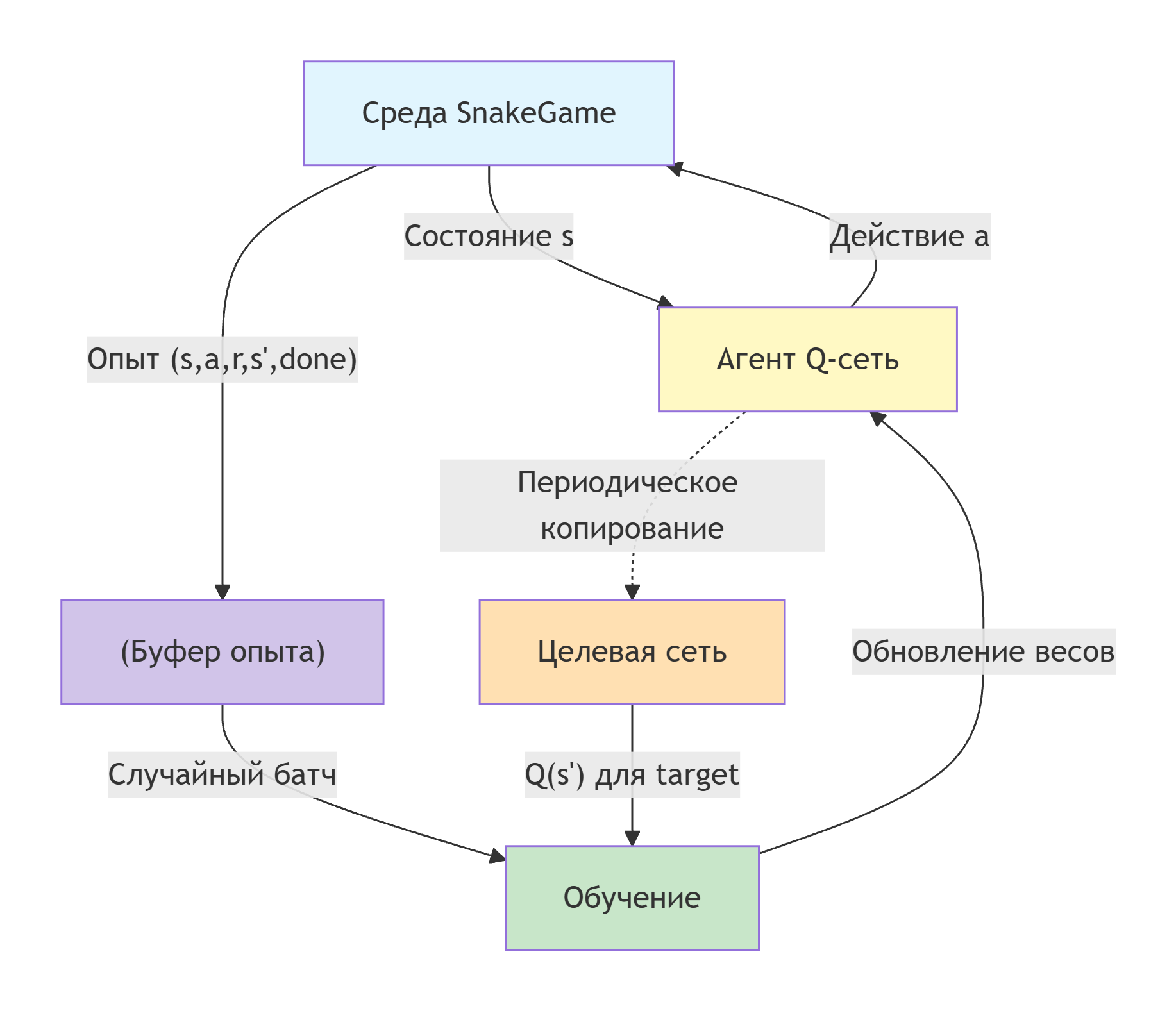
Code description by block
I would like to start this section with a little background.
Snake is a classic arcade game, the essence of which is to control a moving line ("snake") crawling across the playing field. The main goal is to collect the food that appears on the field, increasing the length of the snake, while avoiding collisions with its own tail and the boundaries of the field.
The game originated in the mid-1970s. The first known game of this genre is considered to be the arcade machine Blockade, released by Gremlin Interactive in 1976. In the following years, many variations and clones appeared for various platforms.
The game gained worldwide popularity in 1997, when a Finnish developer Taneli Armanto created a version Snake for mobile phone Nokia 6110 . It was this version that became Nokia's calling card and introduced the game to millions of people around the world, laying the foundations of the mobile entertainment industry.
Now let's take a closer look at the implementation of each component of our algorithm.
using Random
using Statistics
using LinearAlgebra
The structure of the playing field and the logic of the game
mutable struct SnakeGame – Stores game parameters: field size, snake segment coordinates, current direction, food position, score, end of game flag, step counter without food, and last distance to food.
mutable struct SnakeGame
width::Int
height::Int
snake::Vector{Tuple{Int,Int}}
direction::Tuple{Int,Int}
food::Tuple{Int,Int}
score::Int
done::Bool
steps::Int
max_steps::Int
last_dist::Float64
end
Constructor SnakeGame(width, height) – creates a game with an initial snake of three segments in the center of the field, sets the direction to the right, generates the first meal and initializes the service fields.
function SnakeGame(width=25, height=25)
start_x = div(width, 2)
start_y = div(height, 2)
snake = [(start_x, start_y), (start_x-1, start_y), (start_x-2, start_y)]
direction = (1, 0)
game = SnakeGame(width, height, snake, direction, (0,0), 0, false, 0, width*height, 0.0)
spawn_food!(game)
game.last_dist = manhattan_dist(game.snake[1], game.food)
return game
end
manhattan_dist(a, b) = abs(a[1]-b[1]) + abs(a[2]-b[2])
spawn_food! – places food in a random empty cage (not occupied by a snake). If there are no free cells, the game ends with a victory (a flag is set in the code). done).
function spawn_food!(game::SnakeGame)
empty_cells = [(x,y) for x in 2:game.width-1, y in 2:game.height-1
if !((x,y) in game.snake)]
if !isempty(empty_cells)
game.food = rand(empty_cells)
else
game.done = true
end
end
step! – the main step of the simulation:
- Accepts the agent's action: 0 – forward, 1 – turn left, 2 – right (action 3 is reserved as prohibited).
- Calculates the new head position.
- Checks for a collision with a wall or a body – in this case, the game ends, and a -1 penalty is returned.
- If the snake eats the food: the score increases, the step counter resets, new food is generated, and the reward returns +10.
- Otherwise, the tail is removed and the reward for approaching the food is calculated (
dist_reward = ±0.1). A small research bonus is added (0.05 with a 10% probability) and a permanent small penalty of -0.001 to encourage faster solutions. - If the number of steps without food exceeds the maximum, the game ends with a penalty of -0.5.
function step!(game::SnakeGame, action::Int)
game.steps += 1
if action == 1
game.direction = (-game.direction[2], game.direction[1])
elseif action == 2
game.direction = (game.direction[2], -game.direction[1])
end
new_head = (game.snake[1][1] + game.direction[1],
game.snake[1][2] + game.direction[2])
if new_head[1] <= 1 || new_head[1] >= game.width ||
new_head[2] <= 1 || new_head[2] >= game.height ||
new_head in game.snake
game.done = true
return -1.0
end
pushfirst!(game.snake, new_head)
if new_head == game.food
game.score += 1
game.steps = 0
spawn_food!(game)
game.last_dist = manhattan_dist(new_head, game.food)
return 10.0
end
pop!(game.snake)
current_dist = manhattan_dist(new_head, game.food)
dist_reward = sign(game.last_dist - current_dist) * 0.1 # +0.1 closer, -0.1 further
game.last_dist = current_dist
explore_bonus = rand() < 0.1 ? 0.05 : 0.0
if game.steps > game.max_steps
game.done = true
return -0.5
end
return dist_reward + explore_bonus - 0.001
end
get_state – generates a vector of signs of the condition (8 numbers):
- Danger of collision in three directions (forward, left, right) – 0 or 1.
- The direction of food relative to the current direction of the snake (converted to "forward/backward" and "right/left").
- Normalized snake length (
length/50).
is the ratio of the current number of steps to the maximum. - The normalized distance to the tail.
- Normalized snake length (
function get_state(game::SnakeGame)
head = game.snake[1]
forward = game.direction
left = (-game.direction[2], game.direction[1])
right = (game.direction[2], -game.direction[1])
danger_f = is_collision(game, (head[1]+forward[1], head[2]+forward[2])) ? 1.0 : 0.0
danger_l = is_collision(game, (head[1]+left[1], head[2]+left[2])) ? 1.0 : 0.0
danger_r = is_collision(game, (head[1]+right[1], head[2]+right[2])) ? 1.0 : 0.0
dx = sign(game.food[1] - head[1])
dy = sign(game.food[2] - head[2])
if game.direction == (1, 0) # to the right
food_forward = dy == 0 ? 0.0 : (dy > 0 ? -1.0 : 1.0)
food_right = dx > 0 ? 1.0 : (dx < 0 ? -1.0 : 0.0)
elseif game.direction == (-1, 0) # to the left
food_forward = dy == 0 ? 0.0 : (dy > 0 ? -1.0 : 1.0)
food_right = dx < 0 ? 1.0 : (dx > 0 ? -1.0 : 0.0)
elseif game.direction == (0, -1) # up
food_forward = dx == 0 ? 0.0 : (dx > 0 ? 1.0 : -1.0)
food_right = dy < 0 ? 1.0 : (dy > 0 ? -1.0 : 0.0)
else # down
food_forward = dx == 0 ? 0.0 : (dx > 0 ? 1.0 : -1.0)
food_right = dy > 0 ? 1.0 : (dy < 0 ? -1.0 : 0.0)
end
tail_dist = length(game.snake) > 1 ? manhattan_dist(head, game.snake[end]) / (game.width+game.height) : 0.0
return Float64[
danger_f, danger_l, danger_r,
food_forward, food_right,
length(game.snake) / 50.0,
game.steps / game.max_steps, tail_dist]
end
is_collision – checks whether the position is outside the field or occupied by the snake's body.
function is_collision(game::SnakeGame, pos::Tuple{Int,Int})
return pos[1] <= 1 || pos[1] >= game.width ||
pos[2] <= 1 || pos[2] >= game.height ||
pos in game.snake
end
Neural Network Architecture
Our network is implemented as a changeable structure mutable struct QNetwork, which stores the weights and offsets of two fully connected (Dense) layers. This architecture was chosen because the "Snake" task does not require an analysis of raw pixels — a compact feature vector describing the situation on the field is sufficient. Two layers are enough to approximate the Q-function in our discrete environment.
Network structure:
- Input layer — accepts a vector of 8 features, which is formed by the function
get_state(danger in directions, the position of the food relative to the head, the length of the snake, etc.). - Hidden layer — contains 128 neurons with ReLU activation function. This number was chosen as a compromise between computational complexity and the network's ability to memorize fairly complex patterns of behavior.
- The output layer outputs 3 values corresponding to the estimates of Q(s,a) for each possible action: forward, turn left, turn right. The higher the value, the more beneficial the action is considered to be in the current state.
Stored parameters:
W1— the matrix of weights of the first layer in size128×8(links between the input and the hidden layer).b1— displacement vector for the hidden layer (128 values).W2— the matrix of weights of the second layer in size3×128(links between the hidden and output layer).b2— displacement vector for the output layer (3 values).
The weights are initialized using the Xavier method (with a coefficient of sqrt(2/input)), which helps to avoid fading or exploding gradients at the beginning of training. Now let's see how it looks in the code.
mutable struct QNetwork
W1::Matrix{Float64}
b1::Vector{Float64}
W2::Matrix{Float64}
b2::Vector{Float64}
end
Designer QNetwork(input, hidden, output) initializes weights using the Xavier method (with a coefficient of sqrt(2/input)).
function QNetwork(input::Int, hidden::Int, output::Int)
W1 = randn(hidden, input) * sqrt(2.0/input)
b1 = zeros(hidden)
W2 = randn(output, hidden) * sqrt(2.0/hidden)
b2 = zeros(output)
return QNetwork(W1, b1, W2, b2)
end
relu(x) = max.(x, 0.0)
forward – performs a forward pass: input vector s it goes through a linear transformation, ReLU, then a second layer without non-linearity. The output is the Q-values for the three actions.
function forward(q::QNetwork, s::Vector{Float64})
h = relu(q.W1 * s .+ q.b1)
return q.W2 * h .+ q.b2 # Q-values for 3 actions
end
epsilon_greedy – selects an action according to the e-greedy strategy: with probability eps – random action, otherwise an action with the maximum Q-value.
function epsilon_greedy(q::QNetwork, state::Vector{Float64}, eps::Float64)
if rand() < eps
return rand(0:2)
else
q_vals = forward(q, state)
return argmax(q_vals) - 1
end
end
The DQN learning algorithm
Deep Q-Network (DQN) is a reinforcement learning algorithm in which a neural network is used to approximate the utility function Q(s,a). Unlike tabular Q-learning, DQN is able to work with large and continuous state spaces.
The essence of the algorithm: the neural network receives the input state of the environment and outputs Q-values for all possible actions. The choice of action is based on an e-greedy strategy that balances exploration and exploitation.
train_dqn! is the main learning function. Parameters: number of episodes (5000), learning rate (0.001), discount factor γ (0.95).
- Initialized: playback buffer
memory(size 10000), target networktarget_q(copy of the main one), initial ε = 1.0, minimum ε = 0.01, attenuation coefficient ε = 0.995. - For each episode:
- A new game is created, the initial state is obtained.
- The game is not finished yet:
- An action is selected based on an e-greedy policy.
- A step is completed, a reward is obtained, the next state and a completion flag.
- The experience is stored in memory.
- If the memory size is ≥ batch_size (32), a mini-batch is randomly selected and for each transition:
- The current Q-values are calculated
q_current. - The Q-values of the next state from the target network are obtained
q_next. - The target value is generated using the formula:
target = r + γ * max(q_next)if the state is not terminal, otherwisetarget = r. - Gradient descent is performed using error backpropagation (manual calculation of gradients).
- The current Q-values are calculated
- Transition to the next state.
- At the end of the episode, the score is recorded in the array
scores, updated daily. - Every 100 episodes, the target network is updated (copying scales).
- Every 500 episodes, the average score for the last 500 episodes is displayed.
- The function returns an array of points scored by episode.
- The game is not finished yet:
function train_dqn!(q::QNetwork, episodes=5000, lr=0.001, gamma=0.9)
scores = Int[]
memory = Tuple{Vector{Float64}, Int, Float64, Vector{Float64}, Bool}[]
batch_size = 32
memory_size = 10000
eps_start = 1.0
eps_end = 0.01
eps_decay = 0.995
target_q = QNetwork(8, 128, 3)
target_q.W1 .= q.W1; target_q.b1 .= q.b1
target_q.W2 .= q.W2; target_q.b2 .= q.b2
eps = eps_start
for episode in 1:episodes
game = SnakeGame()
state = get_state(game)
total_reward = 0.0
while !game.done
action = epsilon_greedy(q, state, eps)
reward = step!(game, action)
next_state = get_state(game)
done = game.done
push!(memory, (state, action, reward, next_state, done))
if length(memory) > memory_size
popfirst!(memory)
end
total_reward += reward
state = next_state
if length(memory) >= batch_size
batch = rand(memory, batch_size)
for (s, a, r, s_next, d) in batch
q_current = forward(q, s)
q_next = forward(target_q, s_next)
target = copy(q_current)
if d
target[a+1] = r
else
target[a+1] = r + gamma * maximum(q_next)
end
h = relu(q.W1 * s .+ q.b1)
q_val = q.W2 * h .+ q.b2
error = q_val - target
dW2 = error * h'
db2 = error
dh = q.W2' * error
dh[h .<= 0] .= 0
dW1 = dh * s'
db1 = dh
q.W1 .-= lr * dW1
q.b1 .-= lr * db1
q.W2 .-= lr * dW2
q.b2 .-= lr * db2
end
end
end
push!(scores, game.score)
eps = max(eps_end, eps * eps_decay)
if episode % 100 == 0
target_q.W1 .= q.W1; target_q.b1 .= q.b1
target_q.W2 .= q.W2; target_q.b2 .= q.b2
end
if episode % 500 == 0
recent = scores[max(1, end-499):end]
println("Episode $episode, Mean: $(round(mean(recent), digits=2)), Max: $(maximum(recent)), Eps: $(round(eps, digits=3))")
end
end
return scores
end
Visualization of the game
draw_game – creates a matrix grid, where each pixel corresponds to a color for display.
function draw_game(game::SnakeGame)
grid = fill(0.5, game.height, game.width)
grid[1, :] .= 0.0
grid[end, :] .= 0.0
grid[:, 1] .= 0.0
grid[:, end] .= 0.0
for (i, (x, y)) in enumerate(game.snake)
if i == 1
grid[y, x] = 1.0
else
grid[y, x] = 0.8 - (i/length(game.snake))*0.3
end
end
grid[game.food[2], game.food[1]] = 0.2
return grid
end
play_and_record – runs the game under the control of a trained network (ε = 0) and saves the animation to a GIF. At each step, a heat map is built using heatmap from Plots. The frames are collected, then an animated GIF is created at the specified frame rate. The function returns the total score.
function play_and_record(q::QNetwork, filename="snake_dqn.gif"; fps=10)
game = SnakeGame()
frames = []
while !game.done && length(frames) < 500
grid = draw_game(game)
p = heatmap(grid,
color=:viridis,
aspect_ratio=:equal,
axis=false,
colorbar=false,
title="Score: $(game.score) | Steps: $(game.steps)",
size=(600, 600),
clim=(0, 1))
push!(frames, p)
state = get_state(game)
action = epsilon_greedy(q, state, 0.0)
step!(game, action)
end
grid = draw_game(game)
p = heatmap(grid,
color=:viridis,
aspect_ratio=:equal,
axis=false,
colorbar=false,
title="FINAL Score: $(game.score)",
size=(600, 600),
clim=(0, 1))
push!(frames, p)
anim = @animate for f in frames
plot(f)
end
gif(anim, filename, fps=fps)
println("Saved: $filename | Score: $(game.score) | Frames: $(length(frames))")
return game.score
end
Launching and analyzing the results
In conclusion:
- A Q-network instance is created with an input size of 8, a hidden layer of 128, and an output of 3.
- Training is called for 5000 episodes.
- After learning, a test game starts with saving GIFs (
snake_dqn.gif). - The final statistics are displayed: the final score, the maximum tuition bill, the average score for the last 1000 episodes.
- A graph of changes in the score by episode and its smoothed (moving average with a window of 100) curve is plotted, saved to a file
training.png.
println("Initializing DQN...")
@time q_net = QNetwork(8, 128, 3)
println("Training...")
@time scores = train_dqn!(q_net, 5000, 0.001, 0.95)
println("\nTesting...")
@time final_score = play_and_record(q_net, "snake_dqn.gif")
println("\nResults: Final=$final_score, MaxTrain=$(maximum(scores)), MeanLast1000=$(mean(scores[max(1,end-999):end]))")
p = plot(scores, xlabel="Episode", ylabel="Score", title="DQN Training", legend=false, alpha=0.3)
function moving_average(v, n)
return [mean(v[max(1,i-n+1):i]) for i in 1:length(v)]
end
plot!(moving_average(scores, 100), linewidth=2, color=:red)
savefig(p, "training.png")
display(p)
During the training, there was an increase in the average score:
- By episode 500, the average score was ~1.48, and the maximum score was 9.
- By episode 1000, the average score increased to ~9.55, and the maximum score was 41.
– Further, the average score stabilized around 13-15, periodically reaching highs of 41 (and even 43 during training).
Final testing showed the score 26 with a trajectory length of 501 steps, this indicates that the agent has learned how to collect food and avoid collisions, although it has not reached the theoretical maximum (all 625 cells). Maximum training score 43 It confirms the agent's ability to sometimes play very long games, and the average score over the last 1,000 episodes (13.64) indicates a consistently good, but not outstanding level of play.

Conclusion
The developed DQN implementation for the Snake game has successfully trained an agent capable of collecting food and avoiding obstacles. The use of replay memory and target network allowed us to stabilize training. An analysis of the results shows that the agent's average score increased from zero to ~15 points per 5,000 episodes, and the maximum reached 48. The visualization on the GIF demonstrates the intelligent behavior of a trained snake. The proposed architecture can be improved, for example, by increasing the size of the network, adding convolutional layers for processing the visual state, or using more advanced methods (Double DQN, Dueling DQN). In general, the project serves as a clear illustration of the application of deep learning methods with reinforcement to a discrete control task.